

Gli algoritmi sono sempre più utilizzati per essere di supporto agli esseri umani nelle loro decisioni. Un algoritmo mal programmato, o esseri umani privi di capacità di pensiero critico, sono cause ricorrenti di errori algoritmici. Questi errori a volte scatenano la rabbia degli utenti o li incitano a hackerarli. Questo articolo analizza 6 errori algoritmici che hanno avuto conseguenze dannose sull’uomo. Il 4° esempio è particolarmente grave perché ha colpito migliaia di persone e causato danni irreparabili (suicidi, separazioni, debiti ingiustificati).

Un arresto basato su un’errata identificazione algoritmica (riconoscimento facciale)
Gli algoritmi di riconoscimento facciale si sono infiltrati in ogni angolo della nostra vita privata (sblocco dello smartphone, ricerca inversa di Google,…) ma anche in ambito professionale. La polizia americana utilizza questo tipo di algoritmo da 20 anni.
Il primo caso di errore dovuto ad un algoritmo di riconoscimento facciale risale al 2020 quando la polizia di Farmington Hills (MI) arrestò Robert Julian-Borchak. Questo uomo di colore di 41 anni è stato trattenuto per 30 ore sulla base del riconoscimento facciale prodotto da un algoritmo di bassa qualità. Questo caso è sintomatico degli abusi che ci si può aspettare quando una cattiva tecnologia viene messa nelle mani di operatori che non esercitano un giudizio critico sulla probabilità di un falso positivo.
Cosa si può imparare da questo errore algoritmico?
Non tutti gli algoritmi sono ugualmente efficaci. Questa ricerca ha mostrato che l’etnia era un fattore molto importante nell’errore degli algoritmi di riconoscimento facciale. Le persone con la pelle nera e gli asiatici sono le più soggette a errori algoritmici: da 10 a 100 volte di più rispetto alle persone di origine caucasica.
La qualità dei risultati dipende, in particolare, dai dati di allenamento utilizzati. Il lavoro di Joy Buolamwini ha evidenziato i pregiudizi nei set di dati di formazione. La sottorappresentanza delle minoranze etniche porta a errori più grandi in questi gruppi.

Screening algoritmico non riuscito per i candidati inquilini

La scelta di un inquilino è un momento critico per un proprietario. 9 proprietari su 10 negli Stati Uniti si affidano a sistemi automatizzati per ottenere informazioni sui richiedenti noleggio. Un sondaggio mostra che gli algoritmi che elaborano i dati commettono errori grossolani. Le persone sono confuse; i match vengono fatti tra persone diverse in base ai loro cognomi.
Le conseguenze sono disastrose poiché alle persone soggette a questo erroneo giudizio algoritmico viene negato l’accesso agli affitti.

Il sondaggio sopra citato fornisce un esempio di rapporto algoritmico per un richiedente noleggio. Mostra un punteggio (da 0 a 100) su cui il titolare basa la sua decisione. Il rapporto indica che il punteggio viene calcolato utilizzando le informazioni fornite dai precedenti proprietari, informazioni pubbliche e un rapporto di credito. La natura di queste informazioni pubbliche non è menzionata, né il metodo di calcolo di questo punteggio. La partitura è, quindi, opaca.
Cosa si può imparare da questo errore algoritmico?
Si possono apprendere due lezioni:
- La qualità e la preparazione dei dati sono fattori chiave per il successo. In questo caso, il processo di disambiguazione presenta carenze incredibili. I dati vengono riconciliati in base al cognome solo quando le persone possono essere diverse. Questo livello di dilettantismo è incredibile.
- L’opacità del punteggio e dei dati raccolti non consente al titolare di giudicare criticamente la qualità della raccomandazione algoritmica. Se possibile, la raccomandazione dovrebbe essere spiegata per essere accettata.

Gli studenti sono sanzionati sulla base di sospetti algoritmici
La pandemia di Covid e i lockdown che ne sono seguiti hanno avviato una fortissima digitalizzazione dell’istruzione. Le lezioni venivano impartite tramite computer e gli studenti potevano sostenere gli esami a distanza. Il rischio di copiare è aumentato.
Alcuni comportamenti innocui possono essere ritenuti sospetti e squalificare uno studente. Le aziende propongono soluzioni algoritmiche che dovrebbero rilevare comportamenti rischiosi e avvisare gli insegnanti dei rischi di barare. Come mostra il caso di questo studente della Florida, i risultati dell’algoritmo di Honorlock sono tutt’altro che convincenti. L’errore algoritmico, in questo caso, è il prodotto di un’errata interpretazione del comportamento dello studente davanti alla telecamera.
Cosa si può imparare da questo errore algoritmico?
Spesso con gli algoritmi, una progettazione difettosa può solo portare al disastro. L’algoritmo di Honorlock introduce diversi pregiudizi interpretativi nel comportamento imbroglione accademico. L’analisi dell’algoritmo si basa su regole rigide e all’insegnante viene fornito un punteggio. La mancanza di sfumature nel calcolo del punteggio, e l’opacità del metodo di calcolo, portano a giudizi che possono essere devastanti.

Uso illegale di un algoritmo di targeting da parte delle autorità fiscali olandesi
In questo caso, il cosiddetto “toeslagenaffaire” (caso assistenziale), le vite di migliaia di famiglie beneficiarie di prestazioni assistenziali sono state rovinate a causa di un algoritmo utilizzato illegalmente dal fisco per identificare i truffatori. Il numero delle vittime è stimato in 2200, con una perdita media di 30.000€. In alcuni casi il danno per il contribuente è stato superiore a 150.000€. Alcune persone si sono suicidate per disperazione, più di mille bambini sono stati sottratti ai genitori e milioni di euro sono stati indebitamente rimborsati allo Stato.
Le autorità fiscali olandesi hanno attraversato diverse linee rosse con il loro algoritmo e il modo in cui hanno interpretato i risultati:
- l’algoritmo ha identificato potenziali casi di frode e le autorità fiscali hanno applicato ingiustificatamente una regola di Pareto: 80% fraudolento / 20% innocente per continuare le indagini
- Il targeting era in parte basato sulla seconda nazionalità del contribuente. Le autorità fiscali non disponevano di basi legali per l’analisi di questa variabile. Da un audit realizzato nel 2020 è emerso che altri 4 algoritmi antifrode delle autorità fiscali utilizzavano indebitamente questa variabile.
Il caso è estremamente grave e gli abusi del fisco olandese sono stati severamente sanzionati dal Garante per la protezione dei dati personali, che ha inflitto una sanzione di 3,6 milioni di euro.
Cosa si può imparare da questo errore algoritmico?
Si possono apprendere 3 lezioni:
- Le variabili utilizzate da un algoritmo per eseguire il suo calcolo devono avere una base giuridica
- Alcune variabili possono essere utilizzate solo se hanno un nesso causale con il risultato atteso. Nel “toeslagenaffaire”, non c’era alcuna base empirica per dimostrare che la seconda nazionalità fosse una causa di frode.
- I risultati forniti da un algoritmo di targeting dovrebbero essere considerati per quello che sono, ovvero ipotesi di lavoro. Nell’applicare la regola 80/20, i funzionari delle tasse olandesi sono stati colpevolmente negligenti e dilettanti.

Algoritmo parziale per l’orientamento degli studenti nell’istruzione superiore
Il caso dell’algoritmo di selezione delle università francesi è scoppiato nel 2016. L’algoritmo, chiamato APB, ha consentito alle università di selezionare studenti provenienti dalle scuole superiori. Le variabili utilizzate da questo algoritmo per decidere il destino degli studenti sono state mantenute segrete fino a quando un avvocato ha citato in giudizio il Ministero dell’Istruzione. Si è poi scoperto che le variabili utilizzate non avevano base giuridica. Peggio ancora, alcune variabili utilizzate nel calcolo dell’algoritmo erano discriminatorie (età, paese di origine) o incongrue (terzo nome). Il numero di “vittime” di questo algoritmo è sconosciuto, ma possiamo legittimamente pensare che migliaia di studenti siano stati svantaggiati da scelte algoritmiche contro il loro miglior giudizio.
Cosa si può imparare da questo errore algoritmico?
I pregiudizi di programmazione dell’algoritmo APB sono evidenti. L’algoritmo non è stato progettato per massimizzare gli interessi degli studenti che accedono all’istruzione superiore, ma piuttosto quelli delle università.
L’algoritmo APB è, infatti, una semplice formula di “regola aziendale”. Le variabili prese in considerazione non mostrano alcun nesso di causalità con un obiettivo benefico per lo studente. Ad esempio, sarebbe stato molto più rilevante considerare le variabili che massimizzano il tasso di successo degli studenti universitari. L’algoritmo perfetto avrebbe potuto proporre allo studente la scelta migliore per avere successo, lasciando allo studente la libertà di scegliere una soluzione meno valida (ad esempio, una scuola più vicina a casa).

Censura dei contenuti da parte dell’algoritmo di Tik Tok
L’algoritmo di raccomandazione è una pietra angolare del successo di Tik Tok. L’algoritmo è programmato per nascondere i contenuti relativi all’omosessualità, alcuni argomenti politicamente sensibili e personaggi pubblici. La piattaforma di origine cinese è stata accusata di abbassare artificialmente la visibilità dei contenuti pubblicati dalla comunità LGBTQ+. Questa esclusione algoritmica è ben articolata in questa ricerca qualitativa. Un rapporto di audit dell’Aspi (Australian Strategic Policy Institute) mostra che le parole chiave identificate dagli hashtag sono censurate su TikTok. Apprendiamo dal Guardian che a giugno 2020 era stata stilata una lista di 20 personalità che non dovrebbero apparire su TikTok. Tra questi troviamo Kim Jong-il, Kim Jong-Un, Vladimir Putin e Donald Trump.
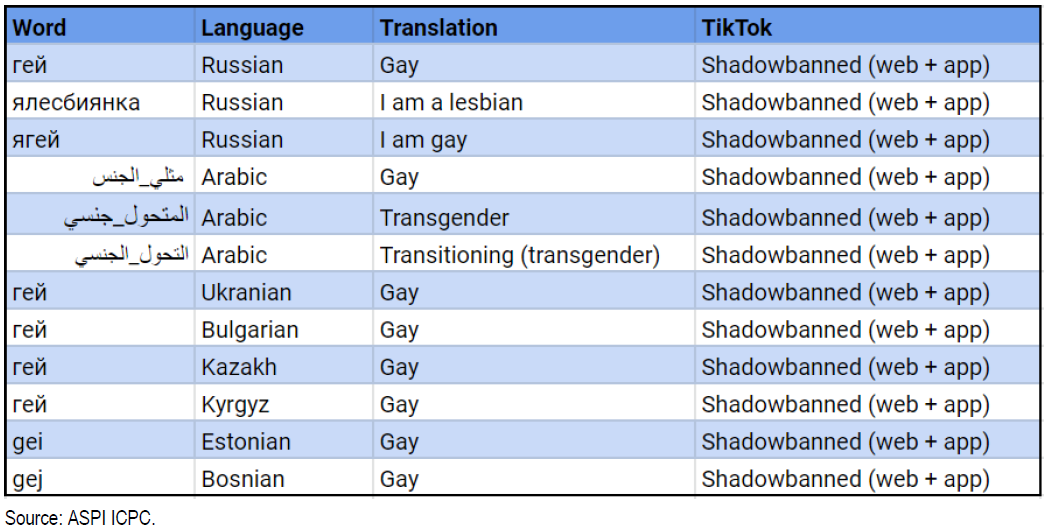
Cosa si può imparare da questo errore algoritmico?
Il caso dell’algoritmo di TikTok è forse il meno probabile che sia un errore algoritmico. L’algoritmo ha agito esattamente come volevano i suoi progettisti censurando determinati contenuti. È, quindi, in definitiva un pregiudizio umano che ha portato alla programmazione “diretta” dell’algoritmo.




