

Est-ce que chaque réponse générée par ChatGPT est vraiment unique ? Ou sommes-nous en train de surestimer sa capacité à produire des textes différents ? C’est la question que je me suis posée après avoir analysé 1000 textes produits par ChatGPT. Pour répondre à cette question, j’ai comparé la similarité entre 1.000.000 de paires de textes générés par cette intelligence artificielle. Les résultats sont étonnants et remettent en question la promesse d’OpenAI. Découvrez dans cet article les résultats de notre analyse approfondie et ce que cela signifie pour l’avenir de la génération de texte. Pour être tenu au courant de mes analyses, pensez à vous abonner à la newsletter hebdomadaire et à me suivre sur Linkedin.
ChatGPT : tous les résultats en 30 secondes
- ChatGPT produit des réponses assez similaires lorsque vous lui posez plusieurs fois la même question. En moyenne la similarité varie entre 70 et 75%.
- Quelle que soit la question, des « accidents » se produisent, engendrant des réponses assez différentes des autres. La similarité minimum mesurée est de 40%
- ChatGPT a une capacité fascinante à produire des réponses similaires à des questions différentes. La similarité moyenne entre les réponses de ChatGPT à des questions différentes est de 60,93%.
- La longueur des réponses proposées par ChatGPT pour une même question varie largement. Les 1000 textes produits montrent des variations maximales de +176% et -70%.
Sommaire
- Méthodologie
- Découvrez à quel point ChatGPT est cohérent : similitude de ses réponses à une même question
- La fascinante capacité de ChatGPT à produire des réponses similaires à des questions différentes
- Bonus : les textes produits par ChatGPT sont ils toujours de la même longueur ?
- Annexes
Méthodologie : à lire avant pour bien comprendre les résultats après
Le but de cette recherche est d’investiguer à quel point les réponses données par ChatGPT sont vraiment différentes les unes des autres. Il s’agit d’un projet de recherche complexe, que j’ai dû diviser en plusieurs expériences. Je vous présente aujourd’hui les résultats de la première. Abonnez-vous à ma newsletter pour ne rien manquer des prochaines.
Génération du corpus étudié
Dans cette première expérience, j’ai demandé à ChatGPT d’écrire un article sur un sujet précis (voir un exemple ci-dessous). Un plan a été proposé afin de structurer les réponses. Vingt sujets (voir liste à la fin de cet article) ont été définis. La demande formulée à ChatGPT était donc toujours la même. Seul le mot-clé entre guillemets changeait.

J’ai souhaité imposer un plan particulier pour répondre aux besoins des créateurs de contenus qui, lorsqu’ils cherchent à se positionner sur des mots-clés génériques, adoptent une structure qui est très souvent la même. Pour ce premier essai j’ai suivi un plan très basique. La deuxième expérience sera logiquement d’enlever les indications relatives au plan de l’article afin d’observer comment chatGPT réagit.
Cette structure va également me permettre de faire des comparaisons avec les articles rédigés sans intelligence artificielle pour ce blog. Voici à titre d’exemple l’article dédié à l’activation marketing.

Chaque réponse a été régénérée 50 fois, les unes à la suite des autres, sans interruption. Lorsque le processus de régénération était interrompu par un problème technique, le travail devait être repris de zéro.
Voici un exemple de réponse obtenue à la question posée plus haut.

Préparation et traitement des données
Le traitement et l’analyse des données ont été réalisés avec Anatella. La visualisation des données a été réalisée sous Tableau.
Je tiens à souligner que ce projet n’aurait pas pu être réalisé sans Anatella. Cet ETL s’est en effet montré crucial pour au moins 2 aspects :
- calculer les similarités facilement et surtout rapidement (44 secondes pour calculer la similarité entre 1 million de paires de textes)
- dépivoter les données afin qu’elles puissent être importées dans Tableau (sous Tableau, un maximum de 700 colonnes peuvent être gérées, or ma plus grosse matrice de similarité comportait 1000 lignes et 1000 colonnes)
Pour plus d’informations sur la préparation des données, je vous renvoie à la fin de cet article où j’explique les différentes étapes nécessaires à sa réalisation.
Découvrez à quel point ChatGPT est cohérent : similitude de ses réponses à une même question
Dans un premier temps, l’objectif a été de comparer entre elles les réponses à une même question. La similarité des textes produits a été mesurée grâce à la méthode de Dice dont j’avais déjà parlé ici. J’ai donc comparé entre elles les 50 itérations de chacune des 20 questions.
On obtient donc 20 matrices de 50×50 que vous pouvez voir ci-dessous. La couleur donne une idée du taux de similarité. Plus elle est claire, plus la similarité est faible. Je n’ai pas voulu encombrer le graphique de détails inutiles car mon intention était seulement de donner un aperçu « graphique » de l’ensemble.
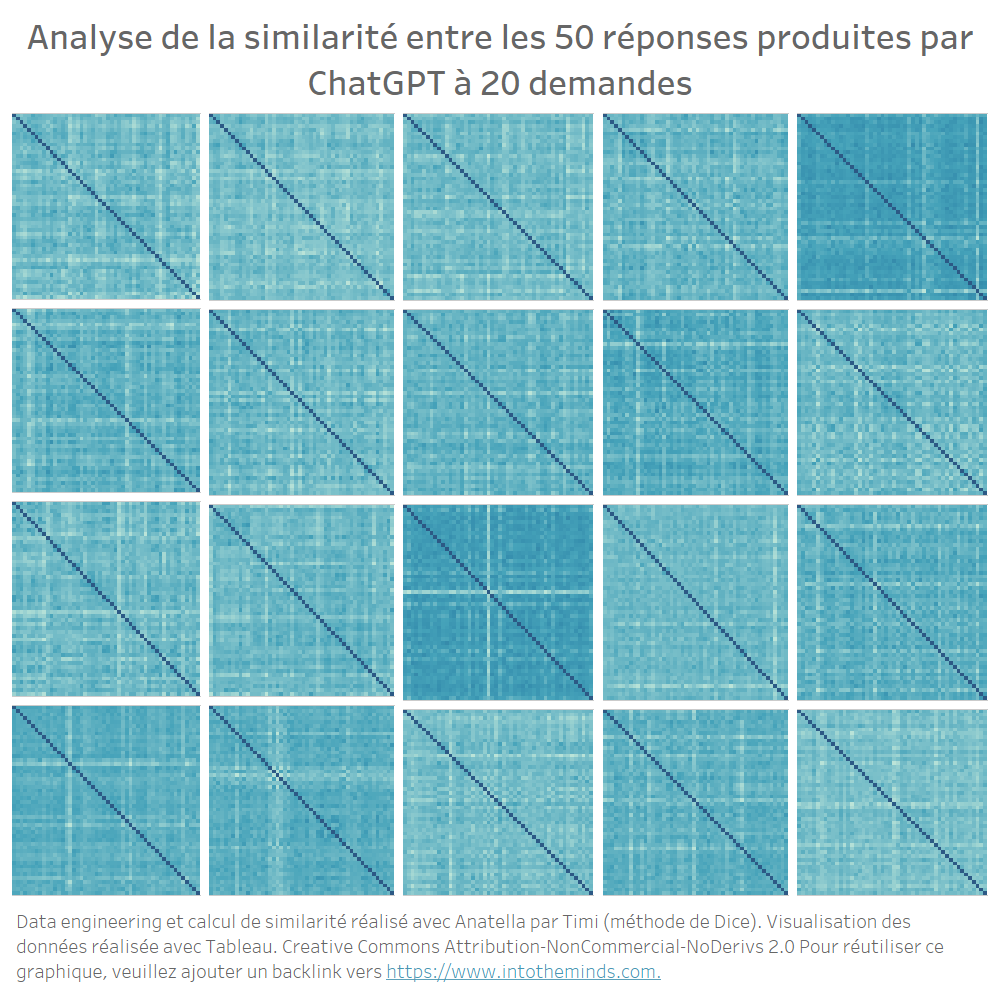
Vous pouvez donc constater visuellement que les différences sont assez prononcées. Pour certaines séries toutes les itérations se ressemblent ; pour d’autres il y a des variations assez fortes.
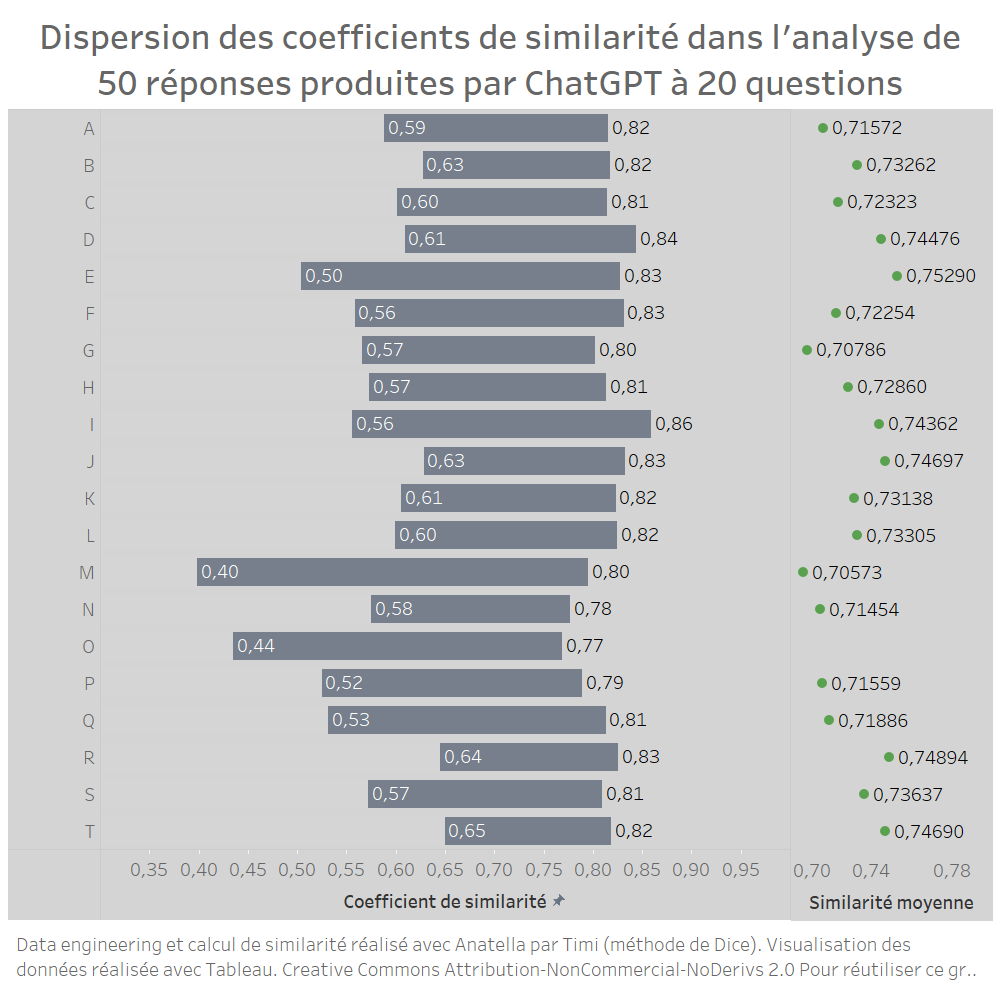
Concrètement le coefficient de similarité le plus bas est 0,40 (question M) et le plus élevé est 0,86 (question I). La dispersion des coefficients de similarité est représentée sur le graphe ci-dessous. Vous pouvez également y lire la similarité moyenne pour chacune des séries. Vous constaterez que toutes les valeurs sont entre 0,7 et 0,75. En moyenne, ChatGPT produit donc des réponses assez similaires lorsque vous lui posez plusieurs fois la même question.
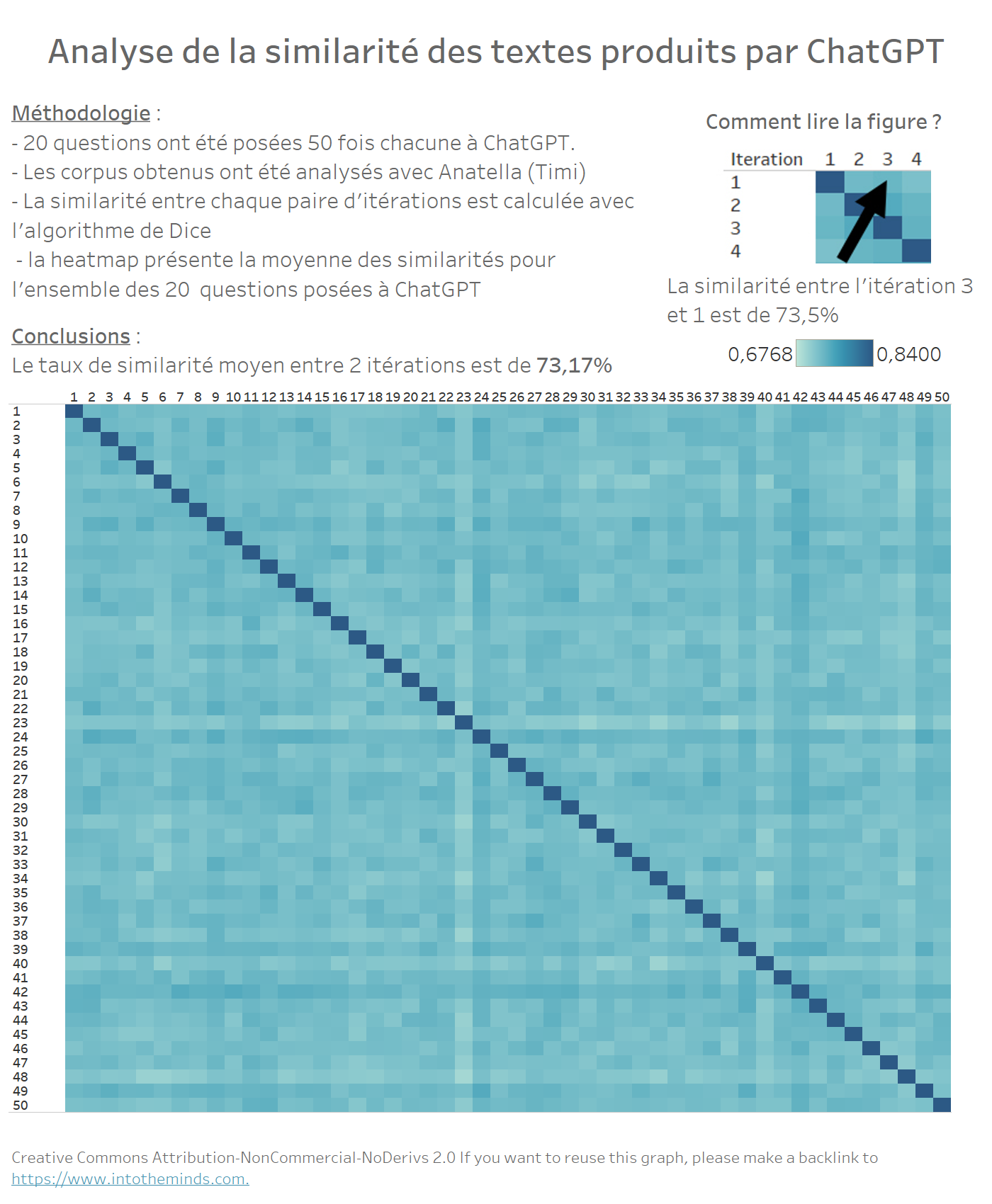
 Peut-on observer une « dérive » progressive des réponses au fur et à mesure des itérations ? En d’autres termes, ChatGPT produit-il, au fur et à mesure des itérations, des réponses qui s’éloignent de plus en plus de la première itération ?
Peut-on observer une « dérive » progressive des réponses au fur et à mesure des itérations ? En d’autres termes, ChatGPT produit-il, au fur et à mesure des itérations, des réponses qui s’éloignent de plus en plus de la première itération ?
Pour répondre à cette question il suffit de réaliser une carte de chaleur (heatmap) entre les 50 itérations des 20 séries. On ne note pas de pattern particulier dans les données. Cela indique que chaque réponse de ChatGPT est regénérée sans tenir compte de la précédente. Le taux de similarité moyen est de 73,17%.
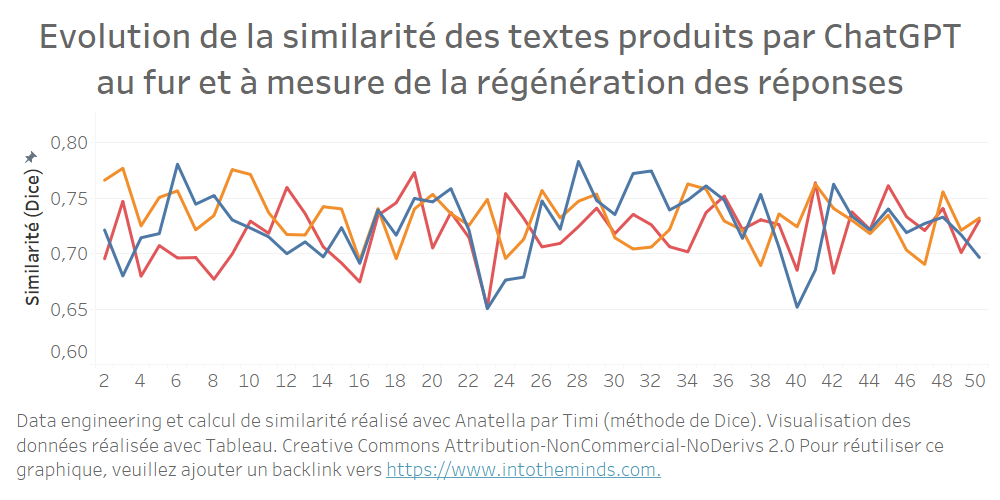
 En isolant une série, et en comparant chaque itération à la première réponse, on voit clairement que la similarité ne va pas en décroissant. Sur le graphique ci-dessous j’ai isolé les séries A, B et C et ai calculé la similarité de chaque réponse produite par ChatGPT par rapport au premier texte produit. Le graphique commence logiquement à l’itération 2 puisque le point de comparaison est le texte initial (itération 1).
En isolant une série, et en comparant chaque itération à la première réponse, on voit clairement que la similarité ne va pas en décroissant. Sur le graphique ci-dessous j’ai isolé les séries A, B et C et ai calculé la similarité de chaque réponse produite par ChatGPT par rapport au premier texte produit. Le graphique commence logiquement à l’itération 2 puisque le point de comparaison est le texte initial (itération 1).
Que retenir de cette analyse ?
Voici quelques enseignements à retenir de cette première analyse :
- lorsque vous posez plusieurs fois la même question à ChatGPT, ne vous attendez pas à obtenir des réponses fondamentalement différentes. Elles sont structurellement assez similaires. Au fond, cela est normal puisque la « mécanique » algorithmique derrière chatGPT fabrique des phrases en se basant sur le prochain mot le plus probable. On retrouve donc assez logiquement des tournures de phrases similaires d’une itération à l’autre.
- cette étude mesure objectivement le taux de similarité entre les réponses. Au minimum, le taux de similarité est de 40%. Au maximum, il est de 86%. En moyenne il est de 73%.
Deux textes produits par ChatGPT sur des sujets différents peuvent en fait être à moitié voire aux 2/3 similaires.
La fascinante capacité de ChatGPT à produire des réponses similaires à des questions différentes
La méthodologie que nous avons utilisée repose sur des questions identiques où seul le sujet de la demande change. Dès lors, il devient également possible de comparer les réponses à des questions différentes.
Voici un exemple concret. A quel point les textes rédigés par ChatGPT sur l’activation marketing (sujet A) sont-ils proches de ceux sur l’Astroturfig (sujet B) ? L’exercice est assez proche de celui qui a été fait dans la première partie de cet article. La différence réside dans l’agrégation qui a dû être faite des points relatifs à une même question (séries A à T). Pour effectuer cette opération, la data preparation sous Anatella s’est révélée indispensable car il a fallu comparer des séries entre elles. Je vais passer les aspects techniques pour tout de suite vous parler des résultats. Vous êtes là pour ça n’est-ce pas ? ?
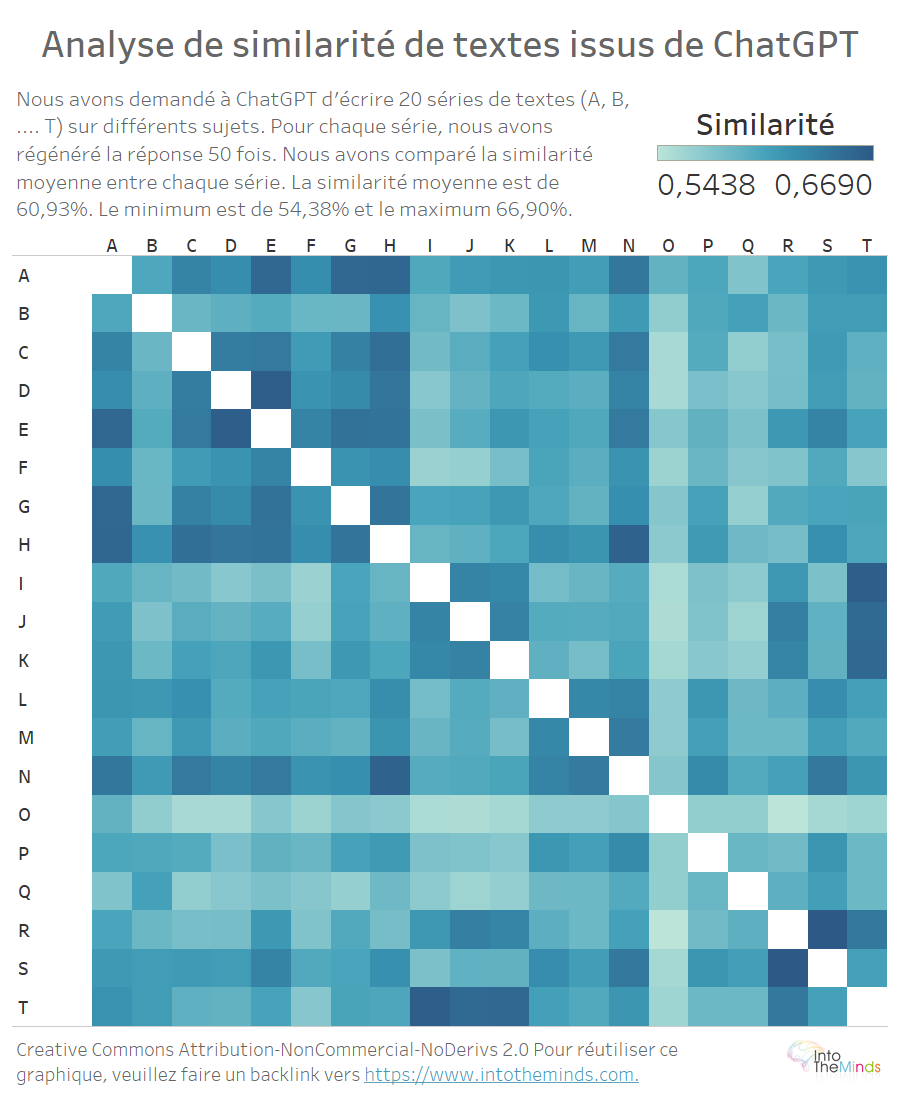 La carte de chaleur (heatmap) ci-dessus permet de visualiser les similarités entre les textes produits pour chaque question. Rappelez-vous que chaque lettre (A à T) représente une question différente. Le sujet est différent d’une série à l’autre ; seul le plan est le même (définition – exemples – conclusions – références). On peut donc raisonnablement s’attendre à ce que la similarité entre des textes sur des sujets différents soit faible. En fait il n’en est rien. La similarité minimum est 54,38% et la similarité maximum 66,90%. La similarité moyenne s’établit à 60,93%. Cela signifie que dans notre expérience, deux textes produits par ChatGPT sur des sujets différents peuvent en fait être à moitié voire aux 2/3 similaires.
La carte de chaleur (heatmap) ci-dessus permet de visualiser les similarités entre les textes produits pour chaque question. Rappelez-vous que chaque lettre (A à T) représente une question différente. Le sujet est différent d’une série à l’autre ; seul le plan est le même (définition – exemples – conclusions – références). On peut donc raisonnablement s’attendre à ce que la similarité entre des textes sur des sujets différents soit faible. En fait il n’en est rien. La similarité minimum est 54,38% et la similarité maximum 66,90%. La similarité moyenne s’établit à 60,93%. Cela signifie que dans notre expérience, deux textes produits par ChatGPT sur des sujets différents peuvent en fait être à moitié voire aux 2/3 similaires.
Que retenir de cette analyse ?
L’enseignement principal de cette analyse c’est que ChatGPT peut produire des réponses étonnamment proches à des questions différentes. Sans doute que le plan imposé y est pour quelque chose. La prochaine expérience sera donc l’occasion d’élargir la compréhension du fonctionnement de l’algorithme en n’imposant plus de plan.
Bonus : les textes produits par ChatGPT sont-ils toujours de la même longueur ?
Pour finir cette première étude, je vous propose d’explorer la variation dans la longueur des textes produits par ChatGPT. Puisqu’un plan est imposé à ChatGPT, logiquement les textes devraient tous être plus ou moins égaux en termes de longueur. Là encore, il n’en est rien.
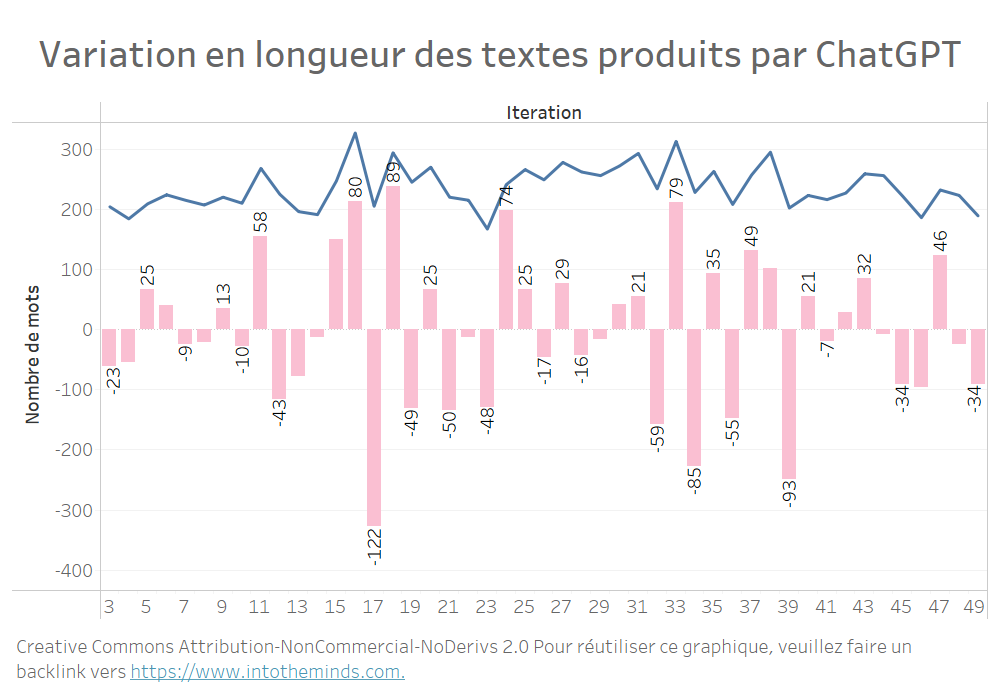 Examinons pour commencer la série A, c’est-à-dire les 50 itérations de textes produits par ChatGPT sur le thème de l’activation marketing. Les textes font en moyenne 237 mots. Mais entre une itération et l’autre, la longueur peut varier du tout au tout. Entre l’itération 16 et l’itération 17, le texte produit par ChatGPT perd 122 mots, passant de 328 à 206 mots.
Examinons pour commencer la série A, c’est-à-dire les 50 itérations de textes produits par ChatGPT sur le thème de l’activation marketing. Les textes font en moyenne 237 mots. Mais entre une itération et l’autre, la longueur peut varier du tout au tout. Entre l’itération 16 et l’itération 17, le texte produit par ChatGPT perd 122 mots, passant de 328 à 206 mots.
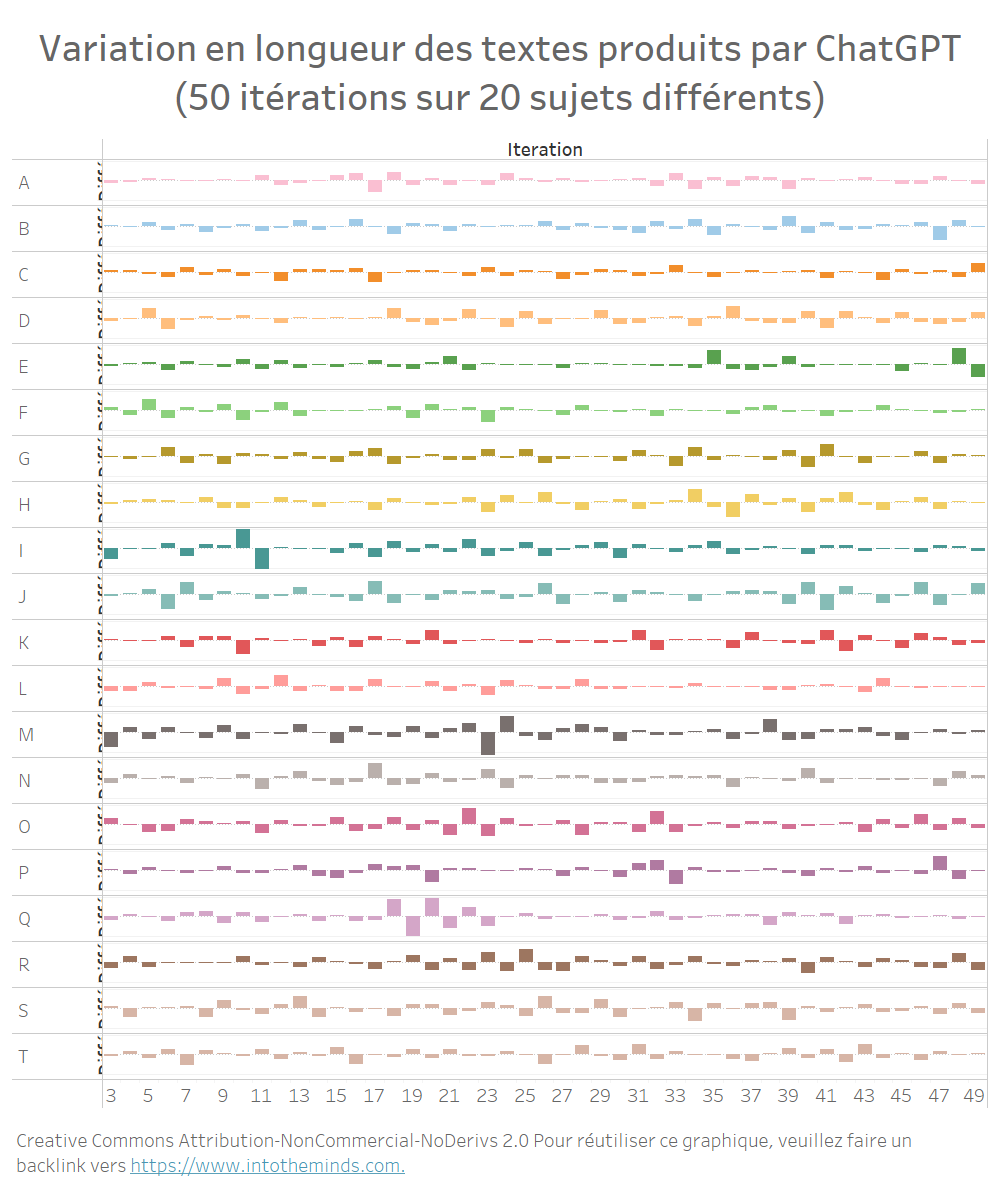
Sur l’ensemble des 20 sujets traités, les mêmes variations peuvent être observées (graphique ci-dessous). Je n’ai pas voulu alourdir la visualisation mais voici les variations maximales :
- +200 mots entre les itérations 9 et 10 pour le sujet I (« Net Promoter Score »)
- -232 mots entre les itérations 22 et 23 pour le sujet M (« Celebrity marketing »)
Sur l’ensemble des 1000 textes produits, les variations maximales relatives ont été :
- +176%
- -70%
Que retenir de cette analyse ?
ChatGPT produit bien des réponses qui varient en effet assez largement, au moins en termes de longueur du texte. Les 1000 textes produits montrent des variations maximales de +176% et -70%. La longueur des textes est donc très fluctuante.
Dans une prochaine expérience, je vais régénérer l’ensemble du corpus en imposant un nombre de mots. Ceci me permettra d’étudier le respect de l’instruction et la dispersion des résultats autour de l’objectif.
Annexes
Procédure de préparation des données sous Anatella
Je rappelle avant toute chose qu’Anatella est un logiciel de type ETL (Extract – Transform – Load) qui permet de travailler les données avant de les réinjecter dans un autre logiciel. C’est mon ETL de prédilection pour plusieurs raisons :
- d’abord parce qu’il est ultra rapide (voir un benchmark ici).
- ensuite parce qu’il propose en standard une palette d’outils largement plus étendue que celle des concurrents. Vous pouvez donc aborder facilement des problèmes complexes.
- la société éditrice (Timi) est hyper réactive et m’a même mis à disposition une fonctionnalité sur-mesure afin de répondre facilement à un besoin spécifique (calculer la similarité entre un nombre importants de paires de textes (voir flux 2 ci-dessous)
Trois flux distincts de préparation des données ont été créés sous Anatella.
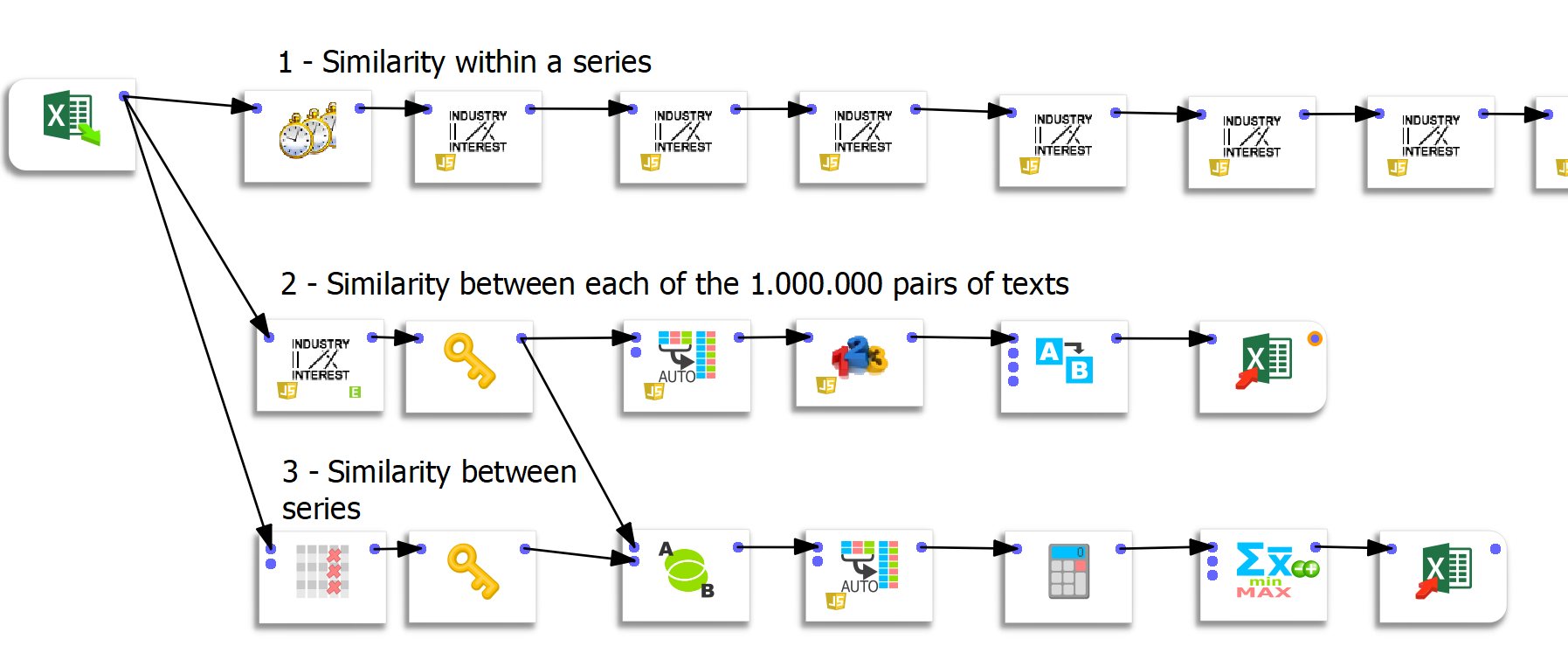
Flux 1 : calcul des similarités à l’intérieur d’une série
Ce premier flux est simple mais assez redondant. Les 2 premières boîtes permettent de calculer la similarité d’une itération par rapport à la précédente. Les boîtes suivantes (il y en a 50) calculent chacune la similarité entre l’itération n et l’itération 1.
Flux 2 : calcul des similarités entre chaque paire de texte
Pour ce flux je remercie Frank Vanden Berghen de m’avoir mis à disposition une fonctionnalité sur-mesure. L’enjeu était ici de calculer rapidement la similarité entre chaque paire de textes. Sachant qu’il y avait 50 itérations pour chacune des 20 questions, cela représentait 1000²=1.000.000 de possibilités. Je me permets de souligner ici l’extrême rapidité du process puisque le calcul d’un million de similarité ne prend que 44 secondes. Je me suis déjà étendu longuement sur les qualités d’Anatella et la vitesse d’exécution est clairement un avantage indéniable par rapport à d’autres ETL.
Dans cet exercice, la fonction « unflatten » d’Anatella s’est révélée très utile. Pour injecter les données dans Tableau il faut en effet « dépivoter » les données. Or, Tableau ne gère qu’un maximum de 700 colonnes. La matrice en faisant 1000, il devenait impossible de visualiser les données sans les préparer à l’extérieur de Tableau.
Flux 3 : calcul de la similarité entre séries
Le dernier flux génère une matrice entre séries. Il s’agit donc d’une matrice de 20×20. La fonction « group by » avant l’export vers Excel permet de faire la moyenne des valeurs de similarités.
Liste des sujets
Voici la liste des sujets qui ont été soumis à ChatGPT.
| Référence | Sujet |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |
![Illustration de notre publication "Changements de prix : certains retailers sont très actifs [Étude]"](/blog/app/uploads/pricing-120x90.jpg)




