

Le progrès technologique nous permet aujourd’hui de profiter de conditions de vie incomparables. Maîtrise de l’espace, maîtrise de la reproduction, maîtrise de l’information sont des défis déjà relevés. La maîtrise du temps reste toutefois hors d’atteinte. Beaucoup des obsessions des Humains tournent autour de la maîtrise de cette ressource qui nous est offerte à notre naissance en une quantité désespérément finie : le temps. Rester jeune, vivre vieux, perpétuer sa mémoire, prédire le futur sont quelques unes des formes que prend cette obsession. Ce refus d’une réalité biologique semble d’ailleurs répondre à une règle mystérieuse que les scientifiques ne s’expliquent pas. La transformation digitale de nos vies offre une opportunité de résoudre un de ces problèmes : l’anticipation de l’avenir. C’est ce que je vous propose d’examiner dans cet article
Dans cet article, mon propos se structurera autour de 3 lignes directrices. Je vais tout d’abord montrer que la prédiction est une pratique ancienne et que la digitalisation de nos vies nous offre une opportunité unique de prédire l’avenir. Je vais ensuite mettre en exergue les limitations conceptuelles de l’analyse par les Big Data. Pour finir je proposerai un plan d’action pour intégrer le Big Data dans une démarche marketing et d’étude des comportements. Cette démarche intégrera des techniques d’étude de marché classiques.
Note : cet article sert de référence à mon intervention du 6 Décembre 2019 au congrès annuel de la Belgian Association of Marketing (voir présentation ci-dessous).
Sommaire
- Prédire l’avenir : une obsession à toutes les époques
- Les données à la base de meilleures prédictions
- Une vie de plus en plus digitalisée
- Tension entre marketing qualitatif et marketing quantitatif
- Les 3 faiblesses méthodologiques du Big Data
- Comment utiliser le Big Data pour un marketing qui a du sens
- Sources
Prédire l’avenir une obsession ancienne

Prédire l’avenir est une activité quotidienne depuis des temps immuables. L’objectif de la prédiction est bien entendu d’influer sur le cours du temps pour en retirer un bénéfice collectif ou individuel : meilleures récoltes, plus de richesses, perpétuation du nom grâce la descendance. L’être humain semble avoir un problème avec l’incertitude et a donc cherché de tout temps à se rassurer : oracles au service du pharaon dans l’Égypte ancienne, augures de toutes les formes de pouvoir dans la Rome antique.
Cette tradition de divination et de prédiction de l’avenir se perpétue aujourd’hui à une échelle jamais vue grâce à aux horoscopes. 12% des Américains le lisent chaque jour, 32% de manière plus occasionnelle et 26% croient à l’astrologie. Le besoin de connaître l’avenir s’adapte à chaque époque et à chaque culture. Les résultats, vous en conviendrez, restent toutefois aléatoires.
26% des Américains croient à l’astrologie.
La technologie permet néanmoins de parvenir, mieux que jamais, à anticiper l’avenir. La révolution du Big Data associée à des capacités de stockage et de calcul toujours moins chères, rendent le traitement de l’information plus abordable et la compréhension des phénomènes naturels et humains meilleure que jamais. En 2003 déjà on estimait qu’en 20 ans, les progrès technologiques avaient permis de gagner deux jours sur les prévisions météo, en moyenne. Au train où les données s’accumulent, il est raisonnable de penser que les prédictions ne peuvent que s’améliorer.

La multiplication des données à la base de meilleures prédictions
Au risque de vous ressasser des chiffres déjà connus, essayons de comprendre les conséquences de la digitalisation de nos vies en quelques statistiques :
- le volume total des données disponibles serait de 40 Zb, ce qui correspond à quarante mille milliards de Gigabytes. Voici ce que cela représente en chiffes : 40,000,000,000,000 Gb.
- En 2017, 90% des données avaient été créées dans les 2 ans précédents
- 57% des humains ont accès à internet (en hausse de 9,9% par rapport à 2018) et 2.5 quintillion bytes sont générés chaque jour sur internet
- 33% du temps passé sur internet l’est sur les médias sociaux
- le nombre d’objets connectés sera multiplié par 3 dans les 6 prochaines années
 entre 2015 et 2025")
Le volume de données disponibles ne fera donc qu’enfler, documentant un peu plus chaque interaction humaine, et mettant un peu plus au jour chaque recoin de nos comportements. Avec autant de données, il devient dès lors évident que nos actions pourront de plus en plus être disséquées, comparées et bien entendu prédites.
Les médias sociaux représentent 33% du temps passé sur internet.
Une vie de plus en plus digitale, une aubaine pour les marketeurs
Nos vies sont de plus en plus digitales et le marketing moderne, dans sa quête de sens (« meaningfulness »), voit dans les données une terre promise, un paradis qui lui permettra de réaliser SON rêve d’antan, celui d’une relation personnalisée avec chacun des clients de l’entreprise.

Comme dans la ruée vers l’or en Californie au XIXème siècle, ceux qui se sont enrichis ne sont pas forcément ceux qu’on croit. Remplacez les pépites d’or par les données (« the new oil »), remplacez les « general stores » par les vendeurs de solutions cloud, et vous obtenez un parallèle intéressant pour regarder le phénomène du Big Data sous un angle nouveau.
 lors de la ruée vers l'or en Californie au XIXème siècle")
La promesse de comportements tout entiers numérisés permet au marketing de faire sa mue. De science sociale (une science « molle » comme l’appellent les Français) le marketing se pare d’atours statistiques, mathématiques, et entame une mue qui, il l’espère, lui permettra de se transformer en science dure. La chenille rêve d’un avenir en papillon.
Il nous faut toutefois nous interroger sur la pertinence de cette transition vers le « tout data ». Le marketing en tant que science centrée sur la compréhension et la satisfaction des besoins des clients, peut-elle n’être qu’orientée données ?
Tension sous-jacente entre recherche qualitative et recherche quantitative
Cette question est le reflet de la tension qui existe depuis des décennies entre recherche qualitative et recherche quantitative. Les seconds disent aux premiers que le quantitatif se suffit à lui-même, quand les premiers rétorquent que la compréhension des comportements ne peut passer que par une étude qualitative. Cette opposition, stérile, a donné lieu à des tentatives de médiation sous la forme par exemple du concept de « thick data ». Le « thick data » c’est la réponse formulée aux sceptiques qui promet d’augmenter la pertinence des résultats du Big Data grâce à des insights issus de la recherche qualitative (voir Latzko-Toth et al., 2017).
Comme le souligne Thompson (2019) le « mythe du Big Data est qualitativement différent de son pendant quantitatif über alles » (traduction libre de l’anglais). Les techniques quantitatives étaient brandies, au XXème siècle, comme des méthodes positivistes permettant d’échapper au caractère aléatoire et intuitif des techniques qualitatives. Aujourd’hui le Big Data renforce cette vision empirique en y ajoutant une rhétorique techno-utopique (Thompson 2019). Cette vision place le Big Data comme réponse unique, rejetant dès lors la légitimité d’autres approches.
Le « thick data » est une proposition pour augmenter la pertinence des résultats du Big Data grâce à des insights issus de la recherche qualitative.
Ce discours radical nous oblige à en explorer les limites afin que l’analyse des traces numériques puisse être utilisée de la meilleure manière possible. Je vous propose d’examiner 3 zones de tensions qui nous permettront de nous interroger sur la place véritable du Big Data dans l’analyse des comportements humains.

Faiblesse n°1 : la différence entre les activités en ligne et le comportement hors ligne
Le mythe du Big Data repose sur une hypothèse fallacieuse : nos comportements en ligne seraient le reflet de notre comportement dans le monde réel. Notre activité sur les médias sociaux est jugée comme étant un moyen simplement différent d’exprimer et de partager leurs préférences.
Personnalité et comportements online
Les études sont désormais légion qui établissent une corrélation entre activité online et la personnalité. Kosinski et al. (2015) ont par exemple montré que les sites web fréquentés et les activités sur Facebook permettaient de déduire la personnalité de l’internaute. Youyou et al. (2015) sont allés un cran plus loin en affirmant que l’évaluation de la personnalité à partir de l’activité sur Facebook était plus précise que celle faite par des humains. Ce dernier article a d’ailleurs eu un retentissement certain dans la presse grand public qui s’est empressée de déclarer que Facebook comprenait mieux ses utilisateurs que leur propre famille. Les traits de personnalité, s’ils peuvent être révélés par mon activité online, ne disent pas tout de moi. La personnalité n’est qu’une partie de ce qui constitue un être humain. Cela nous mène à examiner un 2ème axe de tenson : les différences entre mon moi numérique et qui je suis vraiment.
Mise en scène et théâtralisation online
Il existe à l’évidence une différence entre mon pendant numérique et qui je suis vraiment ; mes comportements online ne sont pas forcément le miroir de mon réel. Internet permet une liberté de ton, une immédiateté de réaction, des réactions en chaîne, qui sont absentes des relations interpersonnelles dans un monde réel. On s’emporte sur Internet pour des sujets qui ne revêtent qu’un caractère anodin dans la vraie vie. On met des´« like » pour faire plaisir, dans une quête de réciprocité qui ne dit rien de nos intérêts profonds. D’ailleurs, parle-t-on de ses intérêts profonds sur les médias sociaux, sur les forums, sur internet en général ? N’y a-t-il pas une forme de retenue digitale qui nous pousse à ne rien dire de ce qui nous tient vraiment à cœur (au risque d’être jugé) et nous conduit à suivre l’opinion générale pour faire partie d’une grande tribu digitale et affirmer ainsi notre appartenance à une mouvance collective. Ne perdons pas de vue non plus que l’écrasante majorité des utilisateurs consomme passivement du contenu sur les médias sociaux et qu’une infime minorité en produit.
 La quête de sens du marketing passe également par la reconnaissance que le sens donné aux actes online n’est pas forcément celui qu’on croit. Gardons en effet à l’esprit que l’activité online est aussi une projection narcissique d’un moi numérique idéal. Les mises en scène photographiques sur les médias sociaux, la théâtralisation des objets et des marques dans des compositions photographiques pensées pour susciter la jalousie, ne sont que la partie émergée de ce phénomène. Peut-on par exemple imaginer que le logo d’une marque devienne une décoration corporelle dans un mode où la mise en scène numérique serait absente ?
La quête de sens du marketing passe également par la reconnaissance que le sens donné aux actes online n’est pas forcément celui qu’on croit. Gardons en effet à l’esprit que l’activité online est aussi une projection narcissique d’un moi numérique idéal. Les mises en scène photographiques sur les médias sociaux, la théâtralisation des objets et des marques dans des compositions photographiques pensées pour susciter la jalousie, ne sont que la partie émergée de ce phénomène. Peut-on par exemple imaginer que le logo d’une marque devienne une décoration corporelle dans un mode où la mise en scène numérique serait absente ?
L’artiste belge Wim Delvoye s’est d’ailleurs habilement gaussé de cette tendance en parant des cochons de logos de marques de luxe (ici Vuitton). Fait-il y voir un geste artistique qui tourne en dérision une curieuse tendance humaine à vouloir se différencier ? La signification culturelle du logo a changé et avec elle l’appropriation que s’en s’ont faite les masses.

Différences entre l’activité online et l’activité offline
Prenons un exemple anecdotique : le mien. J’ai plusieurs passions (dont la peinture et la minéralogie) dont je ne parle pas sur les réseaux sociaux. Je ne parle de manière générale que de peu de choses d’ailleurs. Tout le monde connaît la règle du 1%, qui divise les participants à l’internet en deux catégories : ceux qui participent activement par la création de contenu (1%), et les consommateurs passifs (les 99%). En ce qui me concerne j’entretiens mes passions de manière surtout passive (par la lecture) et il faudrait donc avoir accès à mon historique de navigation pour vous en rendre compte. Sans doute les cookies de 2ème partie peuvent ici livrer une image parcellaire de qui je suis vraiment. Au final les passions qui me valent de suivre quelques pages sur Facebook sont anecdotiques au regard du reste. Il y a donc un décalage entre mon moi online et mon moi réel.
Il faut également se souvenir que plus de 80% des achats sont réalisés offline. La jonction entre le offline et le online reste d’ailleurs un défi majeur du retail de demain (voir à ce sujet l’article consacré aux tendances du retail).
Le mythe des Big Data repose sur la décomposition de l’essence de l’individu en particules élémentaires composées de 0 et de 1
Faiblesse n°2 : différences entre prédiction et compréhension
L’individu peut-il être réduit à ses données ?
Voici une autre tromperie introduite par le « Big Data ». Puisque l’individu laisse derrière lui des traces numériques qui donneraient un aperçu exact de son être, ces données recèlent le mystère de ses comportements futurs. Analyser des données toujours plus volumineuses permettrait donc de prédire toujours mieux le comportement. L’individu est donc assimilé à la monade de Leibniz, à des particules élémentaires composées de 0 et de 1 qui contiendraient son essence. Car c’est bien de cela qu’il s’agit. Au-delà de la personnalité (dont on a vu plus haut qu’une analyse fiable était possible à partir des traces numériques laissées par exemple sur les réseaux sociaux), les Big Data promettent une compréhension de l’essence de l’individu. Cette proposition est fallacieuse car le propre de l’individu est bien son caractère imprévisible. Comme le rappelait Dominique Cardon, les erreurs de prédiction ne sont au final que des accidents statistiques. La fausse promesse repose aussi sur une proposition que mon ami le Dr. Emmanuel Tourpe décrivait ainsi : « la personne est remplacée par l’individu numérique et la communauté par la généralité statistique ».
La personne est remplacée par l’individu numérique et la communauté par la généralité statistique
Dr. Emmanuel Tourpe, ARTE
Comprendre l’être humain, un rêve inaccessible
Ne tombons pas dans la critique excessive des Big Data. La digitalisation de nos vies permet un niveau d’analyse encore inégalé de nos comportements. Là où il a fallu des années de travail à Charles Booth pour collecter des données sur les habitants d’une ville (Londres), quelques minutes suffisent désormais pour recueillir des volumes de données largement plus granulaires à l’échelle d’un pays. L’observation des comportements n’a donc jamais été aussi aisée. Mais sommes-nous plus que de simples observateurs d’une réalité qui nous échappe ? Les vendeurs de Big Data vous assureront que vous pourrez toucher du doigt l’intime vérité du comportement humain, utiliser les données pour prédire les comportements futurs. Si une part des comportements pourra en effet être prédite, il faut savoir rester humble. Premièrement la prédiction ne peut se faire qu’avec une précision limitée, une part d’inconnu propre à la complexité du comportement humain. Deuxièmement, les données ne devraient être prises que pour ce qu’elles sont vraiment, c’est-à-dire des témoins extérieurs d’une réalité qui demeure mystérieuse. Lorsque nous « analysons » les Big Data, nous ne sommes que des ethnographes, des explorateurs nous frayant un chemin à travers une forêt de données dont nous ne savons rien a priori. La capacité de prédiction des comportements, rendue possible par les moyens de calculs modernes, ne nous autorise pas à penser que nous comprenons les comportements humains. Ces derniers restent largement impénétrables comme le montre l’exemple suivant.
Une illustration concrète du fossé entre prédiction et compréhension
Prenons un exemple concret pour illustrer mon propos : celui du smartphone que j’ai acheté il y a quelques semaines. Les traces numériques laissées par la visite de différents sites vous auraient clairement amenés à prédire mon intérêt pour l’achat d’un nouveau smartphone. Les mots-clés utilisés pour mes recherches vous auraient également permis de conclure quels modèles avaient ma préférence. Mais au final, qu’est-il arrivé ? J’ai acheté le smartphone après une visite en magasin. L’acte d’achat échappe donc à toute tentative de réconciliation (rappelez-vous que plus de 80% des achats se font hors-ligne). Et surtout, même si vous aviez pu prédire que mon choix aller se porter sur l’un ou sur l’autre modèle, le mécanisme décisionnel restera inconnu : Pourquoi ai-je décidé de changer de smartphone ? Quels arguments m’ont fait pencher pour un modèle plutôt qu’un autre ?
 Cette connaissance des mécanismes décisionnels demeure indispensable pour prendre des décisions stratégiques et améliorer son marketing. Se contenter d’une observation superficielle des comportements sans chercher à en percer le fonctionnement, vous prive de leviers d’action pour un meilleur marketing, un marketing qui fasse sens. Comment pourriez-vous convaincre le consommateur que vous voyez hésiter, sur base de ses traces numériques, si vous ne disposez pas des arguments qui résonneront en lui ?
Cette connaissance des mécanismes décisionnels demeure indispensable pour prendre des décisions stratégiques et améliorer son marketing. Se contenter d’une observation superficielle des comportements sans chercher à en percer le fonctionnement, vous prive de leviers d’action pour un meilleur marketing, un marketing qui fasse sens. Comment pourriez-vous convaincre le consommateur que vous voyez hésiter, sur base de ses traces numériques, si vous ne disposez pas des arguments qui résonneront en lui ?
Pour acquérir cette finesse de compréhension il me semble que d’autres approches méthodologiques doivent être mises en jeu (sondages quantitatifs, enquêtes qualitatives).
Faiblesse n°3 : différence entre causalité et corrélation
La dernière tension qu’il nous faut aborder est celle qui découle du manque de compréhension des données qui sont analysées. Les Big Data promettent de trouver des corrélations entre des données éparses et trop nombreuses pour être examinées par un humain. Grâce au Big Data chaque individu fait désormais l’objet d’un modèle d’analyse spécifique et ceci est un changement fondamental de la réalité économétrique qui prédominait jusqu’alors. Ceci nous oblige à expliquer comment les « prédictions » étaient réalisées dans le passé.
La modélisation des comportements en économétrie
Avant les Big Data la prédiction des comportements se basait sur une modélisation de masse. On prenait un ensemble suffisamment grand d’individus, on émettait des hypothèses sur les facteurs qui influençaient le comportement en général, et on vérifiait la pertinence du modèle à l’aune de ces données. On obtenait donc un modèle de prédiction valable pour un grand nombre d’individus. Forcément ces modèles étaient imparfaits puisque les individus ont des comportements différents les uns des autres, et la partie « prédictible » n’est donc que celle qui est commune à tous. N’empêche que ces modèles étaient bien utiles car la recherche des facteurs influençant le comportement se basait sur une recherche préalable de la littérature et sur des explications comportementales du rôle de chaque variable.
Les Big Data font de chaque individu un modèle en soi
Avec les Big Data la situation est tout à fait différente. Il n’y a plus de modèle a priori, ni de tentative de généralisation. Chaque individu devient un modèle en soi. Ses traces numériques sont analysées de façon à faire surgir des corrélations qui serviront à prédire le futur. La corrélation cesse d’être source d’interrogation et de compréhension du comportement. Elle n’est qu’une relation mathématique entre deux variables dont on ignore parfois tout. Les variables ne sont plus sources d’interrogation sur la logique du comportement. Elles sont juste des traces superficielles dont la signification nous échappe. Elles sont donc interprétées en tant que signe mathématique non signifiant, dans une tentative désespérée de faire émerger la vérité. Les résultats sont parfois cocasses. Tyler Vigen a réuni dans un livre des corrélations proches de la perfection mathématique mais dénuées de sens. Son site Spurious Correlations expose certaines de ces aberrations qui pourraient passer inaperçues dans un traitement Big Data classique.
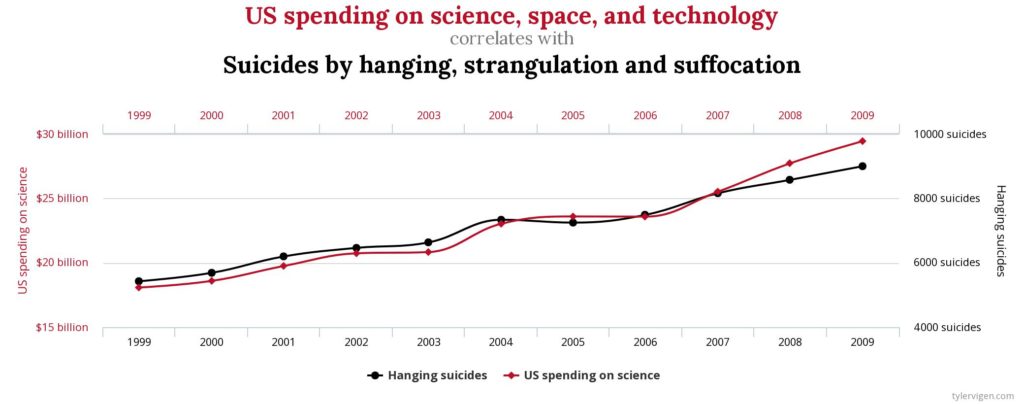
L’exemple ci-dessus permet de toucher du doigt le fossé qui sépare deux réalités bien différentes : la corrélation mathématique d’une part, et la causalité d’autre part. La corrélation ne permet pas forcément d’expliquer la causalité. Pire, ce problème devient secondaire dans les Big Data puisqu’on nous promet de révéler une vérité qui nous échappe grâce aux corrélations mathématiques.
Comment dès lors retrouver dans le traitement des Big Data une dose de bon sens ? C’est l’objet de la dernière partie de cet article dans laquelle je m’interroge sur les techniques marketing à combiner pour améliorer l’analyse des comportements.
Avantages et inconvénients de l’analyse Big Data à des fins marketing
Avantages
- mise en lumière de comportements dans une grande variété de contextes
- détermination de la personnalité de l’utilisateur
Inconvénients
- les comportements online ne sont pas forcément la transposition de nos comportements offline
- les données ne sont qu’une trace superficielle et ne permettent pas de comprendre le pourquoi des comportements
- les corrélations mathématiques n’expliquent pas la causalité
Feuille de route pour une utilisation des big data dans une démarche marketing sensée
Commençons par résumer les avantages et les inconvénients de l’utilisation des Big Data avant d’esquisser un plan d’action pour mieux comprendre le comportement des individus.
Avantages
Les traces numériques laissées par nos activités numériques permettent d’éclairer en profondeur une partie de nos comportements. Elles sont les témoins de notre vie digitale et le reflet de certains traits de notre personnalité.
Inconvénients
Les traces numériques ne témoignent que d’une partie de nos activités. Nos comportements online ne sont en outre pas des extensions digitales du monde offline. L’interprétation des données ne peut donc se faire qu’en gardant à l’esprit la présence de ce miroir déformant. De plus une trace numérique n’est que l’empreinte superficielle d’un comportement qui doit être compris si l’entreprise veut avoir une prise sur le client. Analyser les traces sans comprendre le pourquoi du cheminement du client, c’est retirer tout leur sens aux actions marketing qui en découlent. Pour ne pas tomber dans la prédiction mathématique dénuée de sens, il faut donc s’intéresser à la causalité. Quelles raisons ont poussé l’individu à poser tel ou tel acte qui l’a conduit à laisser telle ou telle trace ?
Un plan d’action pour une meilleure utilisation des données à des fins marketing
Comment combiner le meilleur des deux mondes ? Comment utiliser les Big Data au maximum de leur potentiel sans toutefois compromettre l’analyse par les problèmes mis en exergue auparavant ?
Le marketing de demain ne peut se concevoir, à mon sens, qu’à travers une combinaison de techniques d’une part, et par une approche itérative d’autre part. La technologie influence forcément nos comportements (tension n°1) et comprendre la nature changeante de ces derniers requiert forcément de réexaminer en permanence les modèles existants. Le travail du marketeur est donc une boucle infinie constituée des éléments suivants :
- Étude de l’existant : quel sait-on déjà sur le comportement à étudier ? Des modèles existent-ils qui permettent d’identifier des facteurs influençant le comportement ?
- Analyse des données à l’aune des modèles existants : les données que j’ai récoltées confirment-elles les modèles existants et si oui dans quelle proportion ? C’est à ce niveau que les données existantes doivent être explorées (business intelligence)
- Analyse des « trous » dans le modèle : comment expliquer la part de comportement que je n’arrive pas à expliquer sur la base des données existantes ? A ce stade il faut doublement s’interroger : d’abord sur les facteurs d’influence qui sont encore inconnus; ensuite sur la signification des facteurs d’influence pris en compte dans le modèle. C’est le temps de la recherche qualitative qui vise à explorer en profondeur les comportements et à donner un sens aux actions.
- Collecte de données manquantes : quelles actions mettre en place pour collecter les données manquantes afin d’affiner ? Il s’agit d’une réflexion « business » qui doit conduire à la captation des données manquantes.
Ce cycle est appelé à se répéter. Le travail du marketeur devient donc un éternel recommencement.
Des questions, des remarques ? N’hésitez pas à me contacter ou à m’inviter pour redonner cette présentation à votre audience.
Sources
- Les échos
- EMC
- Statista
- Kosinski, M., Bachrach, Y., Kohli, P., Stillwell, D., & Graepel, T. (2014). Manifestations of user personality in website choice and behaviour on online social networks. Machine learning, 95(3), 357-380.
- Latzko-Toth, G., Bonneau, C., & Millette, M. (2017). Small data, thick data: Thickening strategies for trace-based social media research. The SAGE handbook of social media research methods, 199-214.
- Thompson, C. J. (2019). The ‘big data’myth and the pitfalls of ‘thick data’opportunism: on the need for a different ontology of markets and consumption. Journal of Marketing Management, 35(3-4), 207-230.
- Youyou, W., Kosinski, M., & Stillwell, D. (2015). Computer-based personality judgments are more accurate than those made by humans. Proceedings of the National Academy of Sciences, 112(4), 1036-1040.
Images d’illustration : shutterstock, Canadahistory




