

Algorithms are increasingly used to help humans in their decisions. A poorly programmed algorithm, or humans lacking critical thinking skills, are recurrent causes of algorithmic errors. These errors sometimes trigger users’ anger or incite them to hack them. This article analyzes 6 algorithmic errors that have had harmful consequences on humans. The 4th example is particularly serious because it impacted thousands of people and caused irreparable damage (suicides, separations, unjustified debts).

An arrest based on an erroneous algorithmic identification (facial recognition)
Facial recognition algorithms have infiltrated every corner of our private life (unlocking your smartphone, reverse Google search, …) but also in the professional sphere. The American police have been using this type of algorithm for 20 years.
The first case of an error due to a facial recognition algorithm dates back to 2020 when the police in Farmington Hills (MI) arrested Robert Julian-Borchak. This 41-year-old black man was detained for 30 hours based on facial recognition produced by a low-quality algorithm. This case is symptomatic of the abuses to be expected when bad technology is put in the hands of operators who do not exercise critical judgment about the likelihood of a false positive.
What can we learn from this algorithmic error?
Not all algorithms are equally effective. This research showed that ethnicity was a very important factor in the error of facial recognition algorithms. People with black skin and Asians are the most prone to algorithmic errors: 10 to 100 times more than people of Caucasian origin.
The quality of the results depends, in particular, on the training data used. Joy Buolamwini’s work has highlighted the biases in training data sets. Under-representation of ethnic minorities leads to larger errors in these groups.

Unsuccessful algorithmic screening for tenant applicants

Choosing a tenant is a critical time for an owner. 9 out of 10 owners in the United States rely on automated systems to obtain information about rental applicants. A survey shows that the algorithms that process the data make gross errors. People are confused; matches are made between different people based on their last names.
The consequences are disastrous since people subject to this erroneous algorithmic judgment are denied access to rentals.

The survey cited above gives an example of an algorithmic report for a rental applicant. It shows a score (from 0 to 100) on which the owner bases his decision. The report indicates that the score is calculated using the information provided by previous owners, public information, and a credit report. The nature of this public information is not mentioned, nor is the method of calculating this score. The score is, therefore, opaque.
What can we learn from this algorithmic error?
Two lessons can be learned:
- Data quality and preparation are key factors for success. In this case, the disambiguation process has unbelievable shortcomings. Data is reconciled based on the last name only when the individuals may be different. This level of amateurism is unbelievable.
- The opacity of the score and the data collected does not allow the owner to judge the quality of the algorithmic recommendation critically. If possible, the recommendation should be explained for it to be accepted.

Students are sanctioned based on algorithmic suspicions
The Covid pandemic and the confinements that followed initiated a very strong digitalization of education. Classes were given via computer, and students could take exams remotely. The risk of cheating has increased.
Some innocuous behaviors can be deemed suspicious and disqualify a student. Companies propose algorithmic solutions that are supposed to detect risky behaviors and alert teachers to the risks of cheating. As the case of this student from Florida shows, the results of Honorlock’s algorithm are far from convincing. The algorithmic error, in this case, is the product of a misinterpretation of the student’s behavior on camera.
What can we learn from this algorithmic error?
Often with algorithms, faulty design can only lead to disaster. Honorlock’s algorithm introduces several interpretation biases into academic cheating behavior. The algorithm’s analysis is based on rigid rules, and a score is provided to the teacher. The lack of nuance in the calculation of the score, and the opacity of the method of calculation, lead to judgments that can be devastating.

Illegal use of a targeting algorithm by the Dutch tax authorities
In this case, the so-called “toeslagenaffaire” (welfare case), the lives of thousands of families receiving welfare benefits were ruined because of an algorithm illegally used by the tax authorities to identify fraudsters. The number of victims is estimated at 2200, with a median loss of 30.000€. In some cases, the damage for the taxpayer amounted to more than 150.000€. Some people committed suicide out of despair, more than a thousand children were taken away from their parents, and millions of Euros were unduly reimbursed to the State.
The Dutch tax authorities crossed several red lines with their algorithm and the way they interpreted the results:
- The algorithm identified potential fraud cases, and the tax authorities unjustifiably applied a Pareto rule: 80% fraudulent / 20% innocent to continue their investigations
- The targeting was partly based on the second nationality of the taxpayer. The tax authorities had no legal basis for analyzing this variable. An audit realized in 2020 showed that 4 other anti-fraud algorithms of the tax authorities were unduly using this variable.
The case is extremely serious, and the abuses of the Dutch tax authorities have been severely sanctioned by the Data Protection Authority, which imposed a fine of €3.6m.
What can we learn from this algorithmic error?
This case leads to 3 lessons:
- The variables used by an algorithm to perform its calculation must have a legal basis
- Some variables can only be used if they have a causal link to the expected result. In the “toeslagenaffaire,” there was no empirical basis to show that the second nationality was a cause of fraud.
- The results delivered by a targeting algorithm should be considered for what they are, i.e., working hypotheses. In applying the 80/20 rule, the Dutch tax officials were culpably negligent and amateurish.

Biased algorithm for student orientation in higher education
The French university selection algorithm case broke out in 2016. The algorithm, called APB, allowed universities to select students coming from high school. The variables used by this algorithm to decide the fate of students were kept secret until a lawyer sued the Ministry of Education. It was then discovered that the variables used had no legal basis. Worse, some variables used in calculating the algorithm were discriminatory (age, country of origin) or incongruous (third name). The number of “victims” of this algorithm is unknown, but we can legitimately think that thousands of students were disadvantaged by algorithmic choices against their better judgment.
What can we learn from this algorithmic error?
The programming biases of the APB algorithm are obvious. The algorithm was not designed to maximize the interests of students entering higher education but rather those of the universities.
The APB algorithm is, in fact, a simple “business rule” formula. The variables taken into account do not show any causal link with a beneficial objective for the student. For example, it would have been much more relevant to consider variables that maximize university students’ success rate. The perfect algorithm could have proposed the best choice for the student to succeed while allowing the student the freedom to choose a less good solution (for example, a school closer to home).
Content censorship by the Tik Tok algorithm
 Content censorship by the Tik Tok algorithm
Content censorship by the Tik Tok algorithmThe recommendation algorithm is a cornerstone of Tik Tok’s success. The algorithm is programmed to hide content related to homosexuality, certain politically sensitive topics, and public figures. The Chinese-born platform has been accused of artificially lowering the visibility of content posted by the LGBTQ+ community. This algorithmic exclusion is well articulated in this qualitative research. An audit report by ASPI (Australian Strategic Policy Institute) shows that hashtag-identified keywords are censored on TikTok. We learn from the Guardian that in June 2020, a list of 20 personalities had been established that should not appear on TikTok. We find Kim Jong-il, Kim Jong-Un, Vladimir Putin, and Donald Trump among them.
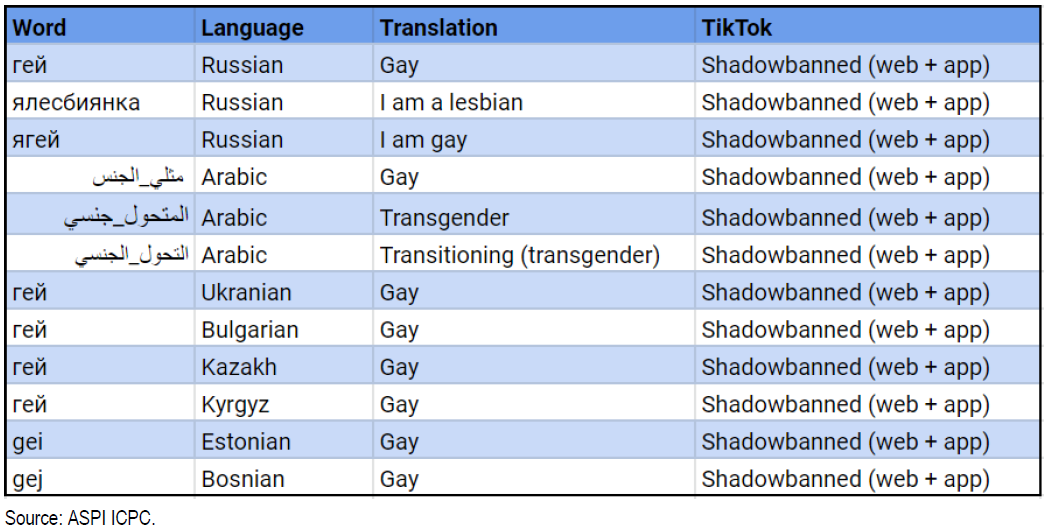
What can we learn from this algorithmic error?
The case of TikTok algorithm is perhaps the least likely to be an algorithmic error. The algorithm has acted exactly as its designers wanted by censoring certain content. It is, therefore, ultimately a human bias that led to the “directed” programming of the algorithm.



![Illustration of our post "Free Generative AI Detectors: Which Ones to Choose? [Complete Test 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)

