

Oggi, il progresso tecnologico ci permette di godere di ottime condizioni di vita. Il controllo dello spazio, il controllo della riproduzione, il controllo delle informazioni sono sfide che abbiamo già realizzato. Tuttavia, il controllo del tempo rimane fuori portata. Molte ossessioni umane ruotano attorno al potere di questa risorsa, offertaci alla nascita in una quantità disperatamente finita: il tempo. Rimanere giovani, vivere a lungo, perpetuare la memoria, prevedere il futuro sono alcune delle forme che assume questa ossessione. Questo rifiuto di una realtà biologica sembra rispondere a una regola misteriosa che gli scienziati non possono spiegare. La trasformazione digitale delle nostre vite offre un’opportunità per risolvere uno di questi problemi: anticipare il futuro. Questo è ciò che vorrei che tu prendessi in considerazione in questo articolo.
In questo articolo, ho strutturato la mia presentazione intorno a tre linee guida. Prima di tutto, mostrerò che la previsione è una pratica vecchia e che la digitalizzazione delle nostre vite ci offre un’opportunità unica per prevedere il futuro. Evidenzierò, quindi, i limiti concettuali dell’analisi dei Big Data. Infine, proporrò un piano d’azione per integrare i Big Data in un approccio di marketing e studio comportamentale. Questo approccio incorporerà tecniche di ricerca di mercato tradizionali.
Nota: questo articolo è un riferimento alla mia presentazione del 6 dicembre 2019, al congresso annuale dell’Associazione Belga di Marketing (vedi presentazione sotto).
Sommario
- Prevedere il futuro: un’ossessione costante in ogni momento
Dati per previsioni migliori
Una vita sempre più digitale
La tensione tra marketing qualitativo e marketing quantitativo
Le tre debolezze metodologiche dei Big Data - Come utilizzare i Big Data per un marketing significativo
- Fonti
Predire il futuro: un’antica ossessione

Prevedere il futuro è un’attività quotidiana fin dall’inizio dei tempi. L’obiettivo della previsione è, ovviamente, influenzare il corso del tempo per ottenere un beneficio collettivo o individuale: migliori raccolti, più ricchezza, la perpetuazione del nome attraverso la discendenza. Gli esseri umani sembrano avere un problema con l’incertezza. Hanno, quindi, sempre cercato di rassicurarsi: oracoli al servizio del faraone nell’antico Egitto, presagi di ogni forma di potere nell’antica Roma.
Questa tradizione di divinazione e predizione del futuro continua oggi su una scala mai vista prima con gli oroscopi. Il 12% degli americani legge l’oroscopo ogni giorno, il 32% occasionalmente e il 26% crede nell’astrologia. La necessità di conoscere il futuro si adatta a ogni tempo ea ogni cultura. Tuttavia, i risultati, come converrete, rimangono incerti.
Il 26% degli americani crede nell’astrologia
Tuttavia, la tecnologia consente di anticipare il futuro meglio che mai. La rivoluzione dei Big Data, combinata con capacità di archiviazione e calcolo sempre più economiche, rende l’elaborazione delle informazioni più accessibile e la comprensione dei fenomeni naturali e umani migliore che mai. Già nel 2003 si stimava che, in 20 anni, i progressi tecnologici avessero risparmiato, in media, due giorni sulle previsioni del tempo. Man mano che i dati si accumulano, è ragionevole presumere che le previsioni possano solo migliorare.

Moltiplicazione dei dati per previsioni migliori
A rischio di ripetere cifre già note, proviamo a capire le conseguenze della digitalizzazione delle nostre vite in poche statistiche:
- Il volume totale dei dati disponibili sarebbe di 40 Zb, che corrisponde a quarantamila miliardi di Gigabyte. Ecco cosa rappresenta in numeri: 40.000.000.000.000.000.000 Gb.
- Nel 2017, il 90% dei dati era stato creato nei due anni precedenti
- Il 57% degli esseri umani ha accesso a Internet (in aumento del 9,9% rispetto al 2018) e, ogni giorno, vengono generati 2,5 quintilioni di byte su InternetIl 33% del tempo trascorso su Internet è sui social media
- Il numero di oggetti connessi sarà moltiplicato per 3 nei prossimi sei anni
 entre 2015 et 2025")
Il volume dei dati a disposizione non potrà, quindi, che aumentare, documentando un po’ di più ogni interazione umana e rivelando un po’ di più ogni angolo dei nostri comportamenti. Con così tanti dati, diventa chiaro che le nostre azioni possono essere sempre più sezionate, confrontate e, naturalmente, previste.
I social media rappresentano il 33% del tempo trascorso su Internet
Una vita sempre più digitale, una manna dal cielo per i marketer
Le nostre vite sono sempre più digitali e il marketing moderno, nella sua ricerca di significatività, vede i dati come una terra promessa, un paradiso che gli permetterà di realizzare il suo sogno del passato, quello di un rapporto uno a uno con ciascuno dei clienti.

Come nella corsa all’oro in California del 19° secolo, coloro che sono diventati ricchi non erano necessariamente quelli che credevamo. Sostituisci le pepite d’oro con i dati (“il nuovo petrolio”), sostituisci i negozi generici con fornitori di soluzioni cloud e ottieni un interessante parallelo per guardare al fenomeno dei Big Data da una nuova prospettiva.
 lors de la ruée vers l'or en Californie au XIXème siècle")
La promessa di un comportamento completamente digitalizzato consente al marketing di cambiare. Dalle scienze sociali (una scienza “soft”, come la chiamano i francesi), il marketing si adorna di fronzoli statistici e matematici e inizia una trasformazione che, si spera, gli permetterà di trasformarsi in hard science. Il bruco sogna di diventare un futuro farfalla.
Tuttavia, dobbiamo mettere in dubbio la rilevanza di questa transizione a tutti i dati. Il marketing, come scienza incentrata sulla comprensione e la soddisfazione delle esigenze dei clienti, può essere guidato dai dati?
Tensione di fondo tra ricerca qualitativa e ricerca quantitativa
Questa domanda riflette la tensione che esiste da decenni tra ricerca qualitativa e ricerca quantitativa. Il secondo dice al primo che il quantitativo è di per sé sufficiente, mentre il primo ribatte che la comprensione del comportamento può essere raggiunta solo attraverso la ricerca qualitativa. Questa infruttuosa opposizione ha dato origine a tentativi di mediazione sotto forma, ad esempio, del concetto di “thick data”. Thick data” è la risposta agli scettici e promette di aumentare la rilevanza dei risultati dei Big Data attraverso le intuizioni della ricerca qualitativa (vedi Latzko-Toth et al., 2017).
Come sottolinea Thompson (2019), il – mito dei Big Data è qualitativamente diverso dalla sua controparte quantitativa über alles (traduzione libera dall’inglese). Nel XX secolo, le tecniche quantitative sono state brandite come metodi positivisti per sfuggire alla natura casuale e intuitiva delle tecniche qualitative. Oggi, i Big Data rafforzano questa visione empirica aggiungendo tecno utopia (Thompson 2019). Questa visione pone i Big Data come unica risposta, rifiutando, così, la legittimità di altri approcci.
I thick data sono una proposta per aumentare la rilevanza dei risultati dei Big Data attraverso approfondimenti dalla ricerca qualitativa.
Questo discorso radicale ci costringe a esplorarne i limiti in modo che l’analisi della traccia digitale possa essere utilizzata nel miglior modo possibile. Ti propongo di esaminare tre aree di tensione che ci permetteranno di mettere in discussione il posto esatto dei Big Data nell’analisi del comportamento umano.

Debolezza N°1: la differenza tra attività online e comportamento offline
Il mito dei Big Data si basa su un presupposto fallace: i nostri comportamenti online rifletterebbero il nostro comportamento nel mondo reale. La nostra attività sui social media è semplicemente vista come un modo diverso per esprimere e condividere le nostre preferenze.
Personalità e comportamento online
Gli studi sono ormai una legione che stabilisce una correlazione tra attività online e personalità. “Kosinski et al. (2015)”, ad esempio, ha mostrato che i siti web visitati e gli eventi su Facebook hanno permesso di dedurre la personalità dell’utente di Internet. “Youyou et al. (2015)” ha fatto un passo avanti affermando che la valutazione della personalità basata sull’attività di Facebook era più accurata di quella fatta dagli esseri umani. Quest’ultimo articolo ha avuto un impatto decisivo sulla stampa pubblica in generale, la quale ha subito dichiarato che Facebook intendeva i suoi utenti come la propria famiglia. Mentre la mia attività online può rivelare i tratti della personalità, non raccontano tutto di me. La personalità è solo una parte di ciò che costituisce un essere umano. Tutto ciò ci porta ad esaminare la 2° area di tensione: le differenze tra l’io digitale e chi sono.
Messa in scena e drammatizzazione online
C’è una differenza tra la mia controparte digitale e chi sono io; i miei comportamenti online non riflettono necessariamente la mia realtà. Internet consente libertà di tono, immediatezza di reazione, reazioni a catena, che sono assenti nelle relazioni interpersonali nel mondo reale. Ci lasciamo trasportare da Internet per argomenti che sono innocui nella vita reale. Cerchiamo di farci piacere, in una ricerca di reciprocità che non dice nulla sui nostri interessi profondi. Inoltre, stiamo parlando dei nostri profondi interessi sui social, sui forum, su Internet in generale? Non esiste una forma di restrizione digitale che ci spinga a non dire nulla su ciò che è importante per noi (a rischio di essere giudicati). Questo ci porta a seguire l’opinione generale, a far parte di una grande tribù digitale e ad affermare, così, la nostra appartenenza a un movimento collettivo. Non bisogna neanche perdere di vista il fatto che, la stragrande maggioranza degli utenti, consuma passivamente contenuti sui social media e che una piccola minoranza li produce.
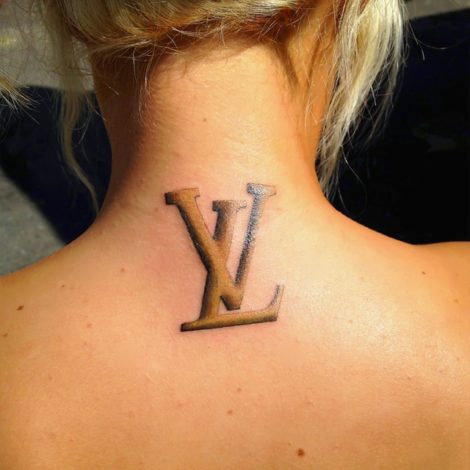 La ricerca del senso del marketing richiede anche il riconoscimento che, il significato dato agli atti online, non è necessariamente quello che pensi che sia. Infatti, teniamo presente che l’attività online è anche una proiezione narcisistica di un sé digitale ideale. La messa in scena fotografica sui social, la drammatizzazione di oggetti e brand in composizioni grafiche pensate per suscitare gelosie, sono solo la parte emergente di questo fenomeno. Ad esempio, possiamo immaginare che il logo di un marchio possa diventare una decorazione del corpo in una modalità in cui il digital staging sarebbe assente?
La ricerca del senso del marketing richiede anche il riconoscimento che, il significato dato agli atti online, non è necessariamente quello che pensi che sia. Infatti, teniamo presente che l’attività online è anche una proiezione narcisistica di un sé digitale ideale. La messa in scena fotografica sui social, la drammatizzazione di oggetti e brand in composizioni grafiche pensate per suscitare gelosie, sono solo la parte emergente di questo fenomeno. Ad esempio, possiamo immaginare che il logo di un marchio possa diventare una decorazione del corpo in una modalità in cui il digital staging sarebbe assente?
L’artista belga Wim Delvoye si è beffato di questa tendenza adornando i maiali con i loghi di marchi di lusso (qui Vuitton). Lo ha fatto tramite un gesto artistico che si prende gioco di una curiosa tendenza umana volta a volersi differenziare? Il significato culturale del logo è cambiato e, con esso, l’appropriazione da parte delle masse.

Differenze tra attività online e offline
Facciamo un esempio aneddotico: il mio. Ho diverse passioni (tra cui la pittura e la mineralogia) di cui non parlo sui social. Parlo di poco in termini generali. Tutti conoscono la regola dell’1%, che divide i partecipanti a Internet in due categorie: coloro che partecipano attivamente attraverso la creazione di contenuti (1%) e i consumatori passivi (99%). Mantengo le mie passioni in modo prevalentemente passivo (mediante la lettura) e sarebbe, quindi, necessario avere accesso alla mia cronologia di navigazione per farvelo conoscere. Probabilmente i cookie di seconda parte possono fornire qui un’immagine frammentata di chi sono. Alla fine, le passioni che mi hanno portato a seguire alcune pagine su Facebook sono aneddotiche rispetto al resto. Quindi, c’è un divario tra il mio io online e il mio vero io.
Ricordiamo inoltre che oltre l’80% degli acquisti è offline. Lo snodo tra offline e online resta una sfida importante per il settore retail di domani (vedi l’articolo sui trend del retail).
Il mito dei Big Data basato sulla scomposizione dell’essenza dell’individuo in particelle elementari composte da 0 e 1
Debolezza N°2: differenze tra previsione e comprensione
L’individuo può essere ridotto ai propri dati?
Ecco un altro inganno introdotto dai “Big Data”. Poiché l’individuo lascia tracce digitali che darebbero un’immagine precisa del suo essere, questi dati nascondono il mistero dei comportamenti futuri. L’analisi di dati sempre più grandi consentirebbe, quindi, di prevedere il comportamento in modo più accurato. L’individuo si assimilava, conseguentemente alla monade di Leibniz, a particelle elementari composte da 0 e 1 che conterrebbero la sua essenza. Perché è di questo che si tratta. Al di là della personalità (di cui abbiamo visto sopra che un’analisi attendibile era possibile dalle tracce digitali lasciate, ad esempio, sui social network), i Big Data promettono una comprensione dell’essenza dell’individuo. Questa proposta è fuorviante perché la caratteristica dell’individuo è la sua imprevedibilità. Come ha sottolineato Dominique Cardon, gli errori di previsione sono in definitiva solo incidenti statistici. La falsa promessa basata su una proposta che il mio amico, dottor Emmanuel Tourpe così descriveva: – la persona è sostituita dall’individuo digitale e la comunità dalla generalità statistica.
La persona è sostituita dall’individuo digitale e la comunità dalla generalità statistica
Dr. Emmanuel Tourpe, ARTE
Capire l’essere umano: un sogno inaccessibile
Non cadiamo in critiche eccessive ai Big Data. La digitalizzazione della nostra vita permette un livello di analisi dei nostri comportamenti che non ha eguali. Laddove Charles Booth ha impiegato anni di lavoro per raccogliere dati sugli abitanti di una città (Londra), ora bastano pochi minuti per ottenere volumi di dati molto più granulari a livello nazionale. Osservare il comportamento non è mai stato più semplice. Ma siamo più che semplici osservatori di una realtà che ci sfugge? I venditori di Big Data si assicureranno che tu possa toccare la verità intima del comportamento umano, utilizzare i dati per prevedere il comportamento futuro. Se alcune reazioni possono davvero essere previste, è necessario rimanere umili. Primo, la previsione può essere fatta solo con una precisione limitata, una parte sconosciuta della complessità del comportamento umano. In secondo luogo, i dati vanno presi solo per quello che sono, cioè come testimoni esterni di una realtà che resta misteriosa. Quando “analizziamo” i Big Data, siamo solo etnografi, esploratori che si fanno strada attraverso una foresta di dati di cui non sappiamo nulla, in teoria. La capacità di prevedere il comportamento, resa possibile dai moderni metodi computazionali, non ci permette di pensare di comprendere il comportamento umano. Questi rimangono principalmente impenetrabili, come mostrato nell’esempio seguente.
Un’illustrazione concreta della discrepanza tra previsione e comprensione
Facciamo un esempio concreto per illustrare il mio punto: lo smartphone che ho comprato qualche settimana fa. Le tracce digitali lasciate visitando diversi siti ti avrebbero portato a prevedere il mio interesse per l’acquisto di un nuovo smartphone, le parole chiave utilizzate per la mia ricerca ti avrebbero anche permesso di concludere quali modelli preferivo. Ma alla fine cosa è successo? Ho acquistato lo smartphone dopo una visita al negozio. L’atto dell’acquisto, dunque, sfugge a ogni tentativo di conciliazione (ricordiamo che oltre l’80% degli acquisti è offline). E soprattutto, anche se si poteva prevedere che la mia scelta sarebbe stata l’uno o l’altro modello, il meccanismo decisionale rimarrà sconosciuto: perché ho deciso di cambiare smartphone? Quali argomenti mi hanno spinto a scegliere un modello piuttosto che un altro?
 Questa conoscenza dei meccanismi decisionali rimane essenziale per prendere decisioni strategiche e migliorare il marketing. Osservare semplicemente i comportamenti, superficialmente, senza cercare di capire come funzionano, ti priva di leve di azione per un marketing migliore, marketing che abbia senso. Come potresti convincere il consumatore che vedi, in base alle sue tracce digitali, esitare se non hai gli argomenti che risuoneranno in lui?Per acquisire questa finezza di comprensione, credo che si debbano utilizzare altri approcci metodologici (indagini quantitative, indagini qualitative).
Questa conoscenza dei meccanismi decisionali rimane essenziale per prendere decisioni strategiche e migliorare il marketing. Osservare semplicemente i comportamenti, superficialmente, senza cercare di capire come funzionano, ti priva di leve di azione per un marketing migliore, marketing che abbia senso. Come potresti convincere il consumatore che vedi, in base alle sue tracce digitali, esitare se non hai gli argomenti che risuoneranno in lui?Per acquisire questa finezza di comprensione, credo che si debbano utilizzare altri approcci metodologici (indagini quantitative, indagini qualitative).
Debolezza N°3: differenza tra cause e correlazioni
L’ultima tensione che dobbiamo affrontare è quella che deriva dalla mancata comprensione dei dati analizzati. I Big Data promettono di trovare correlazioni tra dati sparsi troppo numerosi per essere esaminati da un essere umano. Grazie ai Big Data, ogni individuo è oggetto di uno specifico modello di analisi; questo è un cambiamento fondamentale nella realtà econometrica che ha prevalso fino ad ora. Questo ci richiede di spiegare come sono state fatte le “previsioni” in passato.
Modellazione comportamentale in econometria
Prima dei Big Data, la previsione del comportamento era basata sulla modellazione di massa: un insieme sufficientemente ampio di individui presi e ipotesi fatte, sui fattori che hanno influenzato il comportamento in generale e la rilevanza del modello testato rispetto a questi dati. Ciò ha portato a un modello di previsione valido per un gran numero di individui. Questi modelli erano necessariamente imperfetti poiché gli individui hanno comportamenti diversi tra loro e la parte “prevedibile” è, quindi, solo la parte comune a tutti. Tuttavia, questi modelli sono stati utili a causa della ricerca di fattori che influenzano il comportamento basata su una ricerca bibliografica preliminare e spiegazioni comportamentali del ruolo di ciascuna variabile.
I Big Data fanno di ogni individuo un modello a sé stante
Con i Big Data la situazione è ben diversa. Non c’è più alcun modello preconcetto, né alcun tentativo di generalizzazione. Ogni individuo diventa un modello di sé stesso, le loro tracce digitali analizzate in modo tale da far emergere correlazioni che serviranno a predire il futuro. La correlazione cessa di essere una fonte di interrogazione e comprensione del comportamento, è solo una relazione matematica tra due variabili di cui, a volte, non sappiamo nulla. Le variabili non sono più fonte di interrogativi sulla logica del comportamento, ma sono solo tracce superficiali il cui significato ci sfugge, interpretato come un segno matematico senza senso, nel disperato tentativo di far emergere la verità. I risultati a volte sono divertenti. Tyler Vigen ha raccolto, in un libro, una correlazione vicina alla perfezione matematica ma priva di significato. Il suo sito, Spurious Correlations, espone alcune di queste aberrazioni che potrebbero passare inosservate nell’elaborazione tradizionale dei Big Data.
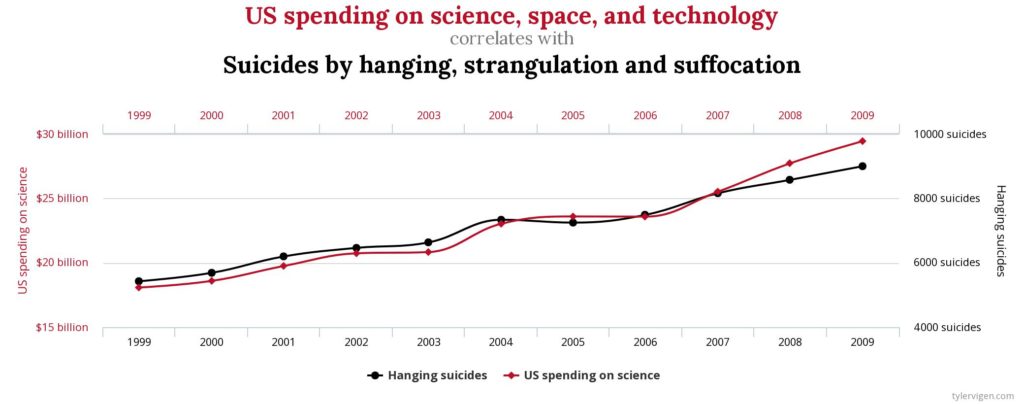
L’esempio precedente permette di identificare la discrepanza tra due realtà molto diverse: la correlazione matematica, da un lato, e causa ed effetto, dall’altro. La correlazione non spiega necessariamente la causa e l’effetto. Peggio ancora, questo problema diventa secondario nei Big Data poiché ci viene promesso di rivelare una verità che ci sfugge grazie alle correlazioni matematiche.
Come possiamo trovare una dose di buon senso nel trattamento dei Big Data? Questo è l’argomento dell’ultima parte di questo articolo in cui mi interrogo sulle tecniche di marketing da combinare per migliorare l’analisi dei comportamenti.
Vantaggi e svantaggi dell’analisi dei Big Data per scopi di marketing
Vantaggi
- Evidenziare i comportamenti in un’ampia varietà di contesti
- Determinazione della personalità dell’utente
Svantaggi
- I comportamenti online non sono necessariamente la trasposizione dei nostri comportamenti offline
- I dati sono solo una traccia superficiale e non ci permettono di comprendere le ragioni dei comportamenti
- Le correlazioni matematiche non spiegano la causa e l’effetto
Roadmap suggerita per l’utilizzo dei big data in un approccio di marketing sensato
Iniziamo riassumendo i vantaggi e gli svantaggi dell’utilizzo dei Big Data prima di delineare un piano d’azione per comprendere meglio il comportamento delle persone.
Vantaggi
Le tracce digitali lasciate dalle nostre attività digitali ci permettono di fare luce in profondità su alcuni nostri comportamenti. Sono i testimoni della nostra vita digitale e il riflesso di alcuni tratti della nostra personalità.
Svantaggi
Le tracce digitali sono solo una parte della nostra attività. I nostri comportamenti online non sono estensioni digitali del mondo offline. L’interpretazione dei dati può, quindi, essere fatta solo tenendo presente la presenza di questo specchio deformante. Inoltre, una traccia digitale è solo l’impronta superficiale di un comportamento che deve essere compreso se l’azienda vuole avere presa sul cliente. Analizzare le tracce senza comprendere il motivo del percorso del cliente significa rimuovere tutto il significato dalle azioni di marketing che ne derivano. Per evitare di cadere in previsioni matematiche prive di significato, dobbiamo, quindi, concentrarci su causa ed effetto. Quali ragioni hanno spinto l’individuo a fare questo o quello, che lo hanno portato a lasciare questa o quella traccia?
Un piano d’azione per un migliore utilizzo dei dati per scopi di marketing
Come prendere due piccioni con una fava? In che modo i Big Data possono essere utilizzati al massimo delle loro potenzialità senza compromettere l’analisi dai problemi evidenziati sopra?
Il marketing di domani può essere concepito, secondo me, solo attraverso una combinazione di tecniche, da un lato, e un approccio iterativo, dall’altro. La tecnologia influenza inevitabilmente i nostri comportamenti (tensione n°1) e comprendere la natura mutevole delle nostre routine richiede necessariamente la costante revisione dei modelli esistenti. Il lavoro del marketer è, quindi, un loop infinito composto dai seguenti elementi:
- Studio dell’esistente: cosa si sa già del comportamento da studiare? Esistono modelli in grado di identificare i fattori che influenzano il comportamento?
- Analisi dei dati utilizzando modelli esistenti: i dati che ho raccolto confermano i modelli esistenti e, in caso affermativo, in che proporzione? È a questo livello che vanno esplorati i dati esistenti (business intelligence)
- Analisi dei “buchi” nel modello: come spiegare la parte di comportamento che non riesco a risolvere sulla base dei dati esistenti? In questa fase dobbiamo porci due domande: la prima, sui fattori influenti ancora sconosciuti; in secondo luogo, sulla significatività dei fattori di influenza presi in considerazione nel modello. Questo è il momento della ricerca qualitativa che mira ad approfondire i comportamenti e dare significato alle azioni.
- Raccolta dei dati mancanti: quali azioni dovrebbero essere intraprese per raccogliere i dati mancanti e perfezionarli? Questa è una riflessione “aziendale” che dovrebbe portare all’acquisizione dei dati mancanti.
Questo ciclo è destinato a ripetersi. Il lavoro del marketer diventa, così, un eterno riavvio.
Qualche domanda, commento? Sentiti libero di contattarmi o invitarmi a fare questa presentazione al tuo pubblico.
Fonti
- Les échos
- EMC
- Statista
- Kosinski, M., Bachrach, Y., Kohli, P., Stillwell, D., & Graepel, T. (2014). Manifestations of user personality in website choice and behaviour on online social networks. Machine learning, 95(3), 357-380.
- Latzko-Toth, G., Bonneau, C., & Millette, M. (2017). Small data, thick data: Thickening strategies for trace-based social media research. The SAGE handbook of social media research methods, 199-214.
- Thompson, C. J. (2019). The ‘big data’myth and the pitfalls of ‘thick data’opportunism: on the need for a different ontology of markets and consumption. Journal of Marketing Management, 35(3-4), 207-230.
- Youyou, W., Kosinski, M., & Stillwell, D. (2015). Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4), 1036-1040.
Illustration images: shutterstock, Canadahistory

![Illustrazione del nostro articolo "Rilevatori di IA generativa gratuiti: quali scegliere? [Test completo 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)


