

Algoritmen worden steeds vaker gebruikt om mensen te helpen bij het nemen van beslissingen. Een slecht geprogrammeerd algoritme, of een mens zonder kritisch denkvermogen, zijn terugkerende oorzaken van algoritmische fouten. Deze fouten leiden soms tot woede bij de gebruikers of zetten hen aan tot hacken. In dit artikel analyseren wij 6 algoritmische fouten die negatieve gevolgen hebben gehad voor de mens. Het 4e voorbeeld is bijzonder ernstig omdat het duizenden mensen trof en onherstelbare schade veroorzaakte (zelfmoorden, scheidingen, ongerechtvaardigde schulden).

Arrestatie op basis van onjuiste algoritmische identificatie (gezichtsherkenning)
Gezichtsherkenningsalgoritmen zijn geïnfiltreerd in elke hoek van ons privéleven (ontgrendeling van uw smartphone, omgekeerd zoeken op Google, enz. De Amerikaanse politie gebruikt dit soort algoritmen al 20 jaar.
Het eerste geval van een fout in een gezichtsherkenningsalgoritme deed zich voor in 2020, toen Robert Julian-Borchak werd gearresteerd door de politie van Farmington Hills (MI) (Engelse site). De 41-jarige zwarte man werd 30 uur lang vastgehouden op basis van gezichtsherkenning door een algoritme van lage kwaliteit. Dit geval is symptomatisch voor het te verwachten misbruik wanneer slechte technologie in handen wordt gegeven van operatoren die geen kritisch oordeel vellen over de kans op een vals positief resultaat.
Wat kunnen we leren van deze algoritmische fout?
Niet alle algoritmen zijn gelijk. In deze vergelijkende studie van gezichtsherkenningsalgoritmen (Engelse site) bleek etniciteit een zeer belangrijke foutfactor te zijn. Mensen met een zwarte huidskleur en Aziaten zijn het meest vatbaar voor algoritmische fouten: 10 tot 100 keer meer dan mensen van Kaukasische afkomst.
De kwaliteit van de resultaten hangt met name af van de gebruikte trainingsgegevens. Het werk van Joy Buolamwini (Franse site) heeft de vertekeningen in de trainingsgegevensreeksen aan het licht gebracht. De ondervertegenwoordiging van etnische minderheden leidt tot grotere fouten bij deze groepen.

Niet geslaagde algoritmische screening van huurkandidaten

Het kiezen van een huurder is een cruciaal moment voor een verhuurder. In de Verenigde Staten vertrouwen 9 van de 10 verhuurders daarom op geautomatiseerde systemen om informatie over toekomstige huurders te verkrijgen. Uit een onderzoek (Engelse site) blijkt dat de algoritmen die de gegevens verwerken grove fouten maken. Mensen raken in de war, er worden matches gemaakt tussen verschillende mensen op basis van hun achternaam.
De gevolgen zijn desastreus omdat mensen die aan dit foutieve algoritmische oordeel worden onderworpen, de toegang tot huur wordt ontzegd.

Bron: themarkup.org
Het hierboven geciteerde onderzoek geeft een voorbeeld van een algoritmisch rapport voor een toekomstige huurder. Het toont een score (van 0 tot 100) waarop de verhuurder zijn beslissing baseert. Het rapport geeft aan dat de score wordt berekend aan de hand van informatie van vorige verhuurders, openbare informatie en een kredietrapport. De aard van deze openbare informatie wordt niet vermeld, evenmin als de manier waarop de score wordt berekend. De score is dus ondoorzichtig.
Wat kunnen we leren van deze algoritmische fout?
Hieruit kunnen twee lessen worden getrokken:
- De kwaliteit van de gegevens en de voorbereiding ervan zijn sleutelfactoren voor succes. In dit geval vertoont het ondubbelzinnig maken ongelooflijke tekortkomingen. De gegevens worden alleen op basis van de achternaam afgestemd terwijl het om verschillende personen kan gaan. Dit niveau van amateurisme is ongelooflijk.
- Door de ondoorzichtigheid van de score en de verzamelde gegevens kan de eigenaar de kwaliteit van de algoritmische aanbeveling niet kritisch beoordelen. De aanbeveling moet zoveel mogelijk worden toegelicht om als betrouwbaar beschouwd te worden.

Studenten bestraft op basis van algoritmische verdenkingen
De Covid-pandemie en de daaropvolgende lockdowns hebben een sterke digitalisering van het onderwijs op gang gebracht. Cursussen werden via de computer gegeven en studenten konden op afstand examens afleggen. Het risico op fraude steeg.
Bedrijven bieden algoritmische oplossingen die geacht worden risicovol gedrag op te sporen en leraren te waarschuwen voor het risico van spieken. Zoals blijkt uit de zaak van deze student uit Florida (Engelse site), zijn de resultaten van het algoritme van Honorlock verre van overtuigend. Sommige onschuldige gedragingen kunnen als verdacht worden beschouwd en leiden tot diskwalificatie van de leerling. De algoritmische fout in dit geval is het resultaat van een verkeerde interpretatie van het gedrag van de leerling op de camera.
Wat kunnen we leren van deze algoritmische fout?
Zoals vaak het geval is met algoritmen, kan een foutief ontwerp alleen maar tot een ramp leiden. Het Honorlock-algoritme introduceert een aantal interpretatievertekeningen in het fraudegedrag. De analyse van het algoritme is gebaseerd op strikte regels en de leraar krijgt een score. Het gebrek aan nuance in de berekening van de score en de ondoorzichtigheid van de berekeningsmethode leiden tot oordelen die vernietigend kunnen zijn.

Illegaal gebruik van een targeting-algoritme door de Nederlandse belastingdienst
In de zogenaamde “toeslagenaffaire” is het leven van duizenden gezinnen met een bijstandsuitkering geruïneerd door een algoritme dat door de belastingdienst illegaal werd gebruikt om fraudeurs te identificeren. Sommige mensen pleegden uit wanhoop zelfmoord, meer dan duizend kinderen werden bij hun ouders weggehaald en miljoenen euro’s werden ten onrechte aan de staat terugbetaald. Het aantal slachtoffers wordt geschat op 2.200 met een mediaan verlies van 30.000 euro. In sommige gevallen bedroeg het verlies voor de belastingplichtige meer dan 150.000 euro.
De Nederlandse belastingdienst heeft verschillende rode lijnen overschreden met zijn algoritme en de manier waarop de resultaten zijn geïnterpreteerd:
- het algoritme identificeerde potentiële fraudegevallen en de belastingdiensten pasten zonder rechtvaardiging een Paretoregel toe: 80% fraude/20% onschuldig om hun onderzoek voort te zetten
- De gerichtheid was mede gebaseerd op de tweede nationaliteit van de belastingplichtige. De belastingdienst had geen rechtsgrondslag om deze variabele te analyseren. Uit een controle in 2020 bleek dat 4 andere fraudebestrijdingsalgoritmen van de belastingdienst ten onrechte gebruik maakten van deze variabele.
De zaak is zeer ernstig en de misbruiken van de Nederlandse belastingdienst zijn zwaar bestraft door het College Bescherming Persoonsgegevens, dat een boete van 3,6 miljoen euro heeft opgelegd.
Wat kunnen we leren van deze algoritmische fout?
Deze zaak leidt tot 3 lessen:
- De variabelen die door een algoritme worden gebruikt om de berekening uit te voeren, moeten een rechtsgrondslag hebben
- Bepaalde variabelen kunnen alleen worden gebruikt als ze een oorzakelijk verband hebben met het verwachte resultaat. In de “toeslagenaffaire” was er geen empirische basis om aan te tonen dat de tweede nationaliteit een oorzaak was van fraude.
- De resultaten van een richtalgoritme moeten worden gezien voor wat ze zijn, namelijk werkhypothesen. Bij de toepassing van de 80/20-regel hebben de Nederlandse belastingambtenaren zich schuldig gemaakt aan nalatigheid en amateurisme.

Vooringenomen algoritme voor studentenoriëntatie in het hoger onderwijs
De zaak van het Franse universitaire selectiealgoritme (Franse site) brak in 2016 uit. Met het algoritme, APB genaamd, konden universiteiten studenten van de middelbare school selecteren. De variabelen die door dit algoritme worden gebruikt om het lot van studenten te bepalen, werden geheim gehouden totdat een advocaat het ministerie van Onderwijs aanklaagde. Toen werd ontdekt dat de gebruikte variabelen geen rechtsgrondslag hadden. Erger nog, sommige variabelen die bij de berekening van het algoritme werden gebruikt, waren duidelijk discriminerend (leeftijd, land van herkomst) of totaal ongerijmd (derde naam). Het aantal “slachtoffers” van dit algoritme is niet bekend, maar men kan met recht denken dat duizenden leerlingen zijn benadeeld door algoritmische keuzes die in weerwil van het gezond verstand zijn gemaakt.
Wat kunnen we leren van deze algoritmische fout?
De programmeerfouten van het APB-algoritme liggen voor de hand. Het algoritme is niet ontworpen om de belangen van binnenkomende studenten te maximaliseren, maar die van de universiteiten.
Het APB-algoritme is in feite een eenvoudige “business rule”-formule. De in aanmerking genomen variabelen vertonen geen oorzakelijk verband met een gunstige doelstelling voor de leerling. Het zou bijvoorbeeld veel relevanter zijn geweest om rekening te houden met variabelen die het succespercentage van studenten op de universiteit maximaliseren. Het perfecte algoritme had de student de beste keuze kunnen voorstellen om te slagen, terwijl het hem/haar vrij liet om voor een minder gunstige oplossing te kiezen (bijvoorbeeld een instelling dichter bij huis).

Censuur van inhoud door het algoritme van TikTok
Het aanbevelingsalgoritme is een hoeksteen van het succes van Tik Tok. Het in China ontstane platform wordt ervan beschuldigd de zichtbaarheid van door de LGBTQ+-gemeenschap geplaatste inhoud kunstmatig te verminderen. Deze algoritmische uitsluiting komt goed tot uiting in deze kwalitatieve studie (Engelse site). Uit een audit (Engelse site) van het Australian Strategic Policy Institute (ASPI) blijkt dat trefwoorden die door een hashtag worden geïdentificeerd, op TikTok worden gecensureerd. Het algoritme is geprogrammeerd om inhoud met betrekking tot homoseksualiteit, bepaalde gevoelige politieke onderwerpen en publieke figuren te verbergen. The Guardian meldt dat in juni 2020 een lijst van 20 persoonlijkheden is opgesteld die niet op TikTok mogen verschijnen. Onder hen zijn Kim Jong-il, Kim Jong-Un, Vladimir Poetin en Donald Trump.
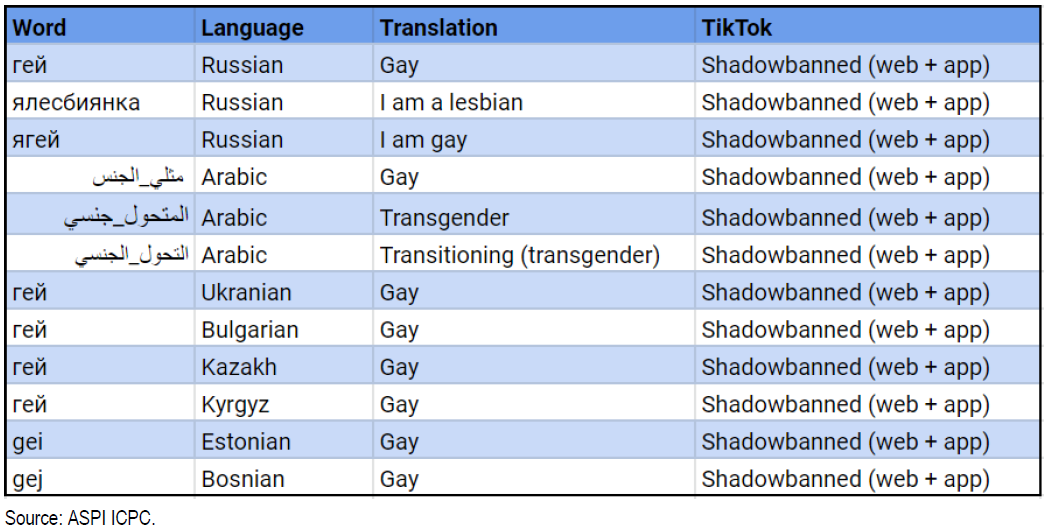
Wat kunnen we leren van deze algoritmische fout?
Het geval van het TikTok-algoritme is misschien het minst waarschijnlijk een algoritmische fout. Het algoritme deed precies wat de ontwerpers bedoelden, namelijk bepaalde inhoud censureren. Uiteindelijk was het dus een menselijke vooringenomenheid die ertoe leidde dat het algoritme op een “gerichte” manier werd geprogrammeerd.





