

Los algoritmos son usados a un nivel increíble para ayudar a los humanos a tomar decisiones, y uno mal programado, o humanos que no poseen la habilidad de un pensamiento crítico, son causas recurrentes de errores algorítmicos. Estos errores en ocasiones provocan la ira del usuario y los invitan a hackearlos. Este artículo analiza 6 errores de algoritmos que han tenido consecuencias dañinas para los humanos. El ejemplo nº 4 es especialmente grave ya que ha afectado a miles de personas y ha provocado daños irreparables (suicidios, separaciones, deudas injustificadas).

Una detención basada en una identificación algorítmica errónea (reconocimiento facial)
Los algoritmos de reconocimiento facial se han filtrado hasta el último recoveco de nuestras vidas privadas (desbloquear tu smartphone, búsqueda inversa en Google…), pero también en la esfera profesional. La policía americana lleva usando este tipo de algoritmo desde hace 20 años.
El primer caso de un error debido a un algoritmo de reconocimiento facial tiene fecha de 2020, cuando la policía de Farmington Hills (MI) arrestó a Robert Julian-Borchak. Este hombre negro de 41 años pasó 30 horas detenido por un reconocimiento facial producido por un algoritmo de poca calidad. Este caso es sintomático de los abusos que pueden esperarse cuando una mala tecnología se pone en manos de operadores que no utilizan el pensamiento crítico sobre la posibilidad de un falso positivo.
¿Qué podemos aprender del error de este algoritmo?
No todos los algoritmos son igual de efectivos. Este estudio mostró que la etnia era un factor muy importante en los errores de los algoritmos de reconocimiento facial. Las personas de piel oscura y los asiáticos tienen más probabilidades de provocar errores algorítmicos: entre 10 y 100 veces más que las personas de origen caucásico.
La calidad de los resultados depende, en concreto, de los datos de entrenamiento utilizados. El trabajo de Joy Buolamwini ha destacado los sesgos en los conjuntos de datos de entrenamiento, donde la poca representación de minorías éticas provoca mayores errores en estos grupos.

Análisis algorítmico infructuoso de candidatos a inquilinos

Elegir a un inquilino es un momento crítico para el dueño de una propiedad: 9 de cada 10 propietarios en Estados Unidos recurre a sistemas automatizados para obtener información sobre posibles inquilinos. Una encuesta muestra que los algoritmos que procesan dichos datos cometen grandes errores: se confunden a las personas, es decir, se establecen conexiones entre distintas personas basándose únicamente en sus apellidos.
Las consecuencias son desastrosas, ya que la gente que sufre este juicio algorítmico erróneo ven rechazadas sus solicitudes de alquiler.

La encuesta citada más arriba da un ejemplo de un informe algorítmico para un interesado en un alquiler. Muestra una puntuación (del 0 al 100) a partir de la cual el propietario basa su decisión. El informe indica que la puntuación se calcula utilizando la información ofrecida por propietarios anteriores, información pública, y un informe de crédito. La naturaleza de esta información pública no se menciona, ni tampoco el método con el que se calcula la puntuación, lo que hace que dicha puntuación resulte opaca.
¿Qué podemos aprender del error de este algoritmo?
Se pueden aprender dos lecciones:
- La calidad de los datos y la preparación son factores claves del éxito. En este caso, el proceso de desambiguación tiene deficiencias increíbles. Los datos se concilian basándose exclusivamente en el apellido cuando los individuos bien pueden ser diferentes. Un nivel de principiante como ese resulta increíble.
- La opacidad de la puntuación y de los datos recogidos no permite que el propietario juzgue la calidad de la recomendación algorítmica de manera crítica. En caso de ser posible, la recomendación debería explicarse para poder ser aceptada.

Estudiantes sancionados en base a sospechas algorítmicas
La pandemia del Covid y los confinamientos que se produjeron posteriormente iniciaron una digitalización muy intensa en la educación. Las clases se daban a través del ordenador, y los estudiantes podían realizar los exámenes a distancia, por lo que el peligro de las trampas aumentó.
Algunos comportamientos inocuos pueden parecer sospechosos y descalificar a un estudiante. Las empresas proponen soluciones algorítmicas que se supone deben detectar comportamientos de riesgo y advertir a los profesores del peligro de que se estén haciendo trampas. Tal y como muestra el caso de este estudiante de Florida, los resultados del algoritmo Honorlock quedan muy lejos de ser convincentes. El error algorítmico, en este caso, es el producto de una malinterpretación del comportamiento del estudiante que está frente a la cámara.
¿Qué podemos aprender del error de este algoritmo?
En el caso de los algoritmos, a menudo un diseño defectuoso puede llevar al desastre. El algoritmo Honorlock presenta varios sesgos de interpretación dentro del comportamiento de las trampas académicas. El análisis de dicho algoritmo se basa en unas normas rígidas, y se presenta al profesor una puntuación. La falta de matices en el cálculo de dicha puntuación, y la opacidad en el método con el que se calcula, lleva a tomas de decisiones que pueden resultar devastadoras.

Uso ilegal de un algoritmo de selección por parte de las autoridades fiscales holandesas
En este caso, en el conocido como «toeslagenaffaire» (caso de asistencia social), las vidas de miles de familias que recibían beneficios sociales acabaron arruinada por un algoritmo que se usó de manea ilegal por parte de las autoridades fiscales para identificar a defraudadores. Se estima que el número de víctima ronda los 2.200, con una pérdida media de 30.000€. En el caso de algunos, el daño para el contribuyente llegó a superar los 150.000e. Algunas personas se suicidaron de pura desesperación, más de mil niños fueron retirados de la custodia de sus padres, y se reembolsaron indebidamente millones de euros al Estado.
Las autoridades fiscales holandesas cruzaron varias líneas rojas con su algoritmo y con el modo en el que interpretaron los resultados:
- El algoritmo identificó posibles casos de fraude fiscal, y las autoridades fiscales aplicaron de manera injustificada una regla de Pareto: 80% fraudulentos / 20% inocentes para continuar sus investigaciones.
- Sus objetivos se basaban en parte en la segunda nacionalidad del contribuyente, a pesar de que las autoridades fiscales no tenían base legal para analizar dicha variable. Una auditoría realizada en 2020 mostró que otros 4 algoritmos antifraude de las autoridades fiscales estaban usando esta variable indebidamente.
El caso es extremadamente serio, y los abusos de las autoridades fiscales holandesas se han sancionado de manera severa por parte de la Autoridad de Protección de datos, que impuso una multa de 3,6 millones de euros.
¿Qué podemos aprender del error de este algoritmo?
Este caso nos lleva a 3 lecciones:
- Las variables utilizadas por el algoritmo para realizar sus cálculos deben tener una base legal
- Algunas variables solo pueden utilizarse si tienen un vínculo causal con los resultados esperados. En el «toeslagenaffaire», no había ninguna base empírica que mostrase que la segunda nacionalidad fuese una razón para defraudar.
- Los resultados que ofrece un algoritmo de focalización deberían considerarse como lo que son, es decir, hipótesis de trabajo. Al aplicar la norma 80/20, los agentes fiscales holandeses fueron culpables de negligencia y de un comportamiento poco profesional.

Algoritmos sesgados en la orientación de estudiantes en la educación superior
El caso del algoritmo de selección de universidades francés saltó en 2016. Dicho algoritmo, llamado APB, permitía que las universidades seleccionaran estudiantes provenientes de institutos. Las variables utilizadas por este algoritmo que decidía el destino de los estudiantes se mantuvieron en secreto hasta que un abogado denunció al Ministerio de Educación, momento en el que se descubrió que las variables usadas no tenían una base legal. Y peor aún, algunas de las utilizadas en los cálculos del algoritmo eran discriminatorias (edad, país de origen) o incongruentes (tercer nombre). Se desconoce el número de «víctimas» de este algoritmo, pero es legítimo pensar que miles de estudiantes fueron perjudicados por unas elecciones algorítmicas que van contra todo buen juicio.
¿Qué podemos aprender del error de este algoritmo?
Los sesgos de programación del algoritmo APB resultan evidentes. Este algoritmo no se diseñó para maximizar los intereses de los estudiantes de entrar en la educación superior, sino según los intereses de las universidades.
El algoritmo APB es, de hecho, una sencilla fórmula de «reglas empresariales». Las variables que se tienen en cuenta no muestran ningún vínculo causal con un objetivo beneficioso para el alumno. Por ejemplo, considerar las variables que maximizan la proporción de éxito de un estudiante universitario había sido mucho más relevante. El algoritmo perfecto podría haber propuesto la mejor opción para que el alumno tuviera éxito, pero permitiéndole la libertad de elegir una solución menos buena (por ejemplo, una escuela más cercana a su hogar).

Censura de contenido por el algoritmo de Tik Tok
El algoritmo de recomendación es la piedra angular del éxito de Tik Tok, pero se programa para ocultar contenidos relacionados con la homosexualidad, ciertos temas políticos sensibles, y figuras públicas. La plataforma de origen chino ha sido acusada de disminuir de manera artificial la visibilidad del contenido publicado por la comunidad LGBTQ+. Esta exclusión algorítmica quedó bien articulada en este estudio cualitativo. En un informe de auditoría realizado por ASPI (Instituto Australiano de Política Estratégica), se muestra que ciertas palabras clave identificadas con hashtags se ven censuradas en Tik Tok. En junio de 2020 aprendimos de mano de The Guardian una lista de 20 personalidades que, según se había establecido, no debían aparecer en Tik Tok, entre ellas Kim Jong-il, Kim Jong-Un, Vladimir Putin, y Donald Trump.
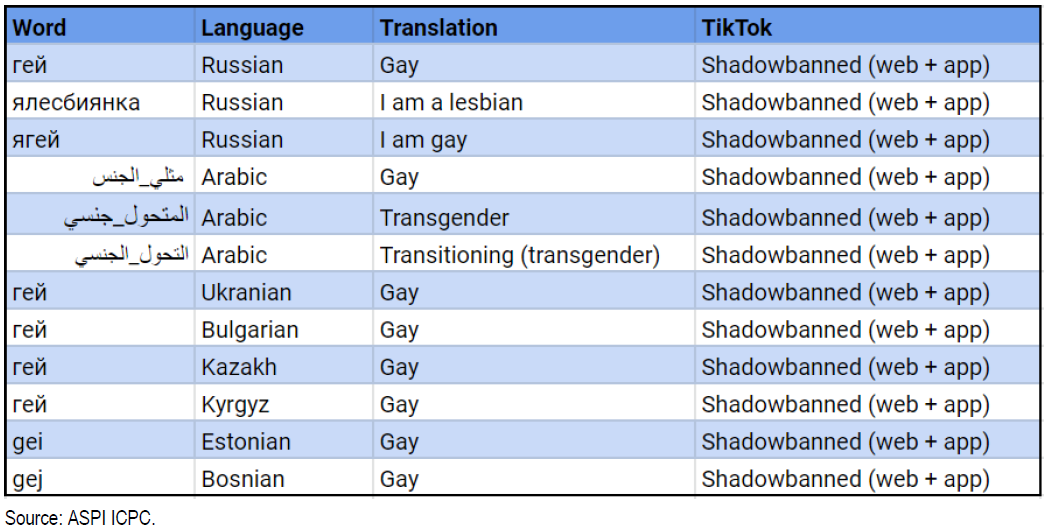
¿Qué podemos aprender del error de este algoritmo?
El caso del algoritmo de Tik Tok quizás sea el que menos probabilidades tiene de ser un error algorítmico, ya que este ha actuado tal y como sus diseñadores deseaban al censurar cierto contenido. Es decir, al final han sido los sesgos humanos los que han «dirigido» la programación del algoritmo.





