

En la actualidad, el progreso tecnológico nos permite disfrutar de excelentes condiciones de vida. El control del espacio, el control de la reproducción o el control de la información, entre otros aspectos, son objetivos que ya hemos cumplido. Sin embargo, el control del tiempo sigue estando fuera de nuestro alcance; alguna de las obsesiones de la humanidad giran en torno al poder de este recurso, el cual se nos ofrece al nacer en una cantidad desesperadamente finita: el tiempo. Permanecer joven, hacerse mayor, perpetuar la memoria o predecir el futuro son solo algunas de las formas que toma esta obsesión. Este rechazo de una realidad biológica parece responder a una regla misteriosa que los científicos no pueden explicar. La transformación digital de nuestras vidas ofrece la oportunidad de solucionar uno de estos problemas: anticiparnos al futuro. En el presente articulo vamos a tratar este asunto.
Para ello, he estructurado esta presentación en torno a tres pautas. En primer lugar, mostraré que la predicción es una práctica antigua y que la digitalización de nuestras vidas nos ofrece una oportunidad única para predecir el futuro. A continuación, destacaré las limitaciones conceptuales del análisis de Big Data. Finalmente, propondré un plan de acción para integrar el Big Data en un enfoque de estudio de marketing y comportamiento. Este enfoque incorporará técnicas tradicionales de investigación de mercado
Nota: este artículo es una referencia a mi presentación, el 6 de diciembre de 2019, en el congreso anual de la Asociación Belga de Marketing (ver presentación a continuación).
Resumen
- Predecir el futuro: una obsesión constante en todo momento
- Datos para mejores predicciones
- Una vida cada vez más digital
- La tensión entre el marketing cualitativo y el cuantitativo
- Las tres debilidades metodológicas del Big Data
- Cómo utilizar Big Data para un marketing significativo
- Fuentes
Predecir el futuro: una antigua obsesión

Predecir el futuro ha sido una actividad diaria desde el principio de los tiempos. El objetivo de la predicción es, por supuesto, influir en el transcurso del tiempo para obtener un beneficio colectivo o individual: mejores cosechas, más riqueza, la perpetuación del nombre a través de la descendencia, etc. Los seres humanos parecen tener un problema de incertidumbre y, por lo tanto, siempre han buscado tranquilizarse al respecto: oráculos al servicio del faraón en el antiguo Egipto, presagios de todas las formas de poder en la antigua Roma…
Esta tradición de adivinación y predicción del futuro continúa hoy en una escala nunca antes vista con los horóscopos. El 12% de los estadounidenses leen sus horóscopos a diario, el 32% ocasionalmente y el 26% creen en la astrología. La necesidad de conocer el futuro se adapta a cada época y a cada cultura. Sin embargo, los resultados, como estará de acuerdo, siguen siendo inciertos.
26% de los estadounidenses creen en la astrología
Sin embargo, la tecnología permite anticipar el futuro mejor que nunca. La revolución de Big Data, combinada con capacidades informáticas y de almacenamiento cada vez más económicas, hace que el procesamiento de la información sea más asequible y que la comprensión de los fenómenos naturales y humanos sea mejor que nunca. Ya en 2003, se estimaba que, en 20 años, los avances tecnológicos habían evolucionado a un promedio de dos días en las previsiones meteorológicas. Por tanto, a medida que se acumulan los datos, es razonable suponer que las predicciones solo pueden mejorar.

Multiplicación de datos para mejores predicciones
A riesgo de repetir cifras ya conocidas, intentemos comprender las consecuencias de la digitalización de nuestras vidas con algunas estadísticas:
- El volumen total de datos disponibles sería de 40 Zb, lo que corresponde a cuarenta mil billones de Gigabytes. Representado en números sería esto: 40,000,000,000,000,000,000 Gb.
- En 2017, el 90% de los datos se habían creado en los dos años anteriores.
- El 57% de los seres humanos tiene acceso a Internet (un 9,9% más que en 2018), y cada día se generan 2,5 trillones de bytes en Internet.
- El 33% del tiempo que se pasa en Internet es en las redes sociales.
- El número de objetos conectados se multiplicará por 3 en los próximos seis años.
 entre 2015 et 2025")
Por lo tanto, el volumen de datos disponibles solo aumentará, documentando un poco más cada interacción humana y revelando un poco más de nuestro comportamiento. Con tal cantidad de datos, queda claro que nuestras acciones se pueden analizar, comparar y, por supuesto, predecir cada vez más.
Las redes sociales representan el 33% del tiempo dedicado a Internet
Una vida cada vez más digital, una bendición para los especialistas en marketing
Nuestras vidas son cada vez más digitales y el marketing moderno, en su búsqueda de sentido, ve los datos como una tierra prometida, un paraíso que le permitirá hacer realidad su sueño del pasado: el de una relación de tú a tú con cada uno de los clientes de las compañías.

Al igual que en la fiebre del oro de California del siglo XIX, los que se hicieron ricos no fueron necesariamente los que pensamos que sí, a saber: reemplace las pepitas de oro con datos (“el nuevo petróleo”), reemplace las tiendas generales con proveedores de soluciones en la nube y obtendrá un emocionante paralelo para ver el fenómeno de Big Data desde un nuevo ángulo.
 lors de la ruée vers l'or en Californie au XIXème siècle")
La promesa de un comportamiento completamente digitalizado permite que el marketing cambie. A partir de las ciencias sociales (una ciencia “blanda”, como la llaman los franceses) el marketing se adorna con estadísticas y matemáticas, y comienza una transformación que, espera, le permitirá transformarse en ciencia dura: el gusano sueña con convertirse en una mariposa en el futuro.
Sin embargo, debemos cuestionar la relevancia de esta transición a todos los datos: ¿Puede el marketing, como ciencia centrada en comprender y satisfacer las necesidades de los clientes, basarse en datos?
Tensión subyacente entre investigación cualitativa e investigación cuantitativa
Esta pregunta refleja la tensión que ha existido durante décadas entre la investigación cualitativa y la investigación cuantitativa. La segunda le dice a la primera que lo cuantitativo es suficiente en sí mismo, mientras que el primero responde que la comprensión del comportamiento solo se puede lograr a través de la investigación cualitativa. Esta infructuosa oposición dio lugar a intentos de mediación en forma de, por ejemplo, el concepto de “datos densos”, siendo esta la respuesta a los escépticos que promete aumentar la relevancia de los resultados de Big Data a través de los conocimientos de la investigación cualitativa (ver Latzko-Toth et al., 2017).
Como señala Thompson (2019), el “mito del Big Data es cualitativamente diferente de su contraparte cuantitativa über alles” (traducción libre del inglés, “sobre todo” en español). En el siglo XX, las técnicas cuantitativas se erigieron como métodos positivistas para escapar de la naturaleza aleatoria e intuitiva de las técnicas cualitativas. Hoy, el Big Data refuerza esta visión empírica al agregar “tecnotopía” (Thompson 2019). Esta visión coloca al Big Data como la única respuesta, rechazando así la legitimidad de otros enfoques.
Los datos densos son una propuesta para aumentar la relevancia de los resultados del Big Data a través de los conocimientos de la investigación cualitativa.
Este discurso radical nos obliga a explorar sus límites para que el análisis de trazas digitales se pueda utilizar de la mejor manera posible. Te propongo, pues, que examines tres áreas de tensión que nos permitirán cuestionar el lugar exacto del Big Data en el análisis del comportamiento humano.

Debilidad N ° 1: la diferencia entre las actividades en línea (online) y el comportamiento fuera de línea (offline)
El mito del Big Data se basa en una suposición falaz: nuestros comportamientos en línea reflejarían nuestro comportamiento en el mundo real. Nuestra actividad en las redes sociales se ve simplemente como una forma diferente de expresar y compartir nuestras preferencias.
Personalidad y comportamiento en línea
Los estudios son ahora numerosos, los cuales establecen una correlación entre la actividad en línea y la personalidad. Kosinski y col. (2015), por ejemplo, mostraron que los sitios web visitados y los eventos en Facebook permitieron deducir la personalidad del internauta. Youyou y col. (2015) fueron un paso más allá al afirmar que la evaluación de la personalidad basada en la actividad de Facebook era más precisa que la realizada por humanos. Este último artículo tuvo un impacto definitivo en la prensa pública en general, que rápidamente declaró que Facebook entendía a sus usuarios como a su propia familia. Los rasgos de personalidad, si bien mi actividad en línea puede revelarlos, no dicen todo sobre mí. La personalidad es solo una parte de lo que constituye un ser humano. Todo esto nos lleva a examinar el segundo eje del tiempo: las diferencias entre mi yo digital y quién soy.
Puesta en escena y dramatización online
Hay una diferencia entre alter ego digital y quién soy en mi totalidad, ya que mis comportamientos en línea no reflejan necesariamente mi realidad. Internet permite la libertad de tono, la inmediatez de la reacción o las reacciones en cadena, aspectos que permanecen ausentes en las relaciones interpersonales del mundo real. En Internet nos dejamos llevar por temas que son inofensivos en la vida real: nos ponemos la careta de agradar, en una búsqueda de reciprocidad que no dice nada sobre nuestros intereses profundos. Además, ¿estamos hablando de nuestros profundos intereses en las redes sociales, en los foros, en Internet en general? ¿No existe una forma de restricción digital que nos empuja a no decir nada sobre lo que es importante para nosotros (a riesgo de ser juzgados)? Eso nos lleva a seguir la opinión general, a ser parte de una gran tribu digital y así afirmar nuestra pertenencia a un movimiento colectivo. Tampoco debemos perder de vista el hecho de que la inmensa mayoría de los usuarios consume pasivamente contenido en las redes sociales, y que una pequeña minoría lo produce.
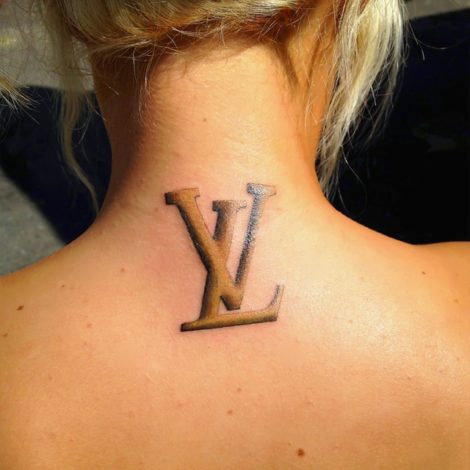 La búsqueda del sentido del marketing también requiere el reconocimiento de que el significado que se le da a los actos en línea no es necesariamente el que usted cree que es; hemos de tener en cuenta que la actividad en línea también es una proyección narcisista de un yo digital ideal. La puesta en escena fotográfica en las redes sociales, la dramatización de objetos y marcas en composiciones gráficas diseñadas para despertar celos, son solo la parte emergente de este fenómeno. Por ejemplo, ¿podemos imaginar que el logotipo de una marca podría convertirse en una decoración corporal en un modo en el que la puesta en escena digital estaría ausente?
La búsqueda del sentido del marketing también requiere el reconocimiento de que el significado que se le da a los actos en línea no es necesariamente el que usted cree que es; hemos de tener en cuenta que la actividad en línea también es una proyección narcisista de un yo digital ideal. La puesta en escena fotográfica en las redes sociales, la dramatización de objetos y marcas en composiciones gráficas diseñadas para despertar celos, son solo la parte emergente de este fenómeno. Por ejemplo, ¿podemos imaginar que el logotipo de una marca podría convertirse en una decoración corporal en un modo en el que la puesta en escena digital estaría ausente?
El artista belga Wim Delvoye se ha burlado de esta tendencia adornando a los cerdos con los logotipos de marcas de lujo (aquí Vuitton). ¿Se burla de él como un gesto artístico que se burla de una curiosa tendencia humana a querer diferenciarse? El significado cultural del logo ha cambiado y, con él, la apropiación del mismo por parte de las masas.

Diferencias entre actividad online y offline
Tomemos un ejemplo anecdótico: el mío. Tengo varias pasiones (incluida la pintura y la mineralogía), sobre las cuales no hablo en las redes sociales (en términos generales, hablo de muy poco). Todo el mundo conoce la regla del 1%, la cual divide a los participantes de Internet en dos categorías: los que participan activamente a través de la creación de contenido (1%) y los consumidores pasivos (99%). Mantengo mis pasiones de forma mayoritariamente pasiva (leyendo), por lo que sería necesario tener acceso a mi historial de navegación para darme a conocer. Probablemente la segunda parte de las cookies pueda ofrecer aquí una imagen fragmentada de quién soy. Al final, las pasiones que me llevaron a seguir algunas páginas en Facebook son anecdóticas en comparación con el resto. Entonces, hay una brecha entre mi yo en línea y mi yo real.
También debemos recordar que más del 80% de las compras son offline. La unión entre el mundo online y el offline sigue siendo un desafío importante para el sector minorista del mañana (consulte el artículo sobre tendencias minoristas).
El mito del Big Data basado en la descomposición de la esencia del individuo en partículas elementales compuestas por 0 y 1
Debilidad N ° 2: diferencias entre predicción y comprensión
¿Se puede reducir al individuo a sus datos?
Aquí hay otro engaño introducido por el “Big Data”; dado que el individuo deja huellas digitales que le darían una imagen precisa de su ser, estos datos ocultan el misterio de comportamientos futuros. El análisis de datos cada vez más grandes permitiría, por lo tanto, predecir el comportamiento con mayor precisión. En consecuencia, el individuo se asimiló a la mónada de Leibniz, a partículas elementales compuestas por 0 y 1 que contendrían su esencia. Porque de eso se trata todo. Más allá de la personalidad (que hemos visto anteriormente que era posible un análisis confiable a partir de las huellas digitales dejadas, por ejemplo, en las redes sociales), el Big Data promete una comprensión de la esencia del individuo. Esta propuesta es engañosa porque la característica del individuo es su imprevisibilidad. Como señaló Dominique Cardon, los errores de predicción son, en última instancia, accidentes estadísticos. La falsa promesa basada en una propuesta que mi amigo, el Dr. Emmanuel Tourpe, describió de la siguiente manera: “la persona es reemplazada por el individuo digital y la comunidad por la generalidad estadística”.
La persona es reemplazada por el individuo digital y la comunidad por la generalidad estadística
Dr. Emmanuel Tourpe, ARTE
Entender al ser humano: un sueño inaccesible
No caigamos en una crítica excesiva al Big Data; la digitalización de nuestras vidas permite un nivel de análisis de nuestros comportamientos aún inigualable. Mientras que a Charles Booth le llevó años de trabajo recopilar datos sobre los habitantes de una ciudad (Londres), ahora solo se necesitan unos minutos para obtener volúmenes de datos mucho más precisos a nivel nacional. Observar el comportamiento nunca ha sido más sencillo, pero… ¿somos más que simples observadores de una realidad que se nos escapa? Los vendedores de Big Data se asegurarán de que pueda tocar la verdad íntima del comportamiento humano y utilizar los datos para predecir el comportamiento futuro. Si realmente se pueden predecir algunas de las reacciones, es necesario permanecer humilde. Primero, la predicción solo se puede hacer con precisión limitada, una parte desconocida de la complejidad del comportamiento humano. En segundo lugar, los datos solo deben tomarse por lo que son, es decir, como testigos externos de una realidad que sigue siendo misteriosa. Cuando “analizamos” el Big Data, sólo somos etnógrafos, exploradores que nos abrimos paso a través de un bosque de datos de los que en teoría no sabemos nada. La capacidad de predecir el comportamiento, que es posible gracias a los métodos computacionales modernos, no nos permite pensar que comprendemos el comportamiento humano, ya que estos permanecen principalmente impenetrables, como se muestra en el siguiente ejemplo.
Una ilustración concreta de la discrepancia entre predicción y comprensión.
Tomemos un ejemplo concreto para ilustrar mi punto: el teléfono inteligente que compré hace unas semanas. Los rastros digitales que dejaron al visitar diferentes sitios lo habrían llevado a predecir mi interés en comprar un nuevo teléfono inteligente. Las palabras clave utilizadas para mi investigación también le habrían permitido concluir qué modelos prefería. Pero al final, ¿qué pasó? Compré el teléfono inteligente después de una visita a la tienda. El acto de comprar, por tanto, escapa a cualquier intento de conciliación (recordemos que más del 80% de las compras son offline). Y, sobre todo, y aunque pudieras haber predicho que mi elección sería uno u otro modelo, el mecanismo de toma de decisiones seguirá siendo desconocido: ¿Por qué decidí cambiar de teléfono inteligente? ¿Qué argumentos me hicieron elegir un modelo sobre otro?
 Este conocimiento de los mecanismos de toma de decisiones sigue siendo esencial para tomar decisiones estratégicas y mejorar el marketing. El simple hecho de observar los comportamientos de manera superficial sin tratar de comprender cómo funcionan lo priva de las palancas de acción para un mejor marketing, un marketing que tiene sentido. ¿Cómo convencer al consumidor de que ve, en base a sus huellas digitales, dudar si no tiene los argumentos que resonarán en él?
Este conocimiento de los mecanismos de toma de decisiones sigue siendo esencial para tomar decisiones estratégicas y mejorar el marketing. El simple hecho de observar los comportamientos de manera superficial sin tratar de comprender cómo funcionan lo priva de las palancas de acción para un mejor marketing, un marketing que tiene sentido. ¿Cómo convencer al consumidor de que ve, en base a sus huellas digitales, dudar si no tiene los argumentos que resonarán en él?
Para adquirir esta delicadeza de comprensión, creo que se deben utilizar otros enfoques metodológicos (encuestas cuantitativas, encuestas cualitativas).
Debilidad N ° 3: diferencia entre causas y correlaciones
La última tensión que debemos abordar es la que resulta de la falta de comprensión de los datos analizados. El Big Data promete encontrar correlaciones entre datos dispersos que son demasiado numerosos para ser examinados por un ser humano. Gracias a él, cada individuo es objeto de un modelo de análisis específico; este es un cambio fundamental en la realidad econométrica que ha prevalecido hasta ahora, lo que requiere que expliquemos cómo se hicieron las “predicciones” en el pasado.
Modelado del comportamiento en econometría
Antes del Big Data, la predicción del comportamiento se basaba en modelos masivos. Se tomó un conjunto suficientemente grande de individuos y se hicieron suposiciones sobre los factores que influyeron en el comportamiento en general, y la relevancia del modelo probado con estos datos. Esto resultó en un modelo de predicción válido para un gran número de personas. Estos modelos eran necesariamente imperfectos ya que los individuos tienen comportamientos diferentes entre sí, y la parte “predecible” es, por lo tanto, solo la parte que es común a todos. Sin embargo, estos modelos resultaron beneficiosos debido a la búsqueda de factores que influyen en el comportamiento a partir de una búsqueda bibliográfica preliminar y explicaciones conductuales del papel de cada variable.
Big Data hace de cada individuo un modelo en sí mismo
Con el Big Data, la situación es bastante diferente. Ya no hay ningún modelo preconcebido, ni ningún intento de generalizar: cada individuo se convierte en un modelo en sí mismo. Sus rastros digitales son analizados de tal forma que surjan correlaciones que servirán para predecir el futuro. Dicha correlación deja de ser una fuente de cuestionamiento y comprensión del comportamiento, ya que solo una relación matemática entre dos variables de las que a veces no sabemos nada. Las variables ya no son fuente de cuestionamientos sobre la lógica del comportamiento. Son sólo huellas superficiales cuyo significado se nos escapa, interpretado como un signo matemático sin sentido, en un intento desesperado por sacar a la luz la verdad. Los resultados a veces son divertidos. Tyler Vigen ha recogido en un libro una correlación cercana a la perfección matemática pero sin sentido. Su sitio de Spurious Correlations expone algunas de estas aberraciones que podrían pasar desapercibidas en el procesamiento tradicional de Big Data.
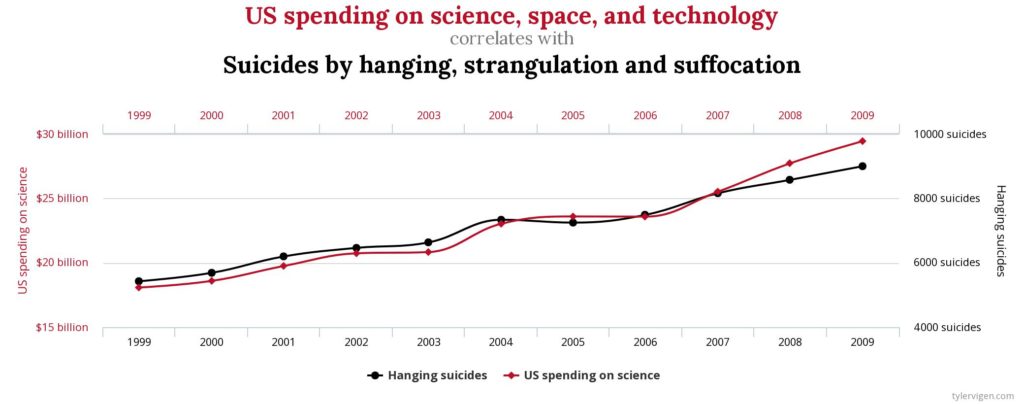
El ejemplo anterior permite identificar la discrepancia entre dos realidades muy diferentes: la correlación matemática, por un lado, y la causa y efecto, por otro. Dicha correlación no explica necesariamente la causa y el efecto. Peor aún, este problema se vuelve secundario en Big Data ya que se nos promete revelar una verdad que se nos escapa gracias a las correlaciones matemáticas.
¿Cómo podemos encontrar una dosis de sentido común en el tratamiento del Big Data? Este es el tema de la última parte de este artículo en el que cuestiono las técnicas de marketing a combinar para mejorar el análisis de las conductas.
Ventajas y desventajas del análisis de Big Data con fines de marketing
Ventajas
- Destacar comportamientos en una amplia variedad de contextos
- Determinación de la personalidad del usuario
Desventajas
- Los comportamientos en línea no son necesariamente la réplica de nuestros comportamientos fuera de línea.
- Los datos son solo un rastro superficial y no nos permiten comprender los motivos de los comportamientos
- Las correlaciones matemáticas no explican la causa y el efecto.
Hoja de ruta sugerida para usar el big data en un enfoque de marketing efectivo:
Comencemos por resumir las ventajas y desventajas de usar el Big Data antes de esbozar un plan de acción para comprender mejor el comportamiento de las personas.
Ventajas
Los rastros digitales que dejan nuestras actividades digitales nos permiten arrojar luz en profundidad sobre algunos de nuestros comportamientos, ya que son los testigos de nuestra vida digital y el reflejo de ciertos rasgos de nuestra personalidad.
Desventajas
Los rastros digitales son solo una parte de nuestro negocio. Nuestros comportamientos en línea no son extensiones digitales del mundo fuera de línea. Por lo tanto, la interpretación de los datos solo puede hacerse teniendo en cuenta la presencia de este espejo distorsionador. Además, un rastro digital es solo la huella superficial de un comportamiento que debe entenderse si la empresa quiere controlar al cliente: analizar los rastros sin comprender el motivo del viaje del cliente es eliminar todo el significado de las acciones de marketing resultantes. Para evitar caer en una predicción matemática sin sentido debemos, por tanto, centrarnos en la causa y el efecto. ¿Qué razones llevaron al individuo a hacer esto o aquello, a dejar tal o cual huella?
Un plan de acción para un mejor uso de los datos con fines de marketing.
¿Cómo combinar lo mejor de ambos mundos? ¿Cómo se puede utilizar el Big Data en todo su potencial sin comprometer el análisis por los problemas destacados anteriormente?
El marketing del mañana solo puede concebirse, en mi opinión, mediante una combinación de técnicas, por un lado, y un enfoque reiterativo, por el otro. La tecnología influye inevitablemente en nuestros comportamientos (tensión n ° 1) y comprender la naturaleza cambiante de nuestras rutinas requiere necesariamente la revisión constante de los modelos existentes. El trabajo del especialista en marketing es, por tanto, un bucle infinito formado por los siguientes elementos:
- Estudio de lo existente: ¿qué se sabe ya del comportamiento a estudiar? ¿Existen modelos que puedan identificar los factores que influyen en el comportamiento?
- Análisis de datos utilizando modelos existentes: ¿los datos que he recopilado confirman los modelos existentes?; de ser así, ¿en qué proporción? Es en este nivel donde se deben explorar los datos existentes (inteligencia empresarial)
- Análisis de los “huecos” del modelo: ¿cómo explicar la parte del comportamiento que no puedo resolver en base a los datos existentes? En esta etapa, debemos hacernos dos preguntas: primero, sobre los factores influyentes que aún se desconocen; segundo, sobre la importancia de los factores de influencia tomados en cuenta en el modelo. Este es el momento de la investigación cualitativa que tiene como objetivo explorar los comportamientos en profundidad y dar sentido a las acciones.
- Recopilación de los datos que faltan: ¿qué acciones se deben tomar para recopilarlos, para así tratarlos? Esta es una reflexión “empresarial” que debería conducir a la captura de estos datos.
Este ciclo está destinado a repetirse, lo que convierte el trabajo del especialista en marketing en un eterno reinicio.
Si tiene alguna pregunta o comentario, no dude en contactarme o invitarme a dar esta presentación a su audiencia.
Fuentes
- Les échos
- EMC
- Statista
- Kosinski, M., Bachrach, Y., Kohli, P., Stillwell, D., & Graepel, T. (2014). Manifestations of user personality in website choice and behaviour on online social networks. Machine learning, 95(3), 357-380.
- Latzko-Toth, G., Bonneau, C., & Millette, M. (2017). Small data, thick data: Thickening strategies for trace-based social media research. The SAGE handbook of social media research methods, 199-214.
- Thompson, C. J. (2019). The ‘big data’myth and the pitfalls of ‘thick data’opportunism: on the need for a different ontology of markets and consumption. Journal of Marketing Management, 35(3-4), 207-230.
- Youyou, W., Kosinski, M., & Stillwell, D. (2015). Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4), 1036-1040.
Ilustraciones: shutterstock, Canadahistory





