

Technological progress today allows us to enjoy excellent living conditions. Control of space, control of reproduction, control of information are challenges that we have already accomplished. However, time control remains out of reach. Many human obsessions revolve around the power of this resource, offered to us at birth in a desperately finite quantity: time. Staying young, living old, perpetuating your memory, predicting the future are some of the forms that this obsession takes. This refusal of a biological reality seems to answer a mysterious rule that scientists cannot explain. The digital transformation of our lives offers an opportunity to solve one of these problems: anticipating the future. This is what I would like you to consider in this article.
In this article, I have structured my presentation around three guidelines. First of all, I will show that prediction is an old practice and that the digitisation of our lives offers us a unique opportunity to predict the future. I will then highlight the conceptual limitations of Big Data analysis. Finally, I will propose an action plan to integrate Big Data into a marketing and behavioural study approach. This approach will incorporate traditional market research techniques.
Note: this article is a reference to my presentation on December 6, 2019, at the annual congress of the Belgian Association of Marketing (see presentation below).
Summary
- Predicting the future: a constant obsession at all times
- Data for better predictions
- An increasingly digital life
- The tension between qualitative marketing and quantitative marketing
- The three methodological weaknesses of Big Data
- How to use Big Data for meaningful marketing
- Sources
Predicting the future an ancient obsession

Predicting the future has been a daily activity since the beginning of time. The objective of prediction is, of course, to influence the course of time to obtain a collective or individual benefit: better harvests, more wealth, the perpetuation of the name through descent. Human beings seem to have a problem with uncertainty. They have, therefore, always sought to reassure themselves: oracles in the service of the pharaoh in ancient Egypt, omens of all forms of power in ancient Rome.
This tradition of divination and prediction of the future continues today on a scale never seen before with horoscopes. 12% of Americans read their horoscopes daily, 32% occasionally and 26% believe in astrology. The need to know the future is adapted to each time and each culture. However, the results, as you will agree, remain uncertain.
26% of Americans believe in astrology
Nevertheless, technology makes it possible to anticipate the future better than ever. The Big Data revolution, combined with ever-cheaper storage and computing capabilities, makes information processing more affordable and the understanding of natural and human phenomena better than ever. As early as 2003, it was estimated that in 20 years, technological advances had saved two days on average on weather forecasts. As data accumulates, it is reasonable to assume that predictions can only improve.

Data multiplication for better predictions
At the risk of repeating figures already known, let’s try to understand the consequences of the digitalisation of our lives in a few statistics:
- The total volume of available data would be 40 Zb, which corresponds to forty thousand billion Gigabytes. Here is what this represents in numbers: 40,000,000,000,000,000,000 Gb.
- In 2017, 90% of the data had been created within the previous two years
- 57% of humans have access to the Internet (up 9.9% from 2018), and 2.5 quintillion bytes are generated every day on the Internet
- 33% of the time spent on the Internet is on social media
- The number of connected objects will be multiplied by 3 in the next six years
 entre 2015 et 2025")
The volume of data available will therefore only increase, documenting a little more each human interaction, and revealing a little more of every corner of our behaviours. With so much data, it becomes clear that our actions can be increasingly dissected, compared and of course, predicted.
Social media represents 33% of the time spent on the Internet
An increasingly digital life, a godsend for marketers
Our lives are increasingly digital and modern marketing, in its quest for meaningfulness, sees data as a promised land, a paradise that will allow it to realise its dream of the past, that of a one-to-one relationship with each of the company’s customers.

As in the California gold rush of the 19th century, those who became rich were not necessarily those we believed. Replace gold nuggets with data (“the new oil”), replace general stores with cloud solution vendors, and you get an exciting parallel to look at the Big Data phenomenon from a new angle.
 lors de la ruée vers l'or en Californie au XIXème siècle")
The promise of completely digitised behaviour allows marketing to change. From social science (a “soft” science as the French call it) marketing is adorned with statistical and mathematical finery, and begins a transformation which, it hopes, will allow it to transform itself into hard science. The caterpillar is dreaming of becoming a butterfly future.
However, we must question the relevance of this transition to all-data. Can marketing as a science focused on understanding and satisfying customer needs be data-driven?
Underlying tension between qualitative research and quantitative research
This question reflects the tension that has existed for decades between qualitative research and quantitative research. The latter tells the former that the quantitative is sufficient in itself, while the former retorts that understanding behaviour can only be achieved through qualitative research. This fruitless opposition gave rise to attempts at mediation in the form of, for example, the concept of “thick data”. Thick data” is the response to sceptics that promises to increase the relevance of Big Data results through insights from qualitative research (see Latzko-Toth et al., 2017).
As Thompson (2019) points out, the “myth of Big Data is qualitatively different from its quantitative counterpart über alles” (free translation from English). In the 20th century, quantitative techniques were brandished as positivist methods to escape the random and intuitive nature of qualitative techniques. Today, Big Data reinforces this empirical vision by adding technotopian (Thompson 2019). This vision places Big Data as the only answer, thus rejecting the legitimacy of other approaches.
Thick data is a proposal to increase the relevance of Big Data results through insights from qualitative research.
This radical discourse forces us to explore its limits so that digital trace analysis can be used in the best possible way. I propose that you examine three areas of tension that will allow us to question the exact place of Big Data in the analysis of human behaviour.

Weakness N°1: the difference between online activities and offline behaviour
The myth of Big Data is based on a fallacious assumption: our online behaviours would reflect our behaviour in the real world. Our social media activity is merely seen as a different way to express and share our preferences.
Personality and online behaviour
Studies are now legion that establishes a correlation between online activity and personality. Kosinski et al. (2015), for example, showed that the websites visited and the events on Facebook made it possible to deduce the Internet user’s personality. Youyou et al. (2015) went a step further by stating that the assessment of personality based on Facebook activity was more accurate than that done by humans. This last article had a definite impact on the general public press, which quickly declared that Facebook understood its users as their own family. Personality traits, while my online activity can reveal them, do not tell everything about me. Personality is only part of what constitutes a human being. All of this leads us to examine the 2nd axis of tense: the differences between my digital self and who I am.
Online staging and dramatisation
There is a difference between my digital counterpart and who I am; my online behaviours do not necessarily reflect my reality. The Internet allows freedom of tone, the immediacy of reaction, chain reactions, which are absent from interpersonal relationships in the real world. We get carried away on the Internet for subjects that are harmless in real life. We put on like to please, in a quest for reciprocity that says nothing about our deep interests. Besides, are we talking about our deep interests in social media, on forums, on the Internet in general? Is there not a form of digital restraint that pushes us not to say anything about what is important to us (at the risk of being judged). That leads us to follow the general opinion, to be part of a large digital tribe and thus affirm our membership in a collective movement. Nor should we lose sight of the fact that the overwhelming majority of users passively consume content on social media and that a tiny minority produce it.
 The quest for marketing sense also requires the recognition that the meaning given to online acts is not necessarily what you think it is. Indeed, let us keep in mind that online activity is also a narcissistic projection of an ideal digital self. Photographic staging on social media, the dramatisation of objects and brands in graphic compositions designed to arouse jealousy, are only the emerging part of this phenomenon. For example, can we imagine that a brand’s logo could become a body decoration in a mode where digital staging would be absent?
The quest for marketing sense also requires the recognition that the meaning given to online acts is not necessarily what you think it is. Indeed, let us keep in mind that online activity is also a narcissistic projection of an ideal digital self. Photographic staging on social media, the dramatisation of objects and brands in graphic compositions designed to arouse jealousy, are only the emerging part of this phenomenon. For example, can we imagine that a brand’s logo could become a body decoration in a mode where digital staging would be absent?
The Belgian artist Wim Delvoye has made a mockery of this trend by adorning pigs with the logos of luxury brands (here Vuitton). Is he making fun of it as an artistic gesture that makes fun of a curious human tendency to want to differentiate oneself? The cultural significance of the logo has changed, and with it, the appropriation of it by the masses.

Differences between online and offline activity
Let’s take an anecdotal example: mine. I have several passions (including painting and mineralogy) that I don’t talk about on social media. I am talking about very little in general terms. Everyone knows the 1% rule, which divides Internet participants into two categories: those who actively participate through content creation (1%), and passive consumers (99%). I maintain my passions in a mainly passive way (by reading), and it would, therefore, be necessary to have access to my navigation history to make you aware of this. Probably the 2nd part cookies can deliver here a fragmented picture of who I am. In the end, the passions that led me to follow a few pages on Facebook are anecdotal in comparison to the rest. So, there is a gap between my online self and my real self.
We should also remember that more than 80% of purchases are offline. The junction between offline and online remains a significant challenge for the retail sector of tomorrow (see the article on retail trends).
The myth of Big Data based on the breakdown of the individual’s essence into elementary particles composed of 0 and 1
Weakness N°2: differences between prediction and understanding
Can the individual be reduced to their data?
Here is another deception introduced by the “Big Data”. Since the individual leaves behind digital traces that would give an accurate picture of his or her being, these data conceal the mystery of future behaviours. Analysing ever-larger data would, therefore, make it possible to predict behaviour more accurately. The individual consequently assimilated to the Leibniz monad, to elementary particles composed of 0 and 1 that would contain his essence. Because that’s what it’s all about. Beyond personality (which we have seen above that a reliable analysis was possible from the digital traces left, for example, on social networks), Big Data promises an understanding of the essence of the individual. This proposal is misleading because the characteristic of the individual is his unpredictability. As Dominique Cardon pointed out, prediction errors are ultimately only statistical accidents. The false promise based on a proposal that my friend Dr Emmanuel Tourpe described as follows: “the person is replaced by the digital individual and the community by statistical generality”.
The person is replaced by the digital individual and the community by the statistical generality
Dr Emmanuel Tourpe, ARTE
Understanding the human being, an inaccessible dream
Let us not fall into excessive criticism of the Big Data. The digitalisation of our lives allows a level of analysis of our behaviours that is still unequalled. Where it took Charles Booth years of work to collect data on the inhabitants of a city (London), it now takes only a few minutes to obtain much more granular data volumes at a national level. Observing behaviour has never been more straightforward. But are we more than just observers of a reality that escapes us? Big Data salespeople will ensure that you can touch the intimate truth of human behaviour, use the data to predict future behaviour. If some of the reactions can indeed be predicted, it is necessary to remain humble. First, prediction can only be made with limited precision, an unknown part of the complexity of human behaviour. Second, the data should only be taken for what they are, that is, as external witnesses to a reality that remains mysterious. When we ” analyse ” the Big Data, we are only ethnographers, explorers making our way through a forest of data of which we know nothing, in theory. The ability to predict behaviour, made possible by modern computational methods, does not allow us to think that we understand human behaviour. These remain primarily impenetrable, as shown in the following example.
A concrete illustration of the discrepancy between prediction and understanding
Let’s take a concrete example to illustrate my point: the smartphone I bought a few weeks ago. The digital traces left by visiting different sites would have led you to predict my interest in purchasing a new smartphone. The keywords used for my research would also have allowed you to conclude which models I preferred. But in the end, what happened? I bought the smartphone after a visit to the shop. The act of buying, therefore, escapes any attempt at reconciliation (remember that more than 80% of purchases are offline). And above all, even if you could have predicted that my choice would be one or the other model, the decision-making mechanism will remain unknown: Why did I decide to change smartphones? What arguments made me choose one model over another?
 This knowledge of decision-making mechanisms remains essential to make strategic decisions and improve marketing. Simply observing behaviours superficially without trying to understand how they work deprives you of levers of action for better marketing, marketing that makes sense. How could you convince the consumer that you see, based on his digital traces, hesitate if you do not have the arguments that will resound in him?
This knowledge of decision-making mechanisms remains essential to make strategic decisions and improve marketing. Simply observing behaviours superficially without trying to understand how they work deprives you of levers of action for better marketing, marketing that makes sense. How could you convince the consumer that you see, based on his digital traces, hesitate if you do not have the arguments that will resound in him?
To acquire this finesse of understanding, I believe that other methodological approaches must be used (quantitative surveys, qualitative surveys).
Weakness N°3: difference between causes and correlations
The last tension we need to address is the one that results from the lack of understanding of the data analysed. Big Data promises to find correlations between scattered data that are too numerous to be examined by a human being. Thanks to Big Data, each individual is the subject of a specific analysis model; this is a fundamental change in the econometric reality that has prevailed until now. This requires us to explain how “predictions” were made in the past.
Behavioural modelling in econometrics
Before the Big Data, behaviour prediction was based on mass modelling. A sufficiently large set of individuals taken, and assumptions made about the factors that influenced behaviour in general, and the relevance of the model tested against these data. This resulted in a prediction model that was valid for a large number of individuals. These models were necessarily imperfect since individuals have different behaviours from each other, and the “predictable” part is, therefore, only the part that is common to all. Nevertheless, these models were beneficial because of the search for factors influencing behaviour based on a preliminary literature search and behavioural explanations of the role of each variable.
Big Data makes each individual a model in themselves
With Big Data, the situation is quite different. There is no longer any preconceived model, nor any attempt to generalise. Each individual becomes a model in themselves. Their digital traces analysed in such a way that correlations emerge that will be used to predict the future. Correlation ceases to be a source of questioning and understanding of behaviour. It is only a mathematical relationship between two variables of which we sometimes know nothing. Variables are no longer a source of questioning about the logic of behaviour. They are just superficial traces whose meaning escapes us; interpreted as a meaningless mathematical sign, in a desperate attempt to bring out the truth. The results are sometimes funny. Tyler Vigen has gathered in a book correlation close to mathematical perfection but meaningless. His Spurious Correlations site exposes some of these aberrations that could go unnoticed in traditional Big Data processing.
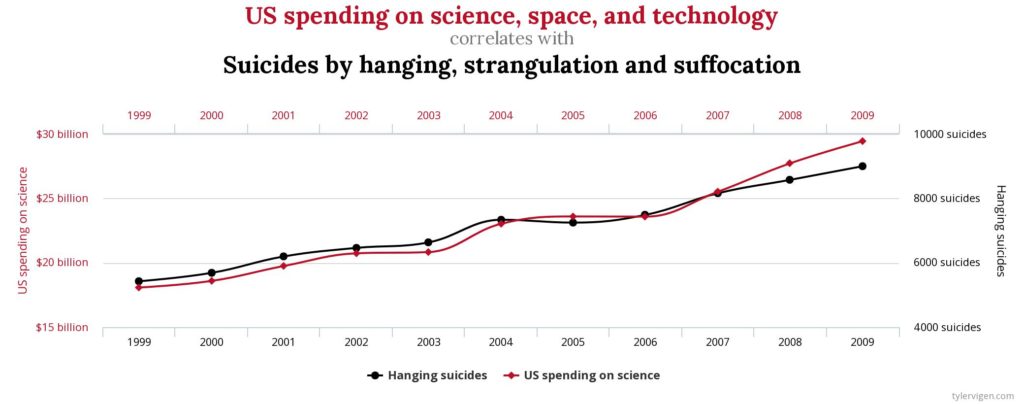
The above example makes it possible to identify the discrepancy between two very different realities: the mathematical correlation, on the one hand, and cause and effect on the other. Correlation does not necessarily explain the cause and effect. Worse, this problem becomes secondary in Big Data since we are promised to reveal a truth that escapes us thanks to mathematical correlations.
How can we find a dose of common sense in the treatment of Big Data? This is the subject of the last part of this article in which I question the marketing techniques to be combined to improve the analysis of behaviours.
Advantages and disadvantages of Big Data analysis for marketing purposes
Advantages
- Highlighting behaviours in a wide variety of contexts
- Determination of the user’s personality
Disadvantages
- Online behaviours are not necessarily the transposition of our offline behaviours
- The data are only a superficial trace and do not allow us to understand the reasons for the behaviours
- Mathematical correlations do not explain the cause and effect
Suggested roadmap for using big data in a sensible marketing approach
Let’s start by summarising the advantages and disadvantages of using Big Data before outlining an action plan to understand people’s behaviour better.
Advantages
The digital traces left by our digital activities allow us to shed light in-depth on some of our behaviours. They are the witnesses of our digital life and the reflection of certain traits of our personality.
Disadvantages
Digital traces are only a part of our business. Our online behaviours are not digital extensions of the offline world. The interpretation of the data can, therefore, only be made with the presence of this distorting mirror in mind. Moreover, a digital trace is only the superficial imprint of a behaviour that must be understood if the company wants to have a hold on the customer. To analyse the traces without understanding the reason for the customer’s journey is to remove all the meaning from the resulting marketing actions. To avoid falling into meaningless mathematical prediction, we must, therefore, focus on cause and effect. What reasons prompted the individual to do this or that, which led him or her to leave this or that trace?
A plan of action for better use of data for marketing purposes
How to combine the best of both worlds? How can Big Data be used to its full potential without compromising analysis by the problems highlighted above?
Tomorrow’s marketing can only be conceived, in my opinion, through a combination of techniques on the one hand, and an iterative approach on the other. Technology inevitably influences our behaviours (tension n°1) and understanding the changing nature of our routines necessarily requires the constant review of existing models. The marketer’s work is, therefore, an infinite loop made up of the following elements:
- Study of the existing: what is already known about the behaviour to be studied? Are there models that can identify factors influencing behaviour?
- Data analysis using existing models: do the data I have collected confirm existing models and if so, in what proportion? It is at this level that existing data must be explored (business intelligence)
- Analysis of the “holes” in the model: how to explain the part of behaviour that I cannot solve based on existing data? At this stage, we must ask ourselves two questions: first, about the influential factors that are still unknown; second, about the significance of the influence factors taken into account in the model. This is the time for qualitative research that aims to explore behaviours in-depth and give meaning to actions.
- Missing data collection: what actions should be taken to collect missing data to refine it? This is a “business” reflection that should lead to the capture of missing data.
This cycle is destined to be repeated. The marketer’s work thus becomes an eternal restart.
Any questions, comments? Feel free to contact me or invite me to give this presentation to your audience.
Sources
- Les échos
- EMC
- Statista
- Kosinski, M., Bachrach, Y., Kohli, P., Stillwell, D., & Graepel, T. (2014). Manifestations of user personality in website choice and behaviour on online social networks. Machine learning, 95(3), 357-380.
- Latzko-Toth, G., Bonneau, C., & Millette, M. (2017). Small data, thick data: Thickening strategies for trace-based social media research. The SAGE handbook of social media research methods, 199-214.
- Thompson, C. J. (2019). The ‘big data’myth and the pitfalls of ‘thick data’opportunism: on the need for a different ontology of markets and consumption. Journal of Marketing Management, 35(3-4), 207-230.
- Youyou, W., Kosinski, M., & Stillwell, D. (2015). Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4), 1036-1040.
Illustrative images: Shutterstock, Canadahistory



![Illustration of our post "Free Generative AI Detectors: Which Ones to Choose? [Complete Test 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)
