

Dankzij de technologische vooruitgang kunnen we genieten van onevenaarbare levensomstandigheden. De uitdagingen van controle van de ruimte, controle van de reproductie, controle van de informatie werden al aangegaan. Tijdscontrole blijft echter buiten bereik. Veel menselijke obsessies gaan om het controleren van de bron die we bij onze geboorte krijgen aangeboden in een wanhopig eindige hoeveelheid: de tijd. Jong blijven, oud worden, je geheugen in stand houden, de toekomst voorspellen zijn enkele vormen die deze obsessie aanneemt. Deze weigering van een biologische realiteit lijkt te beantwoorden aan een mysterieuze regel (Engelse site) die wetenschappers niet kunnen verklaren. De digitale transformatie van ons leven biedt een kans om een van deze problemen op te lossen: het anticiperen op de toekomst. En dat is wat ik met u in dit artikel wil onderzoeken…
In dit artikel structureer ik mijn verhaal rond 3 richtlijnen. Ten eerste wil ik tonen dat de praktijk van voorspellingen al sinds de oudheid bestaan en dat de digitalisering van ons leven ons een unieke kans biedt om de toekomst te voorspellen. Vervolgens belicht ik de conceptuele beperkingen van de analyse door Big Data. Ten slotte stel al ik een actieplan voor om Big Data te integreren in een marketing- en gedragsgerichte aanpak. Deze aanpak omvat de traditionele marktonderzoekstechnieken.
Opmerking: dit artikel dient als verwijzing naar mijn deelname op 6 december 2019 op het jaarlijkse congres (Engelse site) van de Belgian Association of Marketing (zie presentatie hieronder).
Samenvatting
- De toekomst voorspellen: een obsessie van alle tijden
- Gegevens ter ondersteuning van betere voorspellingen
- Een almaar meer gedigitaliseerd leven
- Spanning tussen kwalitatieve en kwantitatieve marketing
- De 3 methodologische zwakke punten van Big Data
- Hoe Big Data aanwenden voor een zinvolle marketing
- Bronnen
Het voorspellen van de toekomst is een eeuwenoude obsessie

Het voorspellen van de toekomst is al sinds mensenheugenis een dagelijkse bezigheid. Het doel van de voorspelling dient vanzelfsprekend om de loop der tijd te beïnvloeden om een collectief of individueel voordeel te verkrijgen: betere oogsten, meer rijkdom, bestendiging van de naam door afstamming. De mens lijkt moeite te hebben met onzekerheid en heeft daarom altijd geprobeerd zichzelf gerust te stellen: orakels in dienst van de farao in het oude Egypte, voorspellingen van alle vormen van macht in het oude Rome.
Deze traditie van waarzeggerij en toekomstvoorspelling gaat de dag vandaag verder op een nog nooit eerder geziene schaal in de horoscopen. 12% van de Amerikanen leest ze elke dag, 32% af en toe en 26% gelooft in astrologie. De behoefte om de toekomst te kennen is aangepast aan elke tijdsperiode, aan elke cultuur. U zult het er echter mee eens zijn dat de resultaten onzeker blijven.
26% van de Amerikanen gelooft in astrologie
Toch maakt de technologie het mogelijk om beter dan ooit te anticiperen op de toekomst. De revolutie in Big Data, gecombineerd met steeds goedkopere opslag- en rekenmogelijkheden, maakt informatieverwerking betaalbaarder en de kennis van natuurlijke en menselijke fenomenen beter dan ooit tevoren. Al in 2003 werd geschat dat de technologische vooruitgang in 20 jaar tijd gemiddeld twee dagen vroegere weersvoorspelling heeft mogelijk gemaakt (Franse site). Naarmate er almaar meer gegevens beschikbaar zijn, is het redelijk aan te nemen dat de voorspellingen alleen maar beter kunnen worden.

De verveelvoudiging van gegevens voor betere voorspellingen
Laten we, met het risico dat u de cijfers al kent, proberen de gevolgen van de digitalisering van ons leven om te zetten in enkele statistieken:
- het totale volume aan beschikbare gegevens zou 40 Zb bedragen, wat overeenkomt met veertigduizend miljard gigabyte. In cijfers wordt dit 40.000.000.000.000 Gb.
- In 2017 werd 90% van de gegevens tijdens de voorafgaande twee jaar gecreëerd.
- 57% van de mensen heeft toegang tot het internet (een stijging van 9,9% ten opzichte van 2018) en elke dag worden er 2,5 triljoen bytes op het internet gegenereerd.
- 33% van de tijd die op het internet wordt doorgebracht, wordt besteed aan sociale media.
- het aantal verbonden objecten zal de komende 6 jaar verdrievoudigen.
 entre 2015 et 2025")
Evolutie van het aantal apparaten dat op het internet is aangesloten (in miljarden) tussen 2015 en 2025
De hoeveelheid beschikbare gegevens zal dus alleen maar toenemen, waardoor elke menselijke interactie een telkens een beetje meer gedocumenteerd wordt en elke kant van ons gedrag een beetje meer wordt blootgelegd. Met zoveel gegevens wordt duidelijk dat onze acties steeds meer ontleed, vergeleken en natuurlijk voorspeld kunnen worden.
Sociale media vertegenwoordigen 33% van de tijd die op het internet wordt doorgebracht.
Een steeds digitaler leven, een zegen voor de marketeers
Ons leven verloopt steeds meer op digitale wijze en de moderne marketing beschouwt data, in de zoektocht naar een betekenisvolle marketing, als het beloofde land, een paradijs dat het mogelijk maakt om een droom uit het verleden te realiseren, namelijk een persoonlijke relatie met elke klant van het bedrijf.

Goudzoekers tijdens de periode van de goudkoorts in Klondike (Canada) in de 19e eeuw
Net als in de Californische goudkoorts van de 19e eeuw, waren degenen die rijk werden niet noodzakelijkerwijs degenen die we geloofden. Vervang goudklompjes met data (‘de nieuwe olie’), vervang algemene winkels door leveranciers van cloudoplossingen en u krijgt een interessante parallel om het Big Data-fenomeen vanuit een nieuwe invalshoek te bekijken.
 lors de la ruée vers l'or en Californie au XIXème siècle")
Kruidenierswinkel tijdens de periode van de goudkoorts in Yukon in de 19e eeuw. Copyright: Glenbow Archives
De belofte van volledig gedigitaliseerd gedrag laat marketing toe om te veranderen. Vanuit de sociale wetenschap (een ‘zachte’ wetenschap zoals de Fransen het noemen) wordt marketing aangevuld met statistische en wiskundige finesses, en begint een transformatie die, zoals wordt gehoopt, een overgang mogelijk te maken naar een harde wetenschap. De rups droomt van een toekomst als vlinder.
We moeten ons echter afvragen of deze overgang naar ‘alle gegevens’ wel relevant is. Kan marketing als een wetenschap gericht op het begrijpen en bevredigen van de behoeften van de klant enkel datagericht zijn?
Onderliggende spanning tussen kwalitatief en kwantitatief onderzoek
Deze vraag weerspiegelt de spanning die al tientallen jaren bestaat tussen kwalitatief en kwantitatief onderzoek. Het laatste zegt de eerste dat het kwantitatieve op zich voldoende is, terwijl de eerste antwoordt dat begrip van het gedrag alleen kan worden bereikt door middel van kwalitatief onderzoek. Deze, steriele, tegenstelling leidde tot pogingen tot bemiddeling, bijvoorbeeld in de vorm van het begrip ‘thick data’. ‘Thick data’ is het antwoord op sceptici die beloven de relevantie van Big Data resultaten te vergroten door inzichten uit kwalitatief onderzoek (zie Latzko-Toth et al., 2017, Franse site).
Zoals Thompson (2019, Engelse site) opmerkt, is de “mythe van Big Data kwalitatief verschillend van zijn kwantitatieve tegenhanger” (vrije vertaling uit het Engels). In de 20e eeuw werden kwantitatieve technieken als positivistische methoden bestempeld om te ontsnappen aan het willekeurige en intuïtieve karakter van kwalitatieve technieken. Vandaag de dag versterkt Big Data deze empirische visie door toevoeging van techno-utopische retoriek (Thompson 2019). Deze visie plaatst Big Data als het enige antwoord en verwerpt daarmee de legitimiteit van andere benaderingen.
‘Thick data’ is een voorstel om de relevantie van de resultaten uit Big Data te verhogen door inzichten uit kwalitatief onderzoek.
Dit radicale discours dwingt ons om de grenzen ervan te verkennen, zodat digitale sporenanalyse zo goed mogelijk kan worden gebruikt. Ik stel voor om drie spanningsvelden te onderzoeken die ons in staat stellen om de reële plaats van Big Data in de analyse van menselijk gedrag in vraag te stellen.

Zwakte nr. 1: het verschil tussen online activiteiten en offline gedrag
De mythe van Big Data is gebaseerd op een misleidende veronderstelling: ons online gedrag zou een weerspiegeling zijn van ons gedrag in de echte wereld. Onze activiteit op sociale media wordt beschouwd als een eenvoudigweg andere manier om voorkeuren te uiten en te delen.
Persoonlijkheid en online gedrag
Er bestaan tal van studies die een verband leggen tussen online activiteit en persoonlijkheid. Kosinski e.a. (2015, Engelse site) lieten bijvoorbeeld zien dat de bezochte websites en de activiteiten op Facebook het mogelijk maakten om de persoonlijkheid van de internetgebruiker af te leiden. Youyou et al (2015, Engelse site) gingen nog een stapje verder door te stellen dat de evaluatie van de persoonlijkheid op basis van Facebook-activiteiten nauwkeuriger was dan die van mensen. Dit laatste artikel had een duidelijke impact in de publieke pers, die al snel verklaarde dat Facebook zijn gebruikers als zijn eigen familie zag. Persoonlijkheidskenmerken, hoewel ze kunnen worden onthuld door mijn online activiteit, vertellen niet alles over mij. Persoonlijkheid is slechts een deel van wat een mens is. Dit brengt ons ertoe een 2e punt van spanning te onderzoeken: de verschillen tussen mijn digitale zelf en wie ik werkelijk ben.
Online enscenering en dramatisering
Er is duidelijk een verschil tussen mijn digitale tegenhanger en wie ik werkelijk ben; mijn online gedrag weerspiegelt niet noodzakelijkerwijs mijn realiteit. Het internet biedt vrijheid van toon, onmiddellijke reactie, kettingreacties, die afwezig zijn in de interpersoonlijke relaties in een echte wereld. We laten ons meeslepen op het internet voor onderwerpen die in het echte leven onschuldig zijn. We klikken graag op likes in een zoektocht naar wederkerigheid die niets zegt over onze diepgaande interesses. Hebben we het trouwens over diepe interesse voor sociale media, fora en het internet in het algemeen? Bestaat er geen vorm van digitale terughoudendheid die ons ertoe aanzet niets te zeggen over wat echt belangrijk voor ons is (met het risico te worden beoordeeld) en ons ertoe brengt de algemene opvatting te volgen dat we deel uitmaken van een grote digitale stam en zo bevestigen dat we behoren tot een collectieve beweging? Ook mogen we niet uit het oog verliezen dat de overgrote meerderheid van de gebruikers content op sociale media op passieve wijze consumeert en dat een kleine minderheid deze produceert.
 De zoektocht naar de zin van marketing vereist ook de erkenning dat de betekenis die aan online acts wordt gegeven niet noodzakelijkerwijs is wat u denkt dat het is. We mogen immers niet vergeten dat online activiteit ook een narcistische projectie is van een ideaal digitaal zelf. Fotografische enscenering op sociale media, de theatrale weergave van objecten en merken in fotografische composities die jaloezie opwekken, zijn slechts het opkomende deel van dit fenomeen. Kunnen we ons bijvoorbeeld inbeelden dat het logo van een merk een lichaamsversiering kan worden in een context zonder digitale enscenering?
De zoektocht naar de zin van marketing vereist ook de erkenning dat de betekenis die aan online acts wordt gegeven niet noodzakelijkerwijs is wat u denkt dat het is. We mogen immers niet vergeten dat online activiteit ook een narcistische projectie is van een ideaal digitaal zelf. Fotografische enscenering op sociale media, de theatrale weergave van objecten en merken in fotografische composities die jaloezie opwekken, zijn slechts het opkomende deel van dit fenomeen. Kunnen we ons bijvoorbeeld inbeelden dat het logo van een merk een lichaamsversiering kan worden in een context zonder digitale enscenering?
De Belgische kunstenaar Wim Delvoye heeft deze trend op ludieke wijze aangekaart door varkens te versieren met de logo’s van luxemerken (hier Vuitton). Is dit op artistieke wijze de spot drijven met een merkwaardige menselijke neiging om zich te willen onderscheiden? De culturele betekenis van het logo is veranderd en daarmee de toe-eigening ervan door de massa.

Verschillen tussen online en offline activiteiten
Laten we een anekdotisch voorbeeld nemen: het mijne. Ik heb verschillende passies (waaronder schilderen en mineralogie) waar ik het niet over heb op sociale netwerken. Ik heb het over heel weinig in algemene termen. Iedereen kent de 1%-regel (Engelse site), die de internetdeelnemers in twee categorieën verdeelt: degenen die actief deelnemen door het creëren van inhoud (1%) en passieve consumenten (99%). Wat mij betreft handhaaf ik mijn passies op voornamelijk passieve wijze (door te lezen) en het zou dus noodzakelijk zijn om toegang te hebben tot mijn navigatiegeschiedenis om u hiervan bewust te maken. Waarschijnlijk kunnen de cookies 2ème partie hier deels een beeld geven van wie ik werkelijk ben. Uiteindelijk zijn de passies die me ertoe gebracht hebben om een paar pagina’s op Facebook te volgen anekdotisch in vergelijking met de rest. Er is dus een kloof tussen mijn online zelf en wie ik echt ben.
We mogen ook niet vergeten dat meer dan 80% van de aankopen offline gebeurt. De kruising tussen offline en online blijft een grote uitdaging voor de retailsector van morgen (zie het artikel over trends in de retail).
De mythe van Big Data is gebaseerd op het terugbrengen van de essentie van het individu naar elementaire deeltjes bestaande uit 0 en 1.
Zwakte nr. 2: verschillen tussen voorspelling en begrip
Kan een individu worden gereduceerd tot zijn gegevens?
Hier is nog een andere misleiding geïntroduceerd door de ‘Big Data’. Omdat het individu digitale sporen achterlaat die een accuraat beeld van zijn of haar wezen zouden geven, verbergen deze gegevens het mysterie van toekomstig gedrag. Het analyseren van steeds grotere gegevens zou het dus mogelijk maken om het gedrag nog beter te voorspellen. Het individu wordt dus gelijkgesteld aan de Leibniz monade (Franse site), aan elementaire deeltjes bestaande uit 0 en 1 die zijn essentie zouden bevatten. Want daar gaat het allemaal om. Naast persoonlijkheid (waarvan we hierboven hebben gezien dat een betrouwbare analyse mogelijk is van de digitale sporen die bijvoorbeeld op sociale netwerken worden achtergelaten), belooft Big Data een begrip van de essentie van het individu. Dit voorstel is misleidend omdat de eigenheid van het individu is net zijn onvoorspelbaarheid. Zoals Dominique Cardon al aangaf, zijn voorspellingsfouten uiteindelijk slechts statistische ongelukken. De valse belofte is ook gebaseerd op een voorstel dat mijn vriend Dr. Emmanuel Tourpe als volgt omschreef: “Het individu wordt vervangen door de digitale persoon en de gemeenschap door de statistische algemeenheid”.
Het individu wordt vervangen door de digitale persoon en de gemeenschap door de statistische algemeenheid.”
Dr. Emmanuel Tourpe, ARTE
De mens begrijpen, een onmogelijke droom
Laten we niet te ver gaan met overdreven kritiek op Big Data. De digitalisering van ons leven maakt het mogelijk ons gedrag op een ongekend niveau te analyseren. Waar Charles Booth jaren werk nodig had om gegevens over de inwoners van een stad (Londen) te verzamelen, duurt het nu slechts enkele minuten om op nationaal niveau veel meer granulaire datavolumes te verzamelen. Het observeren van gedrag was nog nooit zo eenvoudig. Maar zijn we meer dan alleen maar waarnemers van een realiteit die ons ontgaat? Verkopers van Big Data zorgen ervoor dat u de intieme waarheid van menselijk gedrag kunt aanraken en de gegevens kunt gebruiken om toekomstig gedrag te voorspellen. Hoewel sommige gedragingen inderdaad voorspeld kunnen worden, blijft nederigheid toch op zijn plaats. Ten eerste kan een voorspelling slechts met beperkte nauwkeurigheid worden gedaan, er blijft een onbekend deel van complexiteit van het menselijk gedrag. Ten tweede moeten de gegevens alleen worden opgevat voor wat ze werkelijk zijn, als externe getuigen van een realiteit die mysterieus blijft. Als we de Big Data ‘analyseren’, zijn we slechts etnografen, ontdekkingsreizigers die zich een weg banen door een woud van gegevens waarvan we a priori niets weten. Het vermogen om gedrag te voorspellen, mogelijk gemaakt door moderne computermethoden, laat ons niet toe te denken dat we menselijk gedrag begrijpen. Deze blijven grotendeels ondoordringbaar, zoals blijkt uit het volgende voorbeeld.
Een concrete illustratie van de kloof tussen voorspelling en begrip
Laten we een concreet voorbeeld nemen om mijn punt te illustreren: de smartphone die ik een paar weken geleden kocht. De digitale sporen die zijn achtergelaten door het bezoeken van verschillende sites zouden het u duidelijk mogelijk hebben gemaakt tot het voorspellen van mijn interesse in het kopen van een nieuwe smartphone. De trefwoorden die ik voor mijn onderzoek heb gebruikt, zouden u ook in staat hebben gesteld om te bepalen aan welke modellen ik de voorkeur geef. Maar wat is er uiteindelijk gebeurd? Ik heb de smartphone gekocht na een bezoek aan de winkel. Het kopen ontsnapt dus aan elke poging tot verzoening (onthoud dat meer dan 80% van de aankopen offline gebeurt). En vooral, zelfs als u had kunnen voorspellen dat mijn keuze het ene of het andere model zou zijn, blijft het besluitvormingsmechanisme onbekend: Waarom heb ik besloten om van smartphone te veranderen? Welke argumenten hebben mij doen kiezen voor het ene model boven het andere?
 Deze kennis van de besluitvormingsmechanismen blijft essentieel om strategische beslissingen te nemen en de marketing te verbeteren. Het eenvoudigweg oppervlakkig observeren van gedrag zonder te proberen te begrijpen hoe het werkt, ontneemt u de hefbomen voor een betere marketing, een marketing die zinvol is. Hoe kunt u de consument, die zoals blijkt uit zijn digitale sporen twijfelt, ervan overtuigen als u niet de argumenten hebt die tot hem zullen doordringen?
Deze kennis van de besluitvormingsmechanismen blijft essentieel om strategische beslissingen te nemen en de marketing te verbeteren. Het eenvoudigweg oppervlakkig observeren van gedrag zonder te proberen te begrijpen hoe het werkt, ontneemt u de hefbomen voor een betere marketing, een marketing die zinvol is. Hoe kunt u de consument, die zoals blijkt uit zijn digitale sporen twijfelt, ervan overtuigen als u niet de argumenten hebt die tot hem zullen doordringen?
Om deze finesse van begrip te verkrijgen, lijkt het me dat andere methodologische benaderingen moeten worden gebruikt (kwantitatieve enquêtes, kwalitatieve enquêtes).
Zwakte nr. 3: verschil tussen causaliteit en correlatie
De laatste spanning die we onderzoeken, is de spanning die het gevolg is van het gebrek aan begrip van de gegevens die worden geanalyseerd. Big Data belooft verbanden te vinden tussen verspreide gegevens die te talrijk zijn om door een mens te worden onderzocht. Dankzij Big Data is elk individu nu het onderwerp van een specifiek analysemodel en dit is een fundamentele verandering in de econometrische realiteit die tot nu toe heeft geheerst. Dit vereist meer uitleg over hoe ‘voorspellingen’ in het verleden gebeurden.
Gedragsmodellering in de econometrie
Voor het bestaan van Big Data was de voorspelling van gedragingen gebaseerd op massamodellering. Men kies een voldoende grote groep van mensen, men deed aannames over de factoren die het gedrag in het algemeen beïnvloeden en de relevantie van het model is getoetst aan deze gegevens. Dit resulteerde in een voorspellingsmodel dat geldig was voor een groot aantal personen. Deze modellen waren noodzakelijkerwijs onvolmaakt omdat individuen verschillend gedrag vertonen en het ‘voorspelbare’ deel is daarom alleen het deel dat voor iedereen hetzelfde is. Toch waren deze modellen zeer nuttig omdat de zoektocht naar factoren die het gedrag beïnvloeden gebaseerd was op een eerste literatuuronderzoek en gedragsmatige verklaringen voor de rol van elke variabele.
Big Data maakt van elk individu een model op zich
Bij Big Data is de situatie heel anders. Er is niet langer sprake van een a priori model, noch van een poging tot veralgemening. Elk individu wordt een model op zich. De digitale sporen worden geanalyseerd om correlaties te genereren die gebruikt zullen worden om de toekomst te voorspellen. De correlatie is niet langer een bron van vragen over en begrip van het gedrag. Het is slechts een wiskundige relatie tussen twee variabelen waarvan we soms niets weten. Variabelen zijn niet langer een bron van vragen over de logica van gedrag. Het zijn slechts oppervlakkige sporen waarvan de betekenis ons ontgaat. Ze worden daarom geïnterpreteerd als een betekenisloos wiskundig teken, in een wanhopige poging om de waarheid naar buiten te brengen. De resultaten zijn soms grappig. Tyler Vigen heeft in een boek correlaties verzameld die de wiskundige perfectie benaderen, maar nietszeggend zijn. Zijn site Spurious Correlations (Engelse site) legt een aantal van deze afwijkingen bloot die onopgemerkt kunnen blijven in de klassieke verwerking van Big Data.
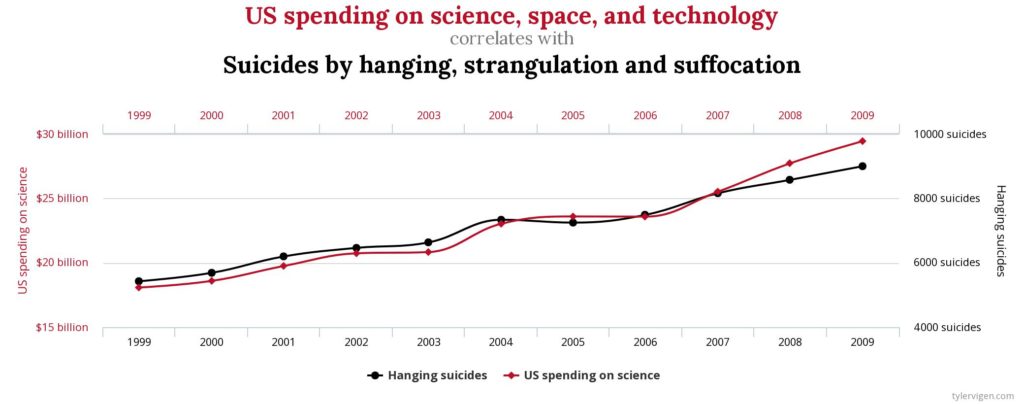
Het bovenstaande voorbeeld maakt het mogelijk om de kloof tussen twee zeer verschillende realiteiten te identificeren: de wiskundige correlatie enerzijds en de causaliteit anderzijds. Correlatie verklaart niet noodzakelijkerwijs de causaliteit. Erger nog, dit probleem wordt ondergeschikt in Big Data aangezien ons beloofd wordt dankzij wiskundige correlaties een waarheid te onthullen die ons ontgaat.
Hoe kunnen we een dosis gezond verstand vinden in de behandeling van Big Data? Dit is het onderwerp van het laatste deel van dit artikel waarin ik me afvraag welke marketingtechnieken te combineren zijn om de analyse van gedrag te verbeteren.
Voor- en nadelen van Big Data analyse voor marketingdoeleinden
Voordelen
- het benadrukken van gedrag in een grote verscheidenheid aan contexten
- bepaling van de persoonlijkheid van de gebruiker
Nadelen
- online gedrag is niet noodzakelijkerwijs de omzetting van ons offline gedrag
- de gegevens zijn slechts een oppervlakkig spoor en laten ons niet toe de redenen voor het gedrag te begrijpen
- wiskundige correlaties verklaren de causaliteit niet
Stappenplan voor het gebruik van big data in een verstandige marketingaanpak
Laten we beginnen met het samenvatten van de voor- en nadelen van het gebruik van Big Data alvorens een actieplan op te stellen om het gedrag van mensen beter te begrijpen.
Voordelen
De digitale sporen die door onze digitale activiteiten zijn achtergelaten, maken het ons mogelijk om een aantal van onze gedragingen verregaand te belichten. Zij zijn de getuigen van ons digitale leven en de weerspiegeling van bepaalde kenmerken van onze persoonlijkheid.
Nadelen
Digitale sporen maken slechts een deel uit van alles wat wij doen. Ons online gedrag vormt geen digitaal verlengstuk van de offline wereld. De interpretatie van de gegevens kan daarom alleen worden gedaan met de aanwezigheid van deze vervormende spiegel in het achterhoofd. Bovendien is een digitaal spoor slechts een oppervlakkige afdruk van een gedrag dat begrepen moet worden als een onderneming de klant wil begrijpen. Het analyseren van de sporen zonder de reden van het traject van de klant te begrijpen, neemt elk nut weg uit de daaruit voortvloeiende marketingacties. Om niet in zinloze wiskundige voorspellingen te vervallen, moeten we ons dus richten op het waarom. Om welke redenen heeft de betrokkene dit of datgene gedaan wat hem of haar ertoe heeft gebracht dit of dat spoor achter te laten?
Een actieplan voor een beter gebruik van gegevens voor marketingdoeleinden
Hoe combineert u het beste van twee werelden? Hoe kan Big Data ten volle worden benut zonder dat dit ten koste gaat van de analyse van de hierboven genoemde problemen?
De marketing van morgen kan naar mijn mening alleen worden bedacht door een combinatie van technieken enerzijds en een iteratieve aanpak anderzijds. Technologie beïnvloedt onvermijdelijk ons gedrag (spanning nr. 1) en het begrijpen van de veranderende aard van ons gedrag vereist een voortdurende herziening van de bestaande modellen. Het werk van de marketeer is dus een oneindige lus die bestaat uit de volgende elementen:
- Studie van wat bestaat: wat is er al bekend over het te bestuderen gedrag? Zijn er modellen die factoren kunnen identificeren die het gedrag beïnvloeden?
- Gegevensanalyse met behulp van bestaande modellen : bevestigen de gegevens die ik heb verzameld de bestaande modellen en zo ja, in welke mate? Het is op dit niveau dat bestaande gegevens moeten worden verkend (business intelligence).
- Analyse van de ‘gaten’ in het model : hoe verklaar ik het deel van het gedrag dat ik niet kan verklaren op basis van bestaande gegevens? In deze fase moeten we ons twee vragen stellen: ten eerste over de nog onbekende invloedsfactoren; ten tweede over de betekenis van de invloedsfactoren waarmee in het model rekening wordt gehouden. Dit is het moment voor kwalitatief onderzoek dat gericht is op het diepgaand onderzoeken van gedrag en het geven van betekenis aan acties.
- Verzamelen van ontbrekende gegevens : welke maatregelen moeten worden genomen om ontbrekende gegevens te verzamelen en te verfijnen? Dit is een ‘zakelijke’ reflectie die moet leiden tot het vastleggen van ontbrekende gegevens.
Het is de bedoeling dat deze cyclus zich blijft herhalen. Het werk van de marketeer wordt zo een eeuwige herstart.
Heeft u vragen, opmerkingen? Twijfel niet om contact met mij op te nemen of mij uit te nodigen om deze presentatie aan uw publiek voor te stellen.
Bronnen
- Les échos
- EMC
- Statista
- Kosinski, M., Bachrach, Y., Kohli, P., Stillwell, D., & Graepel, T. (2014). Manifestations of user personality in website choice and behaviour on online social networks. Machine learning, 95(3), 357-380.
- Latzko-Toth, G., Bonneau, C., & Millette, M. (2017). Small data, thick data: Thickening strategies for trace-based social media research. The SAGE handbook of social media research methods, 199-214.
- Thompson, C. J. (2019). The ‘big data’myth and the pitfalls of ‘thick data’opportunism: on the need for a different ontology of markets and consumption. Journal of Marketing Management, 35(3-4), 207-230.
- Youyou, W., Kosinski, M., & Stillwell, D. (2015). Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4), 1036-1040.
Afbeeldingen: shutterstock, Canadahistory


