

Les algorithmes sont de plus en plus utilisés pour aider les humains dans leurs décisions. Un algorithme mal programmé, ou un humain manquant de sens critique, sont des causes récurrentes aux erreurs algorithmiques. Celles-ci déclenchent parfois la colère des utilisateurs ou les incite à les hacker. Dans cet article nous analysons 6 erreurs algorithmiques qui ont eu des conséquences néfastes sur des humains. Le 4ème exemple est particulièrement grave car il a impacté des milliers de personnes et a provoqué des préjudices irréparables (suicides, séparations, dettes non justifiées).

Arrestation sur base d’une identification algorithmique erronée (reconnaissance faciale)
Les algorithmes de reconnaissance faciale se sont infiltrés dans tous les interstices de notre vie privée (déverrouillage de votre smartphone, recherche inversée sur Google, …) mais également dans la sphère professionnelle. La police américaine utiliserait ce type d’algorithmes depuis déjà 20 ans.
Le 1er cas d’une erreur due à un algorithme de reconnaissance faciale remonte à 2020, quand Robert Julian-Borchak a été arrêté par la police de Farmington Hills (MI). Cet homme noir de 41 ans a été détenu pendant 30 heures sur la base d’une reconnaissance faciale produite par un algorithme de basse qualité. Ce cas est symptomatique des dérives auxquelles s’attendre quand une mauvaise technologie est mise dans les mains d’opérateurs qui n’exercent aucun jugement critique sur la probabilité d’un faux positif.
Que retenir de cette erreur algorithmique ?
Tous les algorithmes ne se valent pas. Il a été démontré dans cette étude comparative d’algorithmes de reconnaissance faciale que l’ethnicité était un facteur d’erreur très important. Les personnes à peau noire ainsi que les asiatiques sont les plus sujets aux erreurs algorithmiques : 10 à 100 fois plus que les personnes d’origine caucasienne.
La qualité des résultats dépend notamment des données d’entraînement utilisées. Les travaux de Joy Buolamwini ont mis en exergue les biais dans les jeux de données d’entraînement. La sous-représentation de minorités ethniques entraîne des erreurs plus grandes sur ces groupes.

Screening algorithmique raté pour des candidats locataires

Le choix d’un locataire est un moment crucial pour un propriétaire. Aux Etats-Unis, 9 propriétaires sur 10 font donc confiance à des systèmes automatisés pour obtenir des informations sur les candidats à la location. Une enquête montre que les algorithmes qui traitent les données commettent des erreurs grossières. Des personnes sont confondues, des rapprochements effectués entre des personnes différentes sur la base de leur nom de famille.
Les conséquences sont désastreuses puisque les personnes qui font l’objet de ce jugement algorithmique erroné se voient refuser l’accès à la location.

L’enquête citée ci-dessus donne un exemple de rapport algorithmique pour un candidat à la location. On y voit un score (de 0 à 100) sur lequel le propriétaire se base pour prendre sa décision. Le rapport indique que le score est calculé grâce à des informations fournies par les propriétaires précédents, des informations publiques ainsi qu’un rapport de crédit. La nature de ces informations publiques n’est pas mentionnée, ni même le mode de calcul de ce score. Le score est donc opaque.
Que retenir de cette erreur algorithmique ?
Deux leçons peuvent être tirées :
- La qualité des données et leur préparation sont des facteurs-clés de succès. Dans le cas présent, le processus de désambiguïsation présente des lacunes à peine croyables. Des données sont réconciliées sur la seule base du nom de famille alors que les individus peuvent être différents. Ce niveau d’amateurisme est à peine croyable.
- L’opacité du score et des données collectées ne permet pas au propriétaire d’exercer un jugement critique sur la qualité de la recommandation algorithmique. Il faut, dans la mesure du possible, expliquer la recommandation afin qu’elle soit acceptée.

Etudiants sanctionnés sur la base de soupçons algorithmiques
La pandémie de Covid et les confinements qui ont suivi ont initié une digitalisation très forte de l’enseignement. Les cours se sont donnés par ordinateur interposé, et les étudiants ont pu passer des examens à distance. Le risque de triche a été accru.
Des sociétés proposent des solutions algorithmiques censées détecter les comportements à risque et alerter les enseignants sur les risques de triche. Comme le montre le cas de cette étudiante de Floride, les résultats de l’algorithme de la société Honorlock sont loin d’être convaincants. Certains comportements anodins peuvent être jugés comme suspicieux et mener à une disqualification de l’étudiant. L’erreur algorithmique est dans ce cas le produit d’une mauvaise interprétation du comportement de l’étudiant devant sa caméra.
Que retenir de cette erreur algorithmique ?
Comme souvent en matière d’algorithmes, une conception défaillante ne peut que conduire à des catastrophes. L’algorithme de la société Honorlock introduit un certain nombre de biais d’interprétation dans les comportements liés à la triche scolaire. L’analyse de l’algorithme se base sur des règles rigides et un score est fourni à l’enseignement. Le manque de nuance dans le calcul du score, et l’opacité du mode de calcul, conduisent à des jugements qui peuvent être dévastateurs.

Utilisation illégale d’un algorithme de ciblage par le fisc néerlandais
Dans cette affaire, dite « toeslagenaffaire » (l’affaire des aides sociales) la vie de milliers de familles bénéficiaires d’aides sociales a été ruinée à cause d’un algorithme utilisé illégalement par le fisc pour identifier des fraudeurs. Certaines personnes se sont suicidées de désespoir, plus de mille enfants ont été arrachés à leurs parents et des millions d’Euros ont été indûment remboursés à l’Etat. On estime à 2200 le nombre de victimes avec un préjudice médian de 30.000€. Dans certains cas, le préjudice pour le contribuable s’est élevé à plus de 150.000€.
Le fisc néerlandais a franchi plusieurs lignes rouges avec son algorithme et sa manière d’interpréter les résultats :
- l’algorithme identifiait des cas de fraudes potentielles et le fisc a appliqué sans justification une règle de Pareto : 80% de fraudeurs / 20% d’innocents pour poursuivre ses investigations
- le ciblage était effectué en partie sur la base de la deuxième nationalité du contribuable. Le fisc ne disposait d’aucune base légale pour analyser cette variable. Un audit réalisé en 2020 a montré que 4 autres algorithmes anti-fraude du fisc utilisaient indûment cette variable.
L’affaire est extrêmement grave et les dérives du fisc néerlandais ont été durement sanctionnées par l’autorité de protection des données qui a infligé une amende de 3,6m€.
Que retenir de cette erreur algorithmique ?
Cette affaire conduit à 3 enseignements :
- Les variables utilisées par un algorithme pour effectuer son calcul doivent avoir une base légale
- Certaines variables ne peuvent être utilisées que si elles ont un lien de causalité avec le résultat attendu. Dans la « toeslagenaffaire », il n’y avait pas de base empirique pour démontrer que la deuxième nationalité était une cause de fraude.
- Les résultats livrés par un algorithme de ciblage doivent être considérés pour ce qu’ils sont, c’est-à-dire des hypothèses de travail. En appliquant la règle 80/20, les agents du fisc néerlandais ont fait preuve d’une négligence et d’un amateurisme coupables.

Algorithme biaisé pour l’orientation des étudiants dans le supérieur
L’affaire de l’algorithme de sélection des universités françaises a éclaté en 2016. L’algorithme, appelé APB, permettait aux universités de sélectionner les étudiants venant du lycée. Les variables utilisées par cet algorithme pour décider du sort des étudiants ont été gardées secrètes jusqu’à ce qu’un avocat assigne le Ministère de l’Education. On découvrit alors que les variables utilisées n’avaient pas de fondement légal. Pire, certaines variables rentrant dans le calcul de l’algorithme étaient clairement discriminatoires (âge, pays origine) ou totalement incongrues (troisième prénom). Le nombre de « victimes » de cet algorithme n’est pas connu mais on peut légitimement penser que des milliers d’étudiants ont été défavorisés par des choix algorithmiques faits en dépit du bon sens.
Que retenir de cette erreur algorithmique ?
Les biais de programmation de l’algorithme APB sont évidents. L’algorithme n’était pas conçu pour maximiser les intérêts des étudiants rentrant dans le supérieur, mais bien ceux des universités.
L’algorithme APB s’apparente de fait à une simple formule de type « règle métier » (ou « business rule »). Les variables prises en compte ne montrent aucun lien de causalité avec un objectif bénéfique pour l’étudiant. Il aurait par exemple été beaucoup plus pertinent de prendre en compte des variables qui permettent de maximiser le taux de réussite des étudiants en université. L’algorithme parfait aurait pu proposer le meilleur choix pour que l’étudiant réussisse, tout en lui laissant la liberté d’opter pour une solution moins favorable (par exemple un établissement plus proche de chez lui).

Censure de contenu par l’algorithme de Tik Tok
L’algorithme de recommandation est une pierre angulaire du succès de Tik Tok. La plateforme d’origine chinoise a été accusée de diminuer artificiellement la visibilité des contenus postés par la communauté LGBTQ+. Cette exclusion algorithmique est bien exprimée dans cette étude qualitative. Un rapport d’audit de l’ASPI (Australian Strategic Policy Institute) montre que des mots-clés identifiés par un hashtag sont censurés sur TikTok. L’algorithme est programmé pour cacher les contenus en lien avec l’homosexualité, certains sujets politiques sensibles ainsi que des personnalités publiques. On apprend ainsi par le Guardian qu’en Juin 2020 une liste de 20 personnalités avait été établie qui ne devaient pas apparaître sur TikTok. Parmi elles on trouve Kim Jong-il, Kim Jong-Un, Vladimir Poutine ou encore Donald Trump.
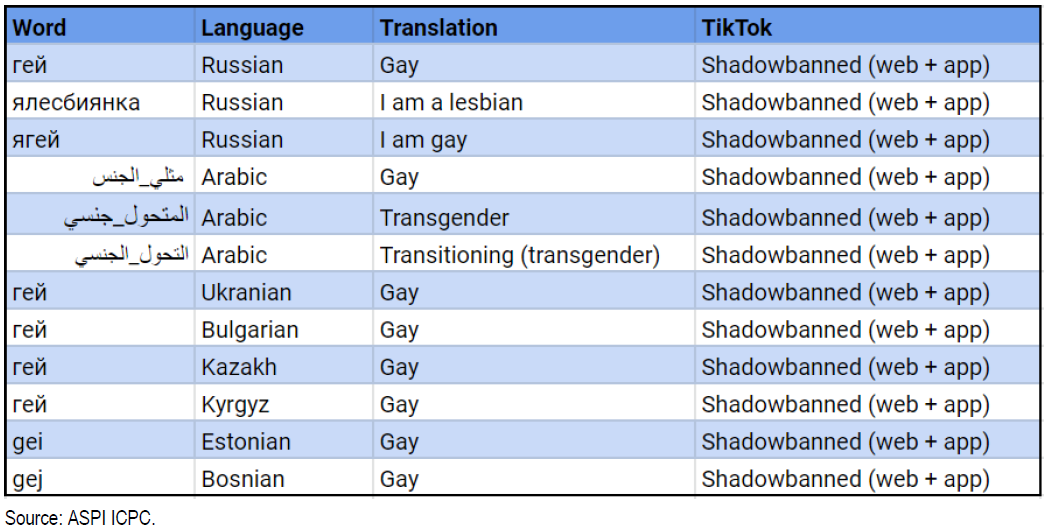
Que retenir de cette erreur algorithmique ?
Le cas de l’algorithme de TikTok est peut-être ce qui s’apparente le moins à une erreur algorithmique. L’algorithme a en effet agi exactement comme ses concepteurs l’ont souhaité, en censurant certains contenus. Il s’agit donc au final d’un biais humain ayant conduit à une programmation « orientée » de l’algorithme.

![Illustration de notre publication "Détecteurs d’IA générative gratuits : lesquels choisir ? [Test complet 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)



