
Algorithmen werden zunehmend eingesetzt, um Menschen bei ihren Entscheidungen zu helfen. Ein schlecht programmierter Algorithmus oder Menschen, denen es an kritischem Denken mangelt, sind wiederkehrende Ursachen für algorithmische Fehler. Diese Fehler lösen manchmal die Wut der Benutzer aus oder regen sie an, sie zu hacken. Dieser Artikel analysiert 6 algorithmische Fehler, die schädliche Folgen für den Menschen hatten. Das vierte Beispiel ist besonders schwerwiegend, weil es Tausende von Menschen betraf und irreparable Schäden verursachte (Selbstmorde, Trennungen, ungerechtfertigte Schulden).

Eine Verhaftung auf der Grundlage einer fehlerhaften algorithmischen Identifizierung (Gesichtserkennung)
Gesichtserkennungsalgorithmen haben jeden Winkel unseres Privatlebens infiltriert (Entsperren Ihres Smartphones, umgekehrte Google-Suche, …), aber auch im professionellen Bereich. Die amerikanische Polizei verwendet diese Art von Algorithmus seit 20 Jahren.
Der erste Fall eines Fehlers aufgrund eines Gesichtserkennungsalgorithmus stammt aus dem Jahr 2020, als die Polizei in Farmington Hills (MI) Robert Julian-Borchak verhaftete. Dieser 41-jährige schwarze Mann wurde für 30 Stunden festgehalten, basierend auf Gesichtserkennung, die von einem minderwertigen Algorithmus produziert wurde. Dieser Fall ist symptomatisch für die Missbräuche, die zu erwarten sind, wenn schlechte Technologie in die Hände von Betreibern gegeben wird, die kein kritisches Urteil über die Wahrscheinlichkeit eines falschen Positivs abgeben.
Was können wir aus diesem algorithmischen Fehler lernen?
Nicht alle Algorithmen sind gleich wirksam. Diese Forschung zeigte, dass ethnische Zugehörigkeit ein sehr wichtiger Faktor für den Fehler von Gesichtserkennungsalgorithmen war. Menschen mit schwarzer Haut und Asiaten sind am anfälligsten für algorithmische Fehler: 10- bis 100-mal mehr als Menschen kaukasischer Herkunft.
Die Qualität der Ergebnisse hängt insbesondere von den verwendeten Trainingsdaten ab. Joy Buolamwinis Arbeit hat die Voreingenommenheit in Trainingsdatensätzen hervorgehoben. Eine Unterrepräsentation ethnischer Minderheiten führt zu größeren Fehlern in diesen Gruppen.

Fehlgeschlagenes algorithmisches Screening für Mieterantragsteller

Die Wahl eines Mieters ist eine kritische Zeit für einen Eigentümer. 9 von 10 Besitzern in den Vereinigten Staaten verlassen sich auf automatisierte Systeme, um Informationen über Mietbewerber zu erhalten. Eine Umfrage zeigt, dass die Algorithmen, die die Daten verarbeiten, grobe Fehler machen. Menschen sind verwirrt; Übereinstimmungen werden zwischen verschiedenen Menschen auf der Grundlage ihrer Nachnamen gemacht.
Die Folgen sind katastrophal, da Personen, die diesem fehlerhaften algorithmischen Urteil unterliegen, der Zugang zu Mieten verweigert wird.

Die oben zitierte Umfrage gibt ein Beispiel für einen algorithmischen Bericht für einen Mietbewerber. Es zeigt eine Punktzahl (von 0 bis 100), auf der der Besitzer seine Entscheidung stützt. Der Bericht weist darauf hin, dass die Punktzahl anhand der von früheren Eigentümern bereitgestellten Informationen, öffentlichen Informationen und einem Kreditbericht berechnet wird. Die Art dieser öffentlichen Informationen wird nicht erwähnt, ebenso wenig wie die Methode zur Berechnung dieses Wertes. Die Punktzahl ist daher undurchsichtig.
Was können wir aus diesem algorithmischen Fehler lernen?
Zwei Lektionen können gelernt werden:
- Datenqualität und -aufbereitung sind Schlüsselfaktoren für den Erfolg. In diesem Fall weist der Disambiguierungsprozess unglaubliche Mängel auf. Daten werden basierend auf dem Nachnamen nur dann abgeglichen, wenn die Personen unterschiedlich sein können. Dieses Niveau des Amateurismus ist unglaublich.
- Die Opazität des Scores und der gesammelten Daten erlaubt es dem Eigentümer nicht, die Qualität der algorithmischen Empfehlung kritisch zu beurteilen. Wenn möglich, sollte die Empfehlung erläutert werden, damit sie angenommen werden kann.

Studierende werden aufgrund von algorithmischen Verdachtsmomenten sanktioniert
Die COVID-Pandemie und die darauffolgenden Einsperrungen haben eine sehr starke Digitalisierung der Bildung ausgelöst. Der Unterricht wurde per Computer gegeben, und die Schüler konnten Prüfungen aus der Ferne ablegen. Das Risiko von Betrug ist gestiegen.
Einige harmlose Verhaltensweisen können als verdächtig angesehen werden und einen Schüler disqualifizieren. Unternehmen schlagen algorithmische Lösungen vor, die riskante Verhaltensweisen erkennen und Lehrer auf die Risiken von Betrug aufmerksam machen sollen. Wie der Fall dieses Studenten aus Florida zeigt, sind die Ergebnisse von Honorlocks Algorithmus alles andere als überzeugend. Der algorithmische Fehler ist in diesem Fall das Ergebnis einer Fehlinterpretation des Verhaltens des Schülers vor der Kamera.
Was können wir aus diesem algorithmischen Fehler lernen?
Oft kann bei Algorithmen ein fehlerhaftes Design nur zu einer Katastrophe führen. Der Algorithmus von Honorlock führt mehrere Interpretationsvoreingenommenheiten in das akademische Betrugsverhalten ein. Die Analyse des Algorithmus basiert auf starren Regeln, und dem Lehrer wird eine Punktzahl zur Verfügung gestellt. Die fehlende Nuance bei der Berechnung der Punktzahl und die Undurchsichtigkeit der Berechnungsmethode führen zu Urteilen, die verheerend sein können.

Illegale Verwendung eines Targeting-Algorithmus durch die niederländischen Steuerbehörden
In diesem Fall, dem sogenannten “toeslagenaffaire” (Wohlfahrtsfall), wurde das Leben von Tausenden von Familien, die Sozialleistungen erhielten, durch einen Algorithmus ruiniert, der von den Steuerbehörden illegal verwendet wurde, um Betrüger zu identifizieren. Die Zahl der Opfer wird auf 2200 geschätzt, mit einem mittleren Verlust von 30.000€. In einigen Fällen betrug der Schaden für den Steuerzahler mehr als 150.000€. Einige Menschen begingen Selbstmord aus Verzweiflung, mehr als tausend Kinder wurden ihren Eltern weggenommen, und Millionen Euro wurden dem Staat zu Unrecht erstattet.
Die niederländischen Steuerbehörden überschritten mit ihrem Algorithmus und der Art und Weise, wie sie die Ergebnisse interpretierten, mehrere rote Linien:
- der Algorithmus identifizierte potenzielle Betrugsfälle, und die Steuerbehörden wandten ungerechtfertigterweise eine Pareto-Regel an: 80 % betrügerisch / 20 % unschuldig, um ihre Ermittlungen fortzusetzen
- Das Targeting basierte teilweise auf der zweiten Staatsangehörigkeit des Steuerpflichtigen. Die Steuerbehörden verfügten über keine Rechtsgrundlage für die Analyse dieser Variablen. Eine im Jahr 2020 durchgeführte Prüfung ergab, dass 4 andere Algorithmen der Steuerbehörden zur Betrugsbekämpfung diese Variable zu Unrecht verwendeten.
Der Fall ist äußerst schwerwiegend, und die Missbräuche der niederländischen Steuerbehörden wurden von der Datenschutzbehörde, die eine Geldbuße von 3,6 Mio.€ verhängte, streng sanktioniert.
Was können wir aus diesem algorithmischen Fehler lernen?
Dieser Fall führt zu 3 Lektionen:
- Die Variablen, die von einem Algorithmus zur Durchführung seiner Berechnung verwendet werden, müssen eine rechtliche Grundlage haben
- Einige Variablen können nur verwendet werden, wenn sie einen ursächlichen Zusammenhang mit dem erwarteten Ergebnis haben. Im “toeslagenaffaire” gab es keine empirische Grundlage, um zu zeigen, dass die zweite Nationalität eine Ursache für Betrug war.
- Die Ergebnisse eines Targeting-Algorithmus sollten als das betrachtet werden, was sie sind, d. h. Arbeitshypothesen. Bei der Anwendung der 80/20-Regel waren die niederländischen Steuerbeamten schuldhaft fahrlässig und amateurhaft.

Verzerrter Algorithmus für die Studentenorientierung in der Hochschulbildung
Der Fall des französischen Hochschulauswahlalgorithmus brach 2016 aus. Der Algorithmus, genannt APB, erlaubte Universitäten, Schüler auszuwählen, die von der High School kommen. Die Variablen, die von diesem Algorithmus verwendet wurden, um das Schicksal der Studenten zu entscheiden, wurden geheim gehalten, bis ein Anwalt das Bildungsministerium verklagte. Dann wurde festgestellt, dass die verwendeten Variablen keine Rechtsgrundlage hatten. Schlimmer noch, einige Variablen, die bei der Berechnung des Algorithmus verwendet wurden, waren diskriminierend (Alter, Herkunftsland) oder inkongruent (dritter Name). Die Zahl der “Opfer” dieses Algorithmus ist unbekannt, aber wir können berechtigterweise glauben, dass Tausende von Studenten durch algorithmische Entscheidungen gegen ihr besseres Urteilsvermögen benachteiligt wurden.
Was können wir aus diesem algorithmischen Fehler lernen?
Die Programmierverzerrungen des APB-Algorithmus sind offensichtlich. Der Algorithmus war nicht darauf ausgelegt, die Interessen von Studierenden zu maximieren, die in die Hochschulbildung eintreten, sondern die der Universitäten.
Der APB-Algorithmus ist in der Tat eine einfache “Geschäftsregel” Formel. Die berücksichtigten Variablen weisen keinen kausalen Zusammenhang mit einem für den Studierenden vorteilhaften Ziel auf. Beispielsweise wäre es viel relevanter gewesen, Variablen zu berücksichtigen, die die Erfolgsquote von Universitätsstudenten maximieren. Der perfekte Algorithmus hätte die beste Wahl für den Schüler vorschlagen können, um erfolgreich zu sein, während er dem Schüler die Freiheit gegeben hätte, eine weniger gute Lösung zu wählen (zum Beispiel eine Schule, die näher zu Hause ist).

Inhaltszensur durch den Tik Tok Algorithmus
Der Empfehlungsalgorithmus ist ein Eckpfeiler des Erfolgs von Tik Tok. Der Algorithmus ist so programmiert, dass er Inhalte im Zusammenhang mit Homosexualität, bestimmten politisch sensiblen Themen und Persönlichkeiten des öffentlichen Lebens versteckt. Die in China geborene Plattform wurde beschuldigt, die Sichtbarkeit von Inhalten, die von der LGBTQ+ -Community veröffentlicht werden, künstlich zu verringern. Dieser algorithmische Ausschluss ist in dieser qualitativen Forschung gut artikuliert. Ein Auditbericht des Australian Strategic Policy Institute (ASPI) zeigt, dass Hashtags identifizierte Keywords auf TikTok zensiert werden. Aus dem Guardian erfahren wir, dass im Juni 2020 eine Liste von 20 Persönlichkeiten erstellt wurde, die nicht auf TikTok erscheinen sollte. Wir finden Kim Jong-il, Kim Jong-Un, Wladimir Putin und Donald Trump unter ihnen.
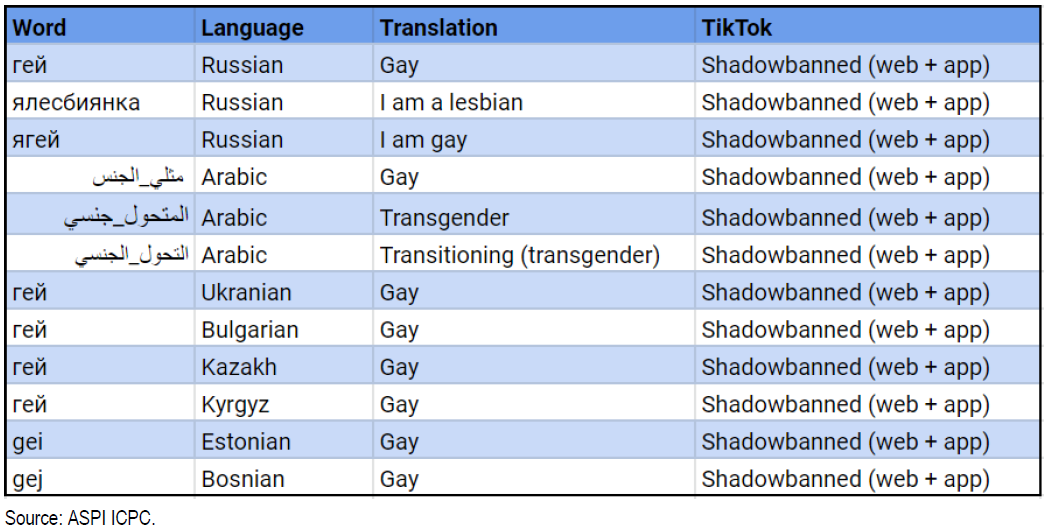
Was können wir aus diesem algorithmischen Fehler lernen?
Der Fall des TikTok-Algorithmus ist vielleicht der unwahrscheinlichste, der ein algorithmischer Fehler ist. Der Algorithmus hat genau so gehandelt, wie seine Designer es wollten, indem er bestimmte Inhalte zensierte. Es ist also letztlich eine menschliche Voreingenommenheit, die zur “gerichteten” Programmierung des Algorithmus geführt hat.
![Illustration unseres Beitrags "Kostenlose generative KI-Detektoren: Welche soll man wählen? [Vollständiger Test 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)



