

Le risposte generate da ChatGPT sono uniche? O stiamo sopravvalutando la sua capacità di produrre testi diversi? Questa è la domanda che mi sono posto dopo aver analizzato 1000 testi prodotti da ChatGPT. Ho confrontato la somiglianza tra 1.000.000 di coppie di testi generati da questa intelligenza artificiale per rispondere a questa domanda. I risultati sono sorprendenti e sfidano la promessa di OpenAI. In questo articolo scopriremo i risultati della nostra analisi e l’impatto futuro che ha sulla generazione di testi. Per stare al passo con la mia analisi, prendiamo in considerazione l’iscrizione alla newsletter settimanale e seguimi su LinkedIn.
ChatGPT: tutti i risultati in 30 secondi
- ChatGPT produce risposte abbastanza simili quando gli si pone più volte la stessa domanda. In media, la somiglianza varia tra il 70 e il 75%.
- Qualunque sia la domanda, gli “incidenti” si verificano, generando risposte molto diverse dalle altre. La somiglianza minima misurata è del 40%.
- ChatGPT ha un’affascinante capacità di produrre risposte simili a domande diverse. La somiglianza media tra le risposte di ChatGPT a domande diverse è del 60,93%.
- La lunghezza delle risposte proposte da ChatGPT per la stessa domanda varia notevolmente. I 1000 testi prodotti presentano variazioni massime del +176% e del -70%.
Sommario
- Metodologia
- Scopri quanto è coerente ChatGPT: la somiglianza delle sue risposte alla stessa domanda
- L’affascinante capacità di ChatGPT di produrre risposte simili a domande diverse
- Bonus: i testi prodotti da ChatGPT sono sempre della stessa lunghezza?
- Appendice
Metodologia: da leggere per comprendere i seguenti risultati
L’obiettivo di questa ricerca è indagare quanto siano diverse le risposte fornite da ChatGPT. Questo è un progetto di ricerca complesso, che ho dovuto suddividere in diversi esperimenti. Presento oggi i risultati del primo. Iscriviti alla mia newsletter in modo da poter vedere i prossimi.
Generazione del corpus ricercato
In questo primo esperimento, ho chiesto a ChatGPT di scrivere un articolo su un argomento specifico (vedi un esempio sotto). È stato proposto uno schema per strutturare le risposte. Sono stati definiti venti argomenti (vedi Elenco alla fine di questo articolo). La richiesta fatta a ChatGPT era sempre la stessa. È cambiata solo la parola chiave tra virgolette.

Voglio imporre un piano particolare per venire incontro alle esigenze dei creatori di contenuti che, quando cercano di posizionarsi su parole chiave generiche, adottano una struttura che molto spesso è la stessa. Per questo primo test, ho seguito un piano molto semplice. Il secondo esperimento rimuoverà logicamente le indicazioni relative al piano dell’articolo per osservare come reagisce ChatGPT.
Questa struttura mi permetterà anche di confrontare articoli scritti senza intelligenza artificiale per questo blog. A titolo di esempio, ecco l’articolo dedicato all’activation marketing.

Ogni risposta è stata rigenerata 50 volte, una dopo l’altra, senza interruzioni. Quando il processo di rigenerazione è stato interrotto da un problema tecnico, è stato necessario ricominciare il lavoro da zero.
Di seguito un esempio della risposta ottenuta alla domanda posta sopra.

Preparazione ed elaborazione dei dati
L’elaborazione e l’analisi dei dati sono state effettuate con Anatella. La visualizzazione dei dati è stata effettuata utilizzando Tableau.
Questo progetto non avrebbe potuto essere realizzato senza Anatella. Questo ETL è stato infatti cruciale per almeno 2 aspetti:
- calcolare le somiglianze in modo facile e soprattutto veloce (44 secondi per calcolare la somiglianza tra 1 milione di coppie di testi)
- DE che esegue il pivot dei dati in modo che possano essere importati in Tableau (utilizzando Tableau, è possibile gestire un massimo di 700 colonne, ma la mia matrice di somiglianza più grande aveva 1000 righe e 1000 colonne)
Per maggiori informazioni sulla preparazione dei dati, vi rimando alla fine di questo articolo, dove spiego i passaggi necessari per effettuare la preparazione dei dati.
Scopri quanto è coerente ChatGPT: la somiglianza delle sue risposte alla stessa domanda
In primo luogo, l’obiettivo era confrontare le risposte alla stessa domanda. La somiglianza dei testi prodotti è stata misurata grazie al metodo Dice, di cui ho già parlato qui. Quindi, ho confrontato le 50 iterazioni di ciascuna delle 20 domande.
Otteniamo 20 matrici di 50×50 che potete vedere qui sotto. Il colore dà un’idea del tasso di somiglianza. Più è leggero, minore è la somiglianza. Non volevo ingombrare il grafico con dettagli inutili perché intendevo solo dare una panoramica “grafica” dell’insieme.
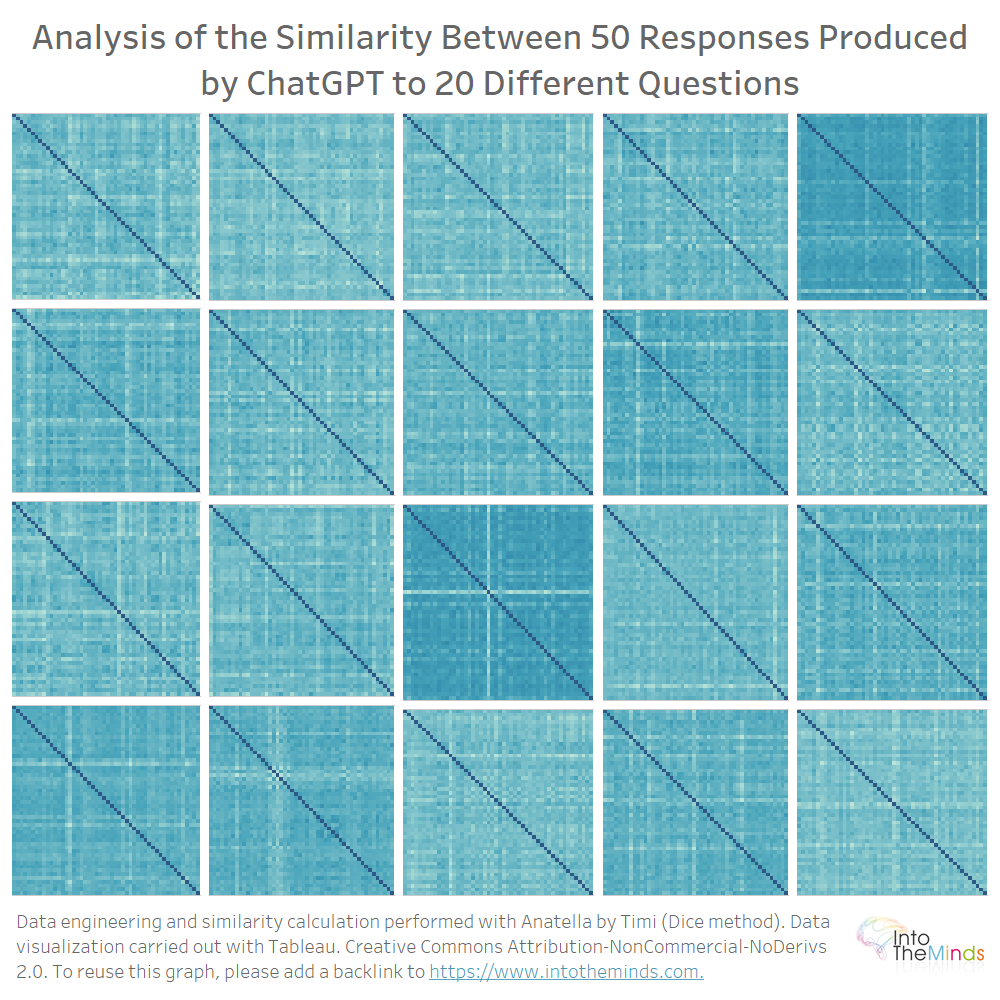
Quindi, si nota che le differenze sono piuttosto pronunciate. Per alcune serie, tutte le iterazioni sono simili; per altri, ci sono variazioni abbastanza forti.
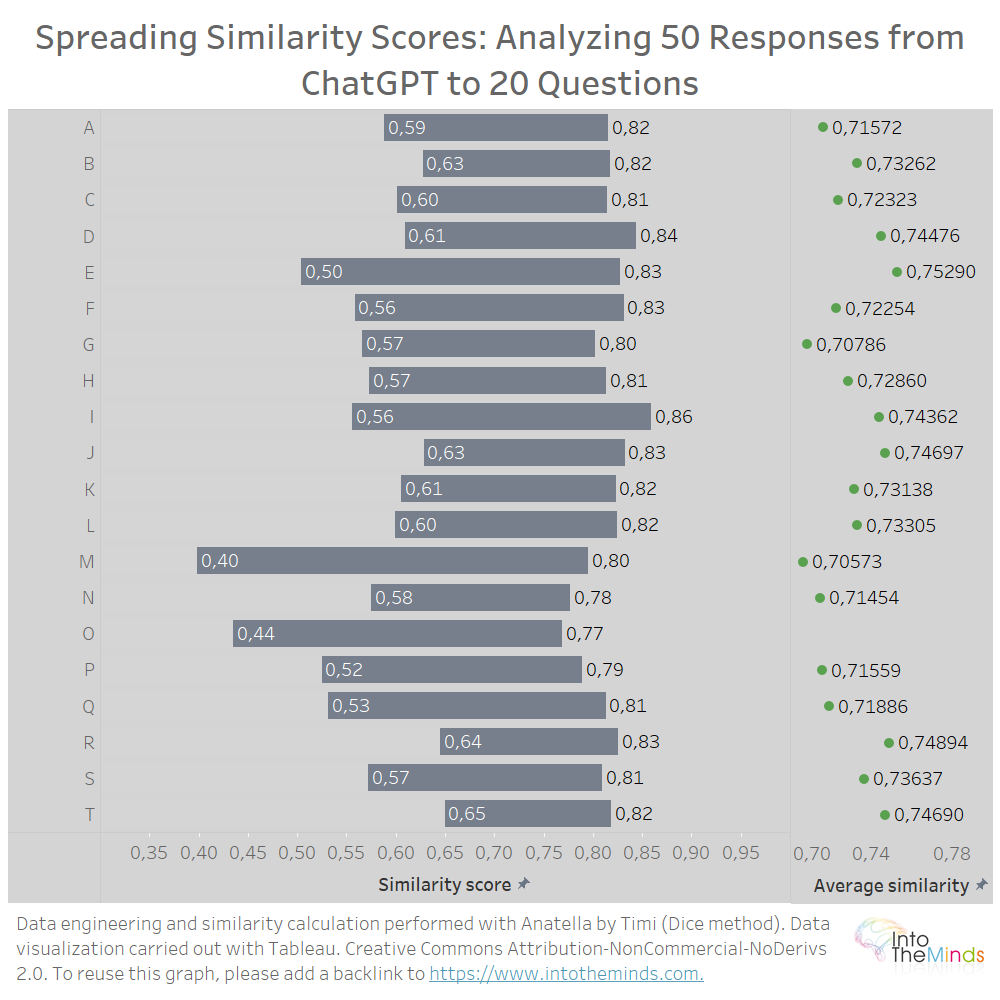
In media, ChatGPT produce risposte simili quando gli fai la stessa domanda più volte. In particolare, il coefficiente di somiglianza più basso è 0,40 (domanda M) e il più alto è 0,86 (domanda I). La dispersione dei coefficienti di similarità è rappresentata nel grafico sottostante. Si può anche leggere la somiglianza media per ogni serie. Si noterà che tutti i valori sono compresi tra 0,7 e 0,75.
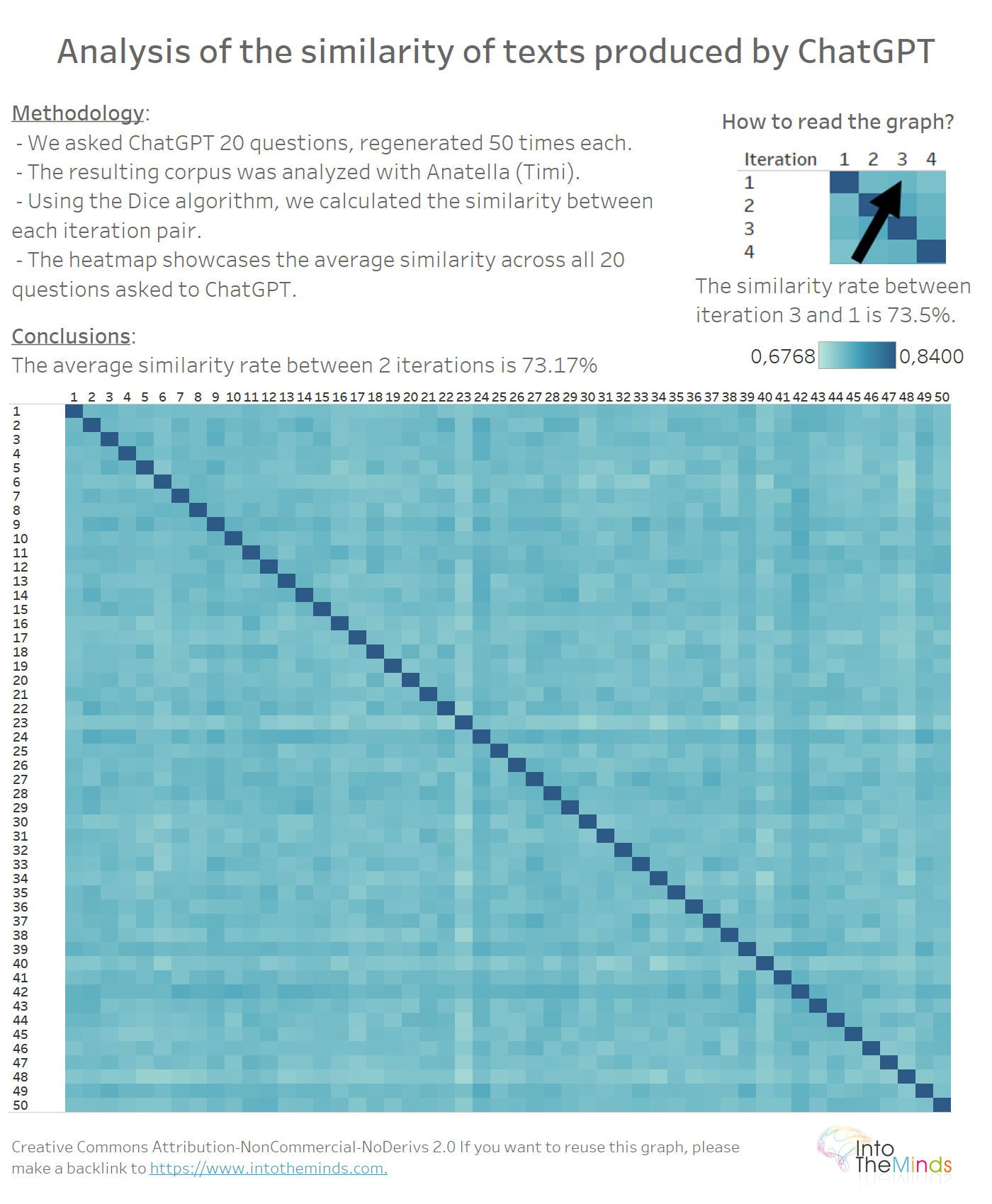
Possiamo osservare una progressiva “deriva” delle risposte man mano che le iterazioni vanno avanti? In altre parole, ChatGPT produce, con il passare delle iterazioni, risposte sempre più lontane dalla prima iterazione?
Per rispondere a questa domanda è sufficiente effettuare una heatmap tra le 50 iterazioni della serie 20. Non c’è uno schema particolare nei dati. Questo indica che ogni risposta ChatGPT viene rigenerata senza considerare quella precedente. Il tasso medio di somiglianza è del 73,17%.
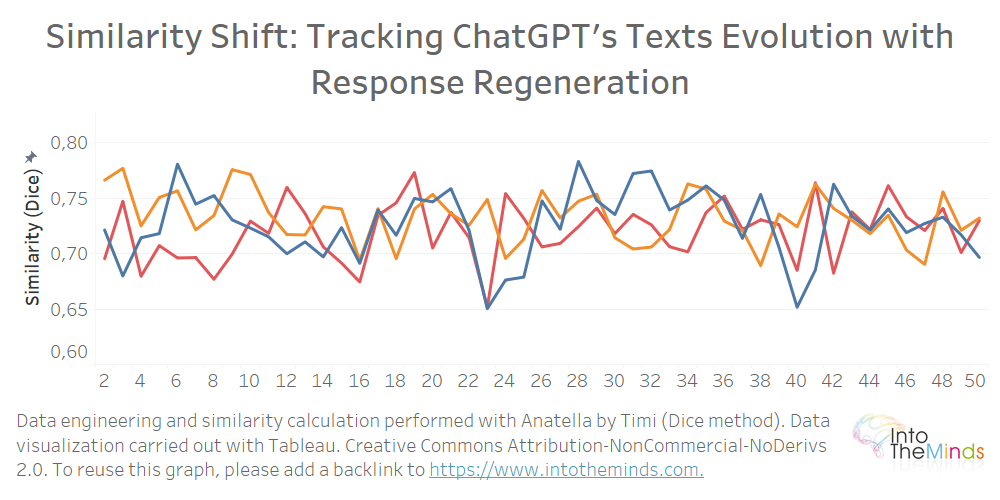
Isolando una serie e confrontando ogni iterazione con la prima risposta, possiamo vedere che la somiglianza non diminuisce. Nel grafico sottostante ho isolato le serie A, B e C e ho calcolato la somiglianza di ogni risposta prodotta da ChatGPT rispetto al primo testo prodotto. Il grafico inizia logicamente all’iterazione 2 poiché il punto di confronto è il testo iniziale (iterazione 1).
Cosa possiamo imparare da questa analisi?
Ecco alcune lezioni da trarre da questa prima analisi:
- Quando chiedi a ChatGPT la stessa domanda più volte, non aspettarti di ottenere risposte fondamentalmente diverse. Sono strutturalmente abbastanza simili. Questo è normale poiché la “meccanica” algoritmica dietro ChatGPT crea frasi basate sulla parola successiva più probabile. Quindi, logicamente, troviamo strutture di frasi simili da un’iterazione all’altra.
- Questa ricerca misura oggettivamente il tasso di somiglianza tra le risposte. Come minimo, il tasso di somiglianza è del 40%. Al massimo, è dell’86%. In media, è del 73%.
Due testi prodotti da ChatGPT su argomenti diversi possono essere simili per metà o per 2/3.
L’affascinante capacità di ChatGPT di produrre risposte simili a domande diverse
La nostra metodologia si basa su domande identiche in cui cambia solo l’oggetto della query. Da quel momento in poi, diventa possibile confrontare le risposte a diverse domande.
Ecco un esempio concreto. Quanto vicino ChatGPT scrive i testi sull’activation marketing (argomento A) a quelli sull’astroturfing (argomento B)? L’esercizio è simile a quello svolto nella prima parte di questo articolo. La differenza sta nell’aggregazione che si è dovuta fare dei punti relativi alla stessa domanda (serie A-T). Per eseguire questa operazione, la preparazione dei dati in Anatella si è rivelata fondamentale perché era necessario confrontare le serie tra di loro. Salterò gli aspetti tecnici e parlerò dei risultati. È per questo che sei qui, vero? ?
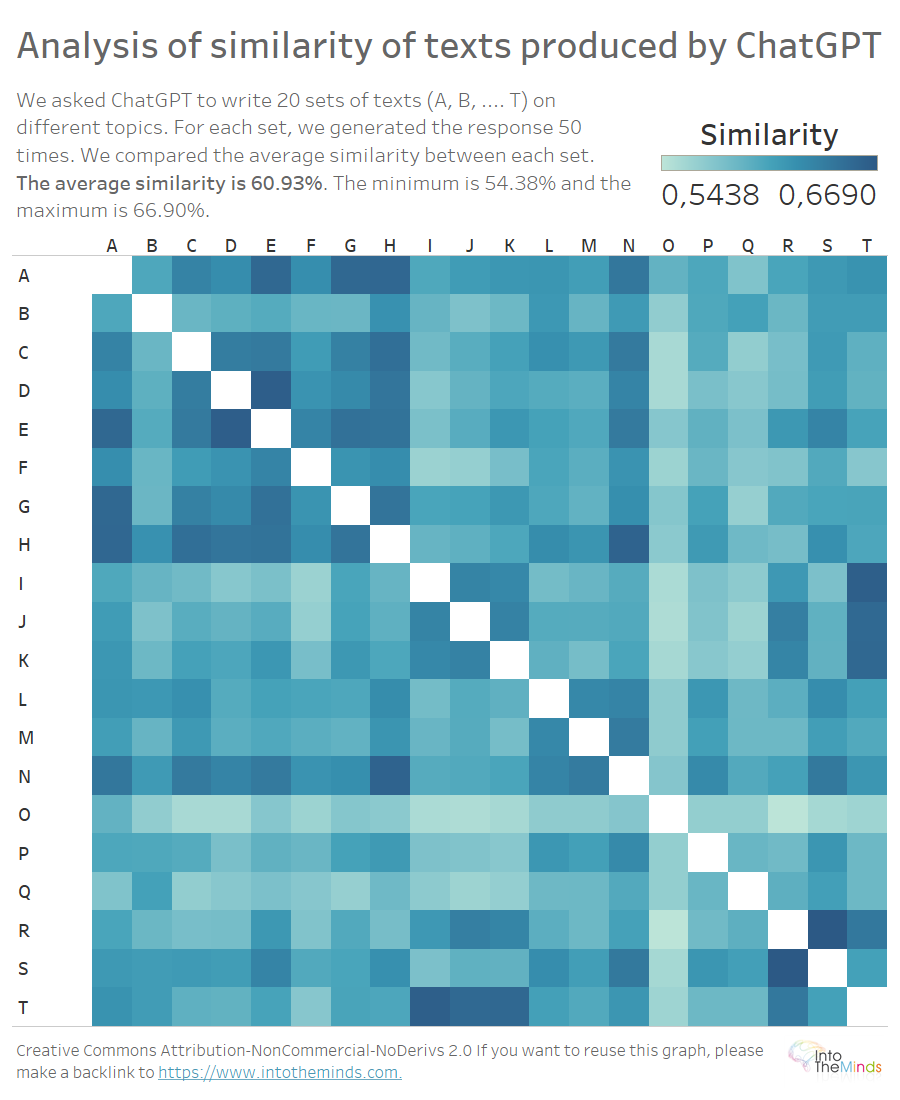
La heatmap qui sopra permette di visualizzare la somiglianza tra i testi prodotti per ogni domanda. Ricorda che ogni lettera (da A a T) rappresenta una domanda diversa. L’argomento differisce da set a set; il piano è lo stesso (definizione – esempi – conclusioni – riferimenti). È ragionevole che la somiglianza tra testi su argomenti diversi sia bassa. Non lo è. La somiglianza minima è del 54,38% e quella massima del 66,90%. La somiglianza media è del 60,93%. Ciò significa che nel nostro esperimento, due testi prodotti da ChatGPT su argomenti diversi possono essere simili per metà o per 2/3.
Cosa possiamo imparare da questa analisi?
La lezione principale di questa analisi è che ChatGPT può produrre risposte simili a domande diverse. Il prossimo esperimento è un’opportunità per capire meglio il funzionamento dell’algoritmo non imponendo un progetto. Il design imposto ha qualcosa a che fare con questo.
Bonus: i testi prodotti da ChatGPT sono sempre della stessa lunghezza?
Per concludere questa ricerca, propongo di esplorare la variazione nella lunghezza dei testi prodotti da ChatGPT. Poiché su ChatGPT viene imposto un piano, i testi dovrebbero essere tutti della stessa lunghezza. Anche qui varia.
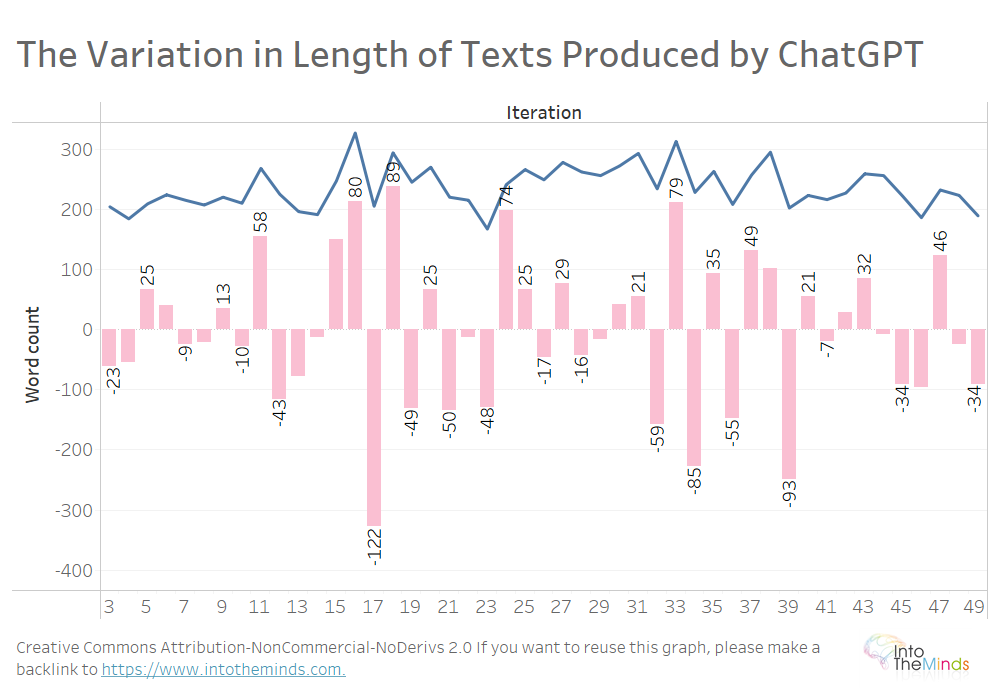
Cominciamo guardando la Serie A, le 50 iterazioni di testi prodotti da ChatGPT sull’activation. Il testo medio è lungo 237 parole. Ma tra un’iterazione e l’altra, la lunghezza può variare notevolmente. Tra l’iterazione 16 e l’iterazione 17, il testo prodotto da ChatGPT perde 122 parole, da 328 a 206 parole.
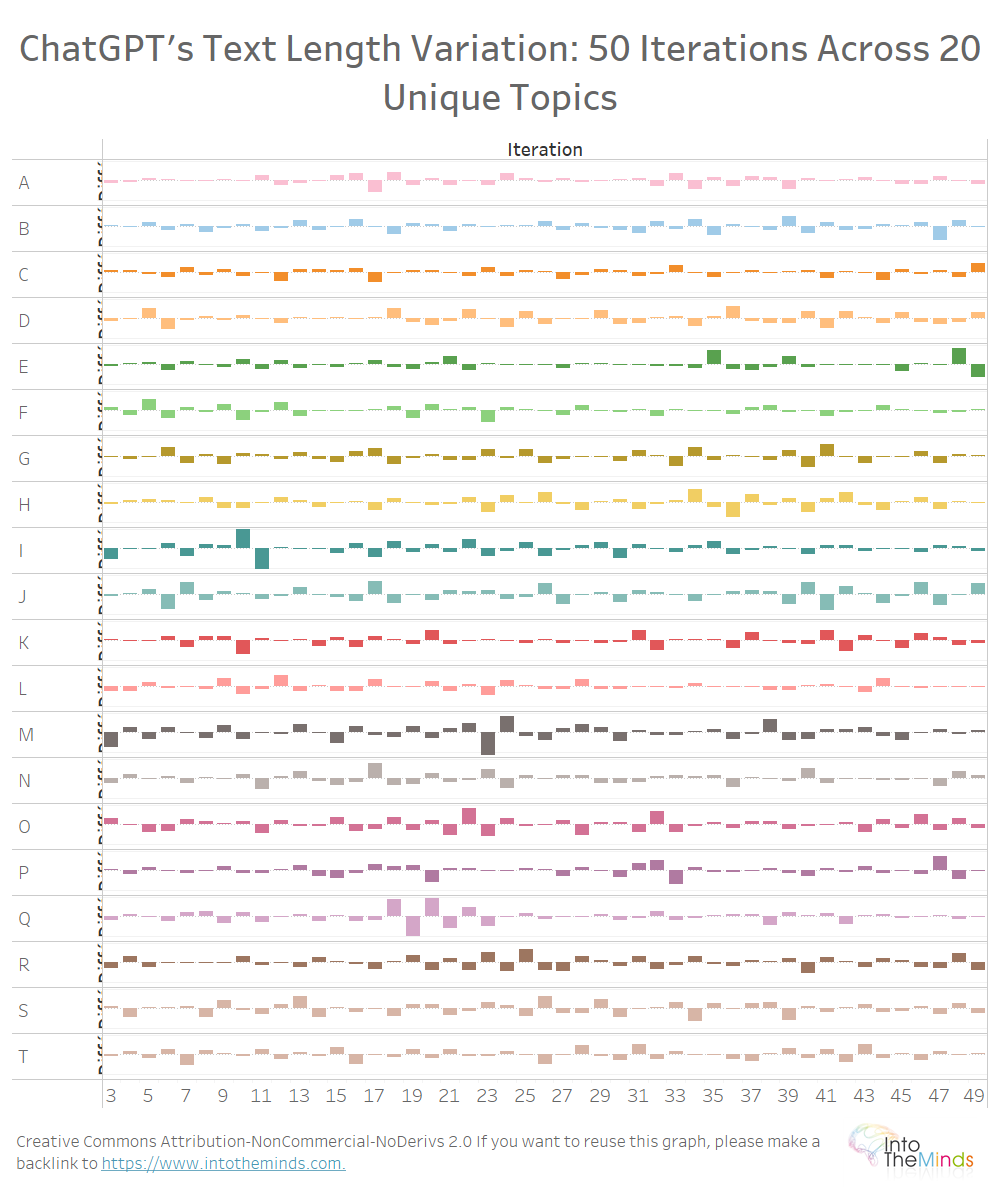
Su tutti i 20 argomenti si possono osservare le stesse variazioni (grafico sotto). Non volevo rendere la visualizzazione troppo pesante, ma ecco le variazioni massime:
- +200 parole tra le iterazioni 9 e 10 per l’argomento I (“Net Promoter Score”)
- 232 parole tra le iterazioni 22 e 23 per l’argomento M (“Marketing delle celebrità”)
Sull’insieme dei 1000 testi prodotti, le variazioni relative massime sono state:
- +176%
- -70%
Cosa possiamo imparare da questa analisi?
ChatGPT produce risposte che variano ampiamente, almeno nella lunghezza del testo. I 1000 testi prodotti presentano variazioni massime del +176% e del -70%. La lunghezza dei testi è quindi molto fluttuante.
Rigenererò l’intero corpus nel prossimo esperimento imponendo un conteggio delle parole. Questo mi permetterà di ricercare il rispetto dell’istruzione e la dispersione dei risultati attorno al target.
Appendice
La procedura di preparazione dei dati in Anatella
Innanzitutto, Anatella è un software ETL (Extract – Transform – Load) che consente di lavorare sui dati prima di reinserirli in un altro software. È il mio ETL preferito per diversi motivi:
- in primo luogo perché è ultraveloce (vedi un benchmark qui).
- in secondo luogo, propone una gamma di strumenti molto più ampia rispetto ai concorrenti. Si possono, quindi, affrontare facilmente problemi complessi.
- l’editor (Timi) è molto reattivo e mi ha persino fornito una funzionalità personalizzata per rispondere facilmente a un’esigenza specifica (calcola la somiglianza tra un gran numero di coppie di testo (vedi flusso 2 di seguito)
In Anatella sono stati creati tre specifici flussi di preparazione dei dati.
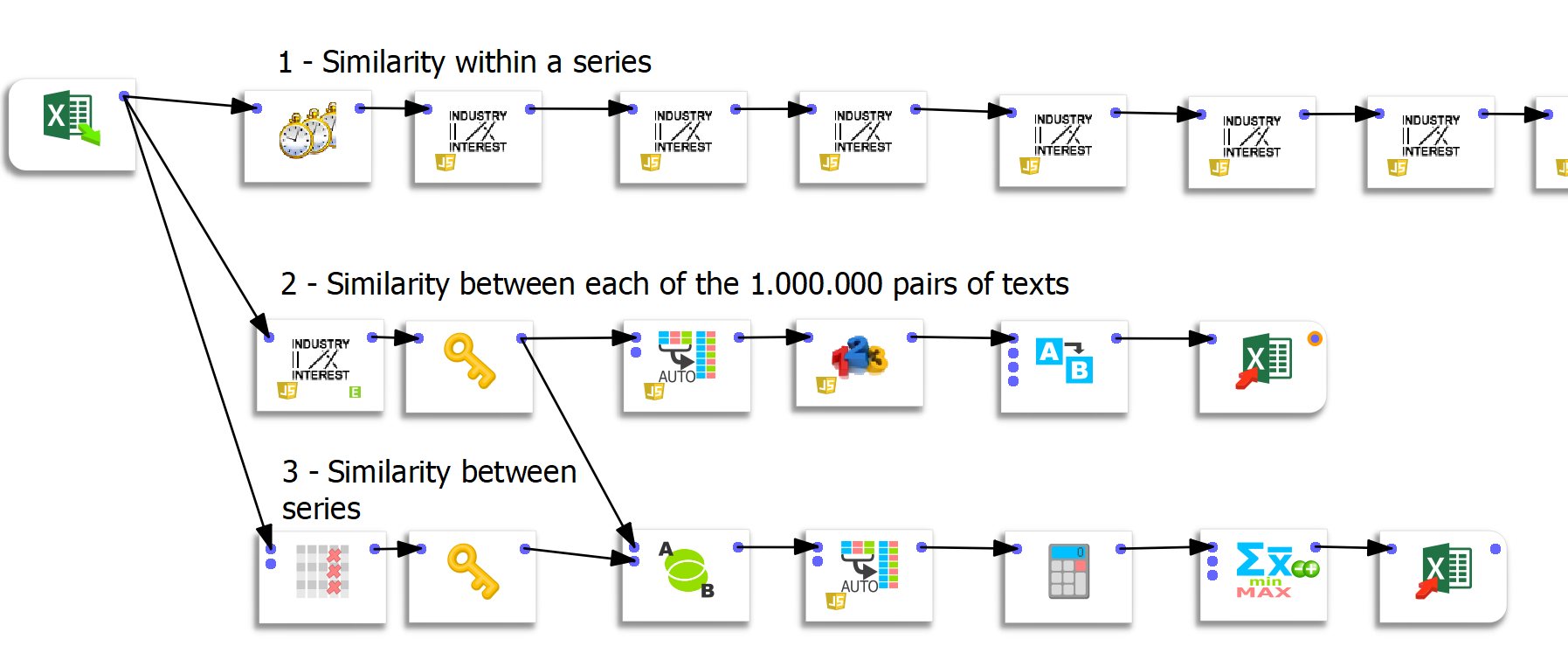
Flusso 1: calcola le somiglianze all’interno di una serie
Questo primo flusso è semplice ma piuttosto ridondante. Le caselle seguenti (ce ne sono 50) calcolano la somiglianza tra l’iterazione n e l’iterazione 1. Le prime 2 caselle ci permettono di calcolare la somiglianza di un’iterazione rispetto alla precedente.
Flux 2 : calcul des similarités entre chaque paire de texte
Per questo flusso, ringrazio Frank Vanden Berghen per avermi fornito funzionalità su misura. Ho già parlato a lungo delle qualità di Anatella, e la velocità di esecuzione è un vantaggio rispetto ad altri ETL. La sfida qui era calcolare rapidamente la somiglianza tra ogni coppia di testi. Sapendo che c’erano 50 iterazioni per ciascuna delle 20 domande, ciò rappresentava 1000²=1.000.000 di possibilità. Sottolineo qui l’estrema velocità del processo poiché il calcolo di un milione di somiglianze richiede solo 44 secondi.
La funzione “unflatten” di Anatella si è rivelata molto utile in questo esercizio. Per inserire dati in Tableau, i dati devono essere “non appiattiti”. Tuttavia, Tableau gestisce solo un massimo di 700 colonne. Poiché la matrice è lunga 1000 colonne, è stato possibile visualizzare i dati solo preparandoli all’esterno di Tableau.
Flusso 3: calcolo della similarità tra serie
L’ultimo flusso genera una matrice tra le serie. Si tratta quindi di una matrice 20×20. La funzione “raggruppa per” prima dell’esportazione in Excel ci consente di fare la media dei valori di somiglianza.
Lista di argomenti
Di seguito l’elenco degli argomenti che sono stati inviati a ChatGPT.
| Refimento | Oggetto |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |



![Illustrazione del nostro articolo "Rilevatori di IA generativa gratuiti: quali scegliere? [Test completo 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)
![Illustrazione del nostro articolo "Risorse umane: stato della digitalizzazione dei processi [Studio]"](/blog/app/uploads/concept-shapes-120x90.jpg)
![Illustrazione del nostro articolo "Handicap e inclusione: tra obblighi e realtà in azienda [Studio]"](/blog/app/uploads/banner-blind-aveugle-120x90.webp)