¿Son únicas todas las respuestas generadas por ChatGPT? ¿O estamos sobrestimando su capacidad de producir textos distintos? Esa es la pregunta que me hice tras analizar 1000 textos generados por ChatGPT. Comparé el parecido entre 1.000.000 pares de textos generados por esta inteligencia artificial en respuesta a esta pregunta, y los resultados son sorprendentes y suponen un reto a la promesa del OpenAI. Descubre en este artículo los resultados de nuestro análisis en profundidad y lo que significa para el futuro de la generación de textos. Para mantenerte al día de mis análisis, te invito a considerar suscribirte a nuestras novedades semanales y a seguirme en LinkedIn.
ChatGPT: todos los resultados en 30 segundos
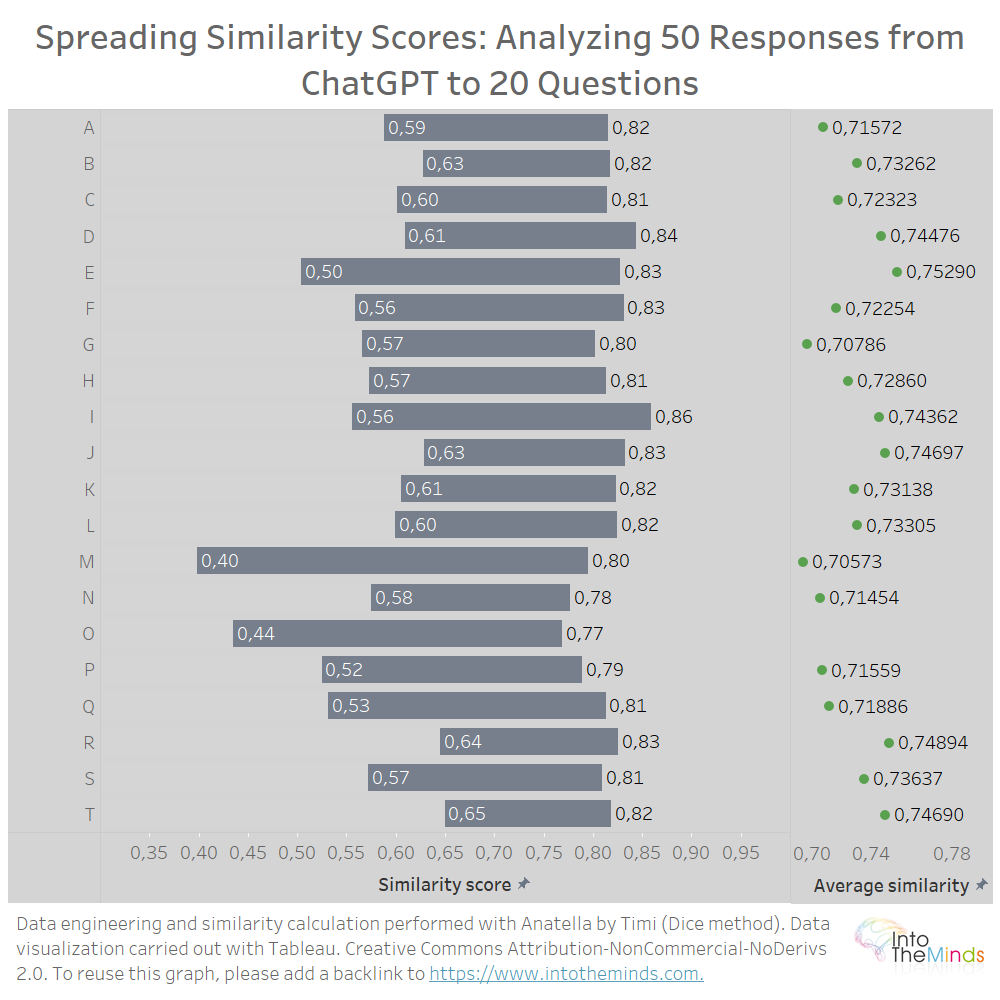
- ChatGPT produce respuestas bastante parecidas cuando le haces varias veces la misma pregunta. De media, el parecido varía entre el 70 y el 75%.
- Sea cual sea la pregunta, se producen «accidentes», generando respuestas bastante distintas de las otras. El parecido mínimo medido es del 40%.
- ChatGPT tiene una capacidad fascinante de producir respuestas parecidas a preguntas distintas. El parecido medio entre respuestas de ChatGPT a preguntas diferentes es del 60,93%.
- La longitud de las respuestas propuestas por ChatGPT para la misma pregunta varía ampliamente. Los 1000 textos producidos muestran variaciones máximas de +176% y -70%.
Resumen
- Metodología
- Descubre el nivel de consistencia de ChatGPT: el parecido de sus respuestas ante la misma pregunta
- La fascinante habilidad de ChatGPT de producir respuestas parecidas a preguntas diferentes
- Extra: ¿tienen siempre la misma longitud los textos producidos por ChatGPT?
- Apéndices
Metodología: leer primer para comprender los resultados consiguientes
El objetivo de esta investigación es estudiar lo distintas que son las respuestas ofrecidas por ChatGPT entre ellas. Se trata de un proyecto de investigación complejo que tuve que dividir en varios experimentos. Hoy te presento los resultados del primero; suscríbete a para seguir las novedades y no perderte el resto.
Generación del cuerpo de investigación
En este primer experimento, le pedí a ChatGPT que escribiese un artículo sobre un tema concreto (ver ejemplo a continuación). Se propuso un guion para estructurar las respuestas. Se definían veinte temáticas (ver Listado al final del artículo), y la solicitud que se le hacía a ChatGPT fue siempre la misma. Lo único que cambió fue la palabra clave entre comillas.

Quería imponer un plan concreto para cubrir las necesidades de los creadores de contenido que, cuando buscan posicionarse con palabras clave genéricas, adoptan una estructura que acostumbra a ser la misma. Para esta primera prueba, seguí un plan muy básico. En el segundo experimento se retira por lógica las indicaciones relacionadas con el plan del artículo para observar así cómo reacciona ChatGPT.
Esta estructura también me permitiría comparar artículos redactados sin la participación de una inteligencia artificial para este blog. Por ejemplo, aquí hay un artículo dedicado al marketing de activación.

Cada respuesta se generó 50 veces, una tras otra, sin interrupción. Cuando el proceso de regeneración se vio interrumpido por un problema técnico, el trabajo se inició partiendo de cero.
Aquí hay un ejemplo de respuesta obtiene a la pregunta anterior.

Preparación de los datos y procesamiento
El procesamiento y análisis de los datos se realizó con Anatella. La visualización de esos datos se hizo con Tableau.
Este proyecto no podría haberse realizado sin Anatella. Este ETL fue fundamental como mínimo por 2 aspectos:
- Para calcular parecidos de manera fácil y especialmente rápida (44 segundos para calcular el parecido entre 1 millones de parejas de textos)
- Para pivotar los datos y poder importarlos a Tableau (usando Tableau se pueden gestionar un máximo de 700 columnas, pero mi matriz de parecidos de mayor tamaño tenía 1000 líneas y 1000 columnas)
Para más información sobre preparación de datos, te remito al final de este artículo, donde explico los pasos necesarios para llevar a cabo dicha preparación.
Descubrir lo consistente que es ChatGPT: el parecido de sus respuestas ante la misma pregunta
Para empezar, el objetivo era comparar las respuestas a la misma pregunta. El parecido de los textos producidos se midió gracias al método Dice, del que ya he hablado aquí. Así que comparé las 50 iteraciones de cada una de las 20 preguntas.
Obtuvimos 20 matrices de 50×50 que puedes ver más abajo. El color ofrece una idea de la tasa de parecido; cuando más claro es, menor parecido. No quise llenar el gráfico con detalles innecesarios ya que pretendía ofrecer únicamente un resumen «visual» del conjunto.
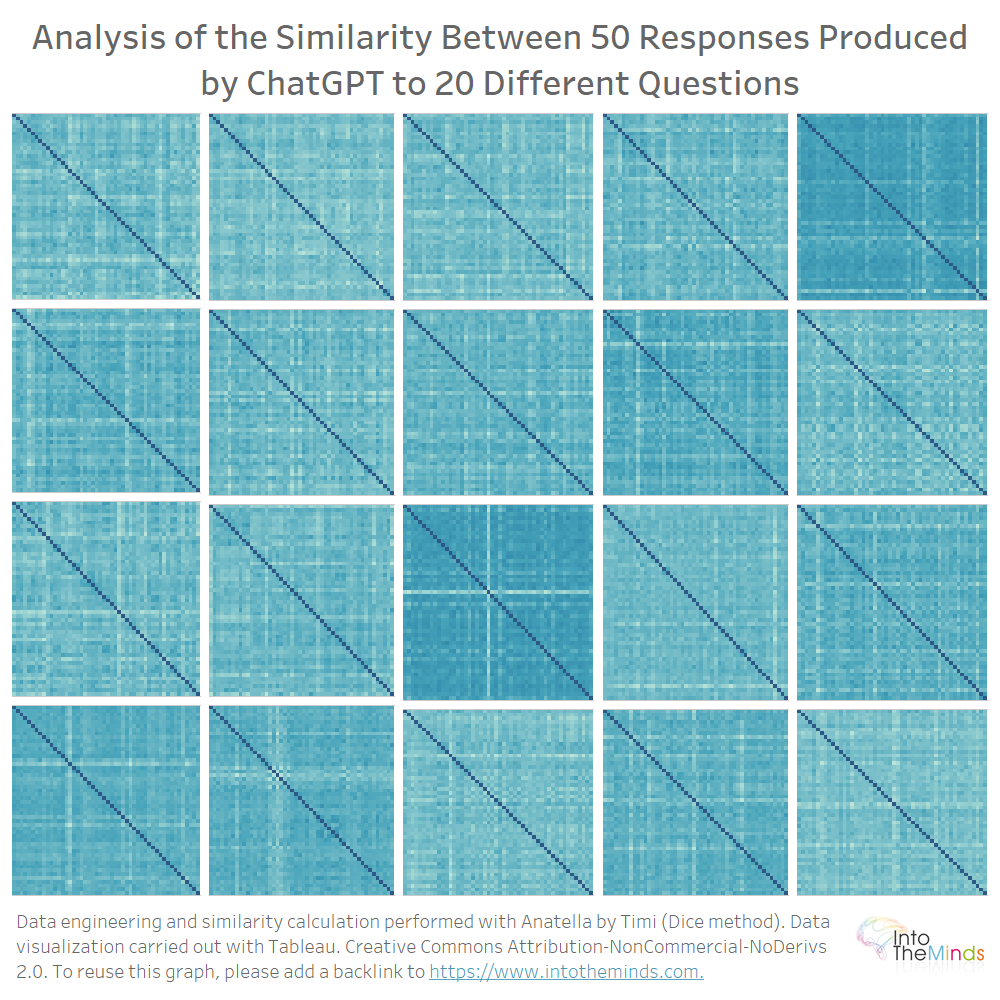
Así puedes ver a nivel visual que las diferencias son bastante pronunciadas. Para algunas series, las iteraciones son similares, mientras que para otras hay variaciones bastante marcadas.
De media, ChatGPT produce respuestas parecidas cuando le haces la misma pregunta varias veces. Concretamente, el coeficiente de parecido más pequeño es de 0,40 (pregunta M), y el más alto es de 0,86 (pregunta I). La dispersión de coeficientes de parecido se representa en el gráfico que hay a continuación. También se puede leer un parecido medio para cada serie. Como verás, todos los valores se sitúan entre 0,7 y 0,75.
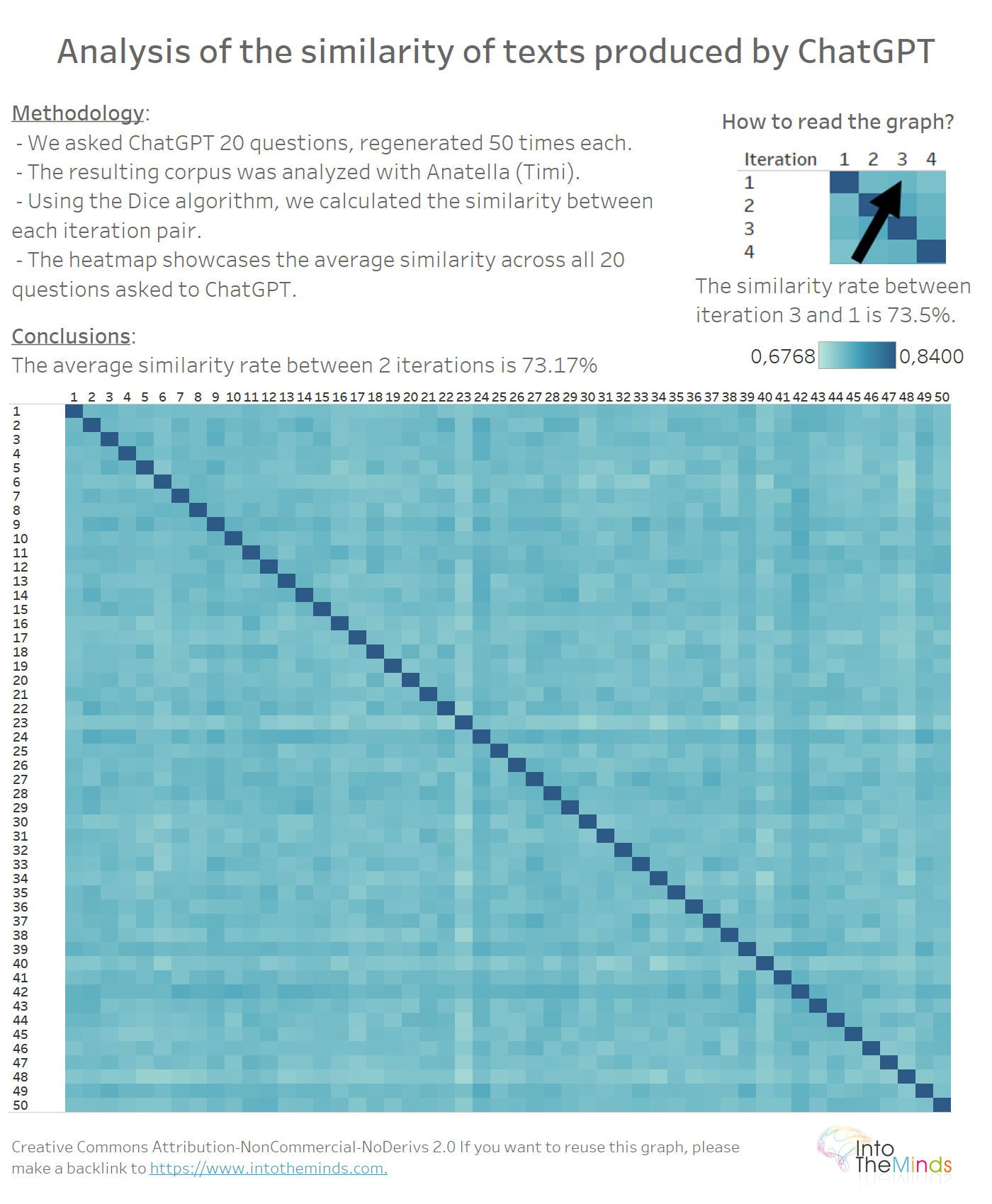
¿Podemos observar el «desvío» progresivo de las respuestas a medida que avanzan las iteraciones? O, en otras palabras, ¿produce ChatGPT, a medida que van pasando iteraciones, respuestas cada vez más y más alejadas del primer texto que ofrece?
Para dar respuesta a esta pregunta es suficiente con realizar un mapa de calor entre las 50 iteraciones de las 20 series. No existe un patrón concreto en los datos, lo que señala que cada respuesta de ChatGPT se regenera sin considerar las anteriores. La tasa media de parecido es de 73,17%.
Al aislar una serie y comparar cada iteración con la primera respuesta, podemos ver que el parecido no disminuye. En el gráfico siguiente aislé las series A, B, y C, y calculé el parecido de cada respuesta producida por ChatGPT en comparación con el primero de los textos. El gráfico empieza, lógicamente, en la iteración 2, puesto que el punto de comparación es el texto inicial (iteración 1).
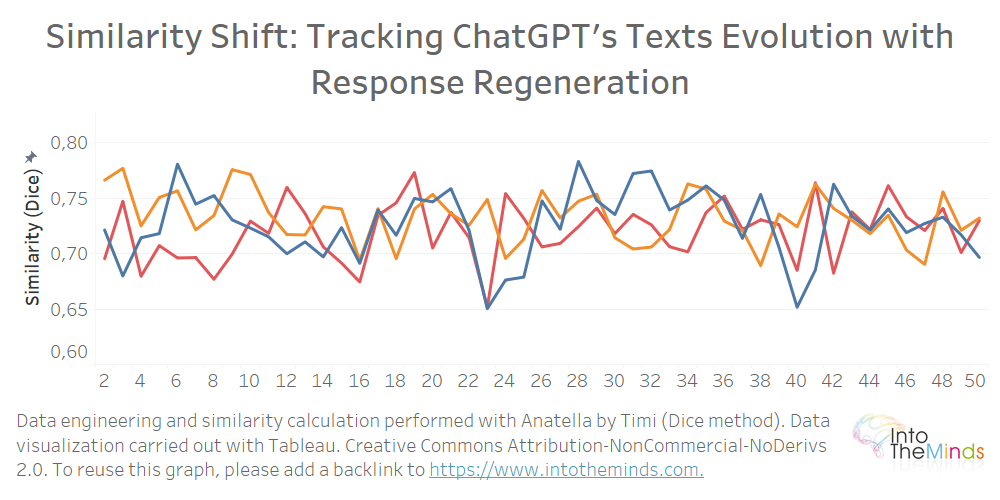
¿Qué podemos aprender de este análisis?
He aquí algunas lecciones que pueden aprenderse de este primer análisis:
- Cuando le haces la misma pregunta varias veces a ChatGPT, no esperes recibir respuestas básicamente distintas. Todas se estructuran de manera bastante parecida, algo normal puesto que las «mecánicas» algorítmicas que hay detrás de ChatGPT forman frases basándose en la siguiente palabra más probable. Así que, lógicamente, encontramos estructuras de frases parecidas entre una iteración y la siguiente.
- Esta investigación mide de manera objetiva la tasa de parecido entre respuestas. En el nivel mínimo, la tasa de parecido es del 40%, mientras que en el máximo es de 86%. De media, se encuentra en el 73%.
Dos textos producidos por ChatGPT sobre diferentes temas pueden ser parecidos hasta en un 50% o 2/3 partes.
La fascinante capacidad de ChatGPT de producir respuestas parecidas a preguntas distintas
Nuestra metodología se basó en preguntas idénticas en las que solo cambiaba la temática de la pregunta. Partiendo de ahí, se presenta la opción de comprar las respuestas a preguntas diferentes.
He aquí un ejemplo concreto. ¿Con qué parecido escribe ChatGPT textos sobre marketing de activación (temática A) respecto a los de astroturfing (temática B)? El ejercicio es parecido al realizado en la primera parte de este artículo; la diferencia yace en la agregación que tuvo que hacerse de los puntos relacionados a la misma pregunta (de la serie A a la T). Para llevar a cabo esta operación, la preparación de datos en Anatella demostró ser imprescindible ya que fue necesario comprar series entre sí. Me saltaré los aspectos técnicos e iré directo a hablar de los detalles. Para eso estás aquí, ¿verdad? ?
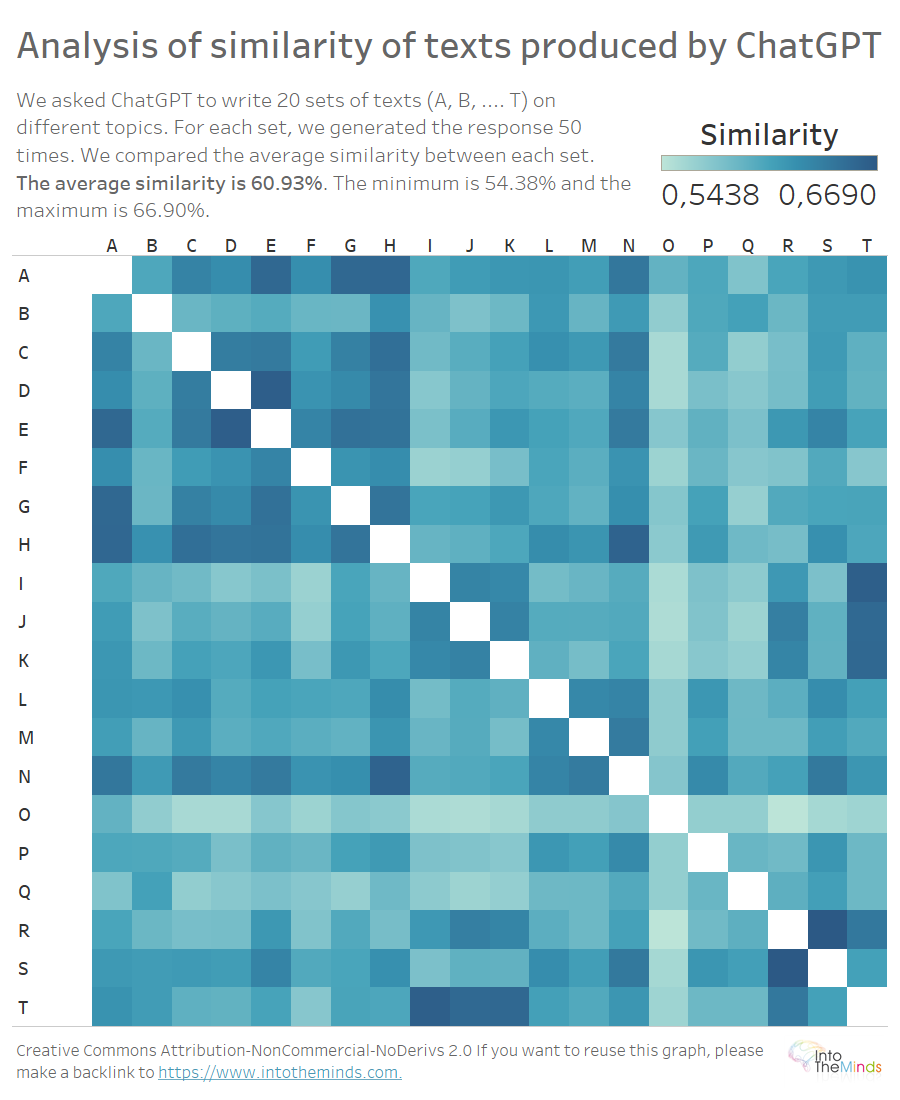
El mapa de calor que hay más arribe te permite visualizar el parecido entre los textos producidos para cada pregunta. Recuerda que cada letra (de la A a la T) representa una pregunta diferente. La temática difiere entre sets, pero la presentación es la misma (definición – ejemplos – conclusiones – referencias). Es razonable pensar que el parecido entre textos que tratan distintos temas sería bajo, pero n oes así. El parecido mínimo se encuentra en el 54,38%, y el máximo en el 66,90%. La media de parecido es del 60,93%, lo que significa que, en nuestro experimento, dos textos producidos por ChatGPT sobre temáticas diferentes pueden tener entre un 50% y 2/3 partes parecidas.
¿Qué podemos aprender de este análisis?
La lección principal de este análisis es que ChatGPT puede producir respuestas parecidas a preguntas diferentes. El siguiente experimento es una oportunidad para ampliar la comprensión del funcionamiento del algoritmo al no imponer un diseño y ver si ese diseño impuesto tiene algo que ver con los resultados.
Extra: ¿los textos que produce ChatGPT tienen siempre la misma longitud?
Para finalizar esta investigación, propongo explorar la variación en la longitud de los textos producidos por ChatGPT. Puesto que se le impone una planificación, los textos deberían tener todos una longitud equivalente. Pero, una vez más, no es así.
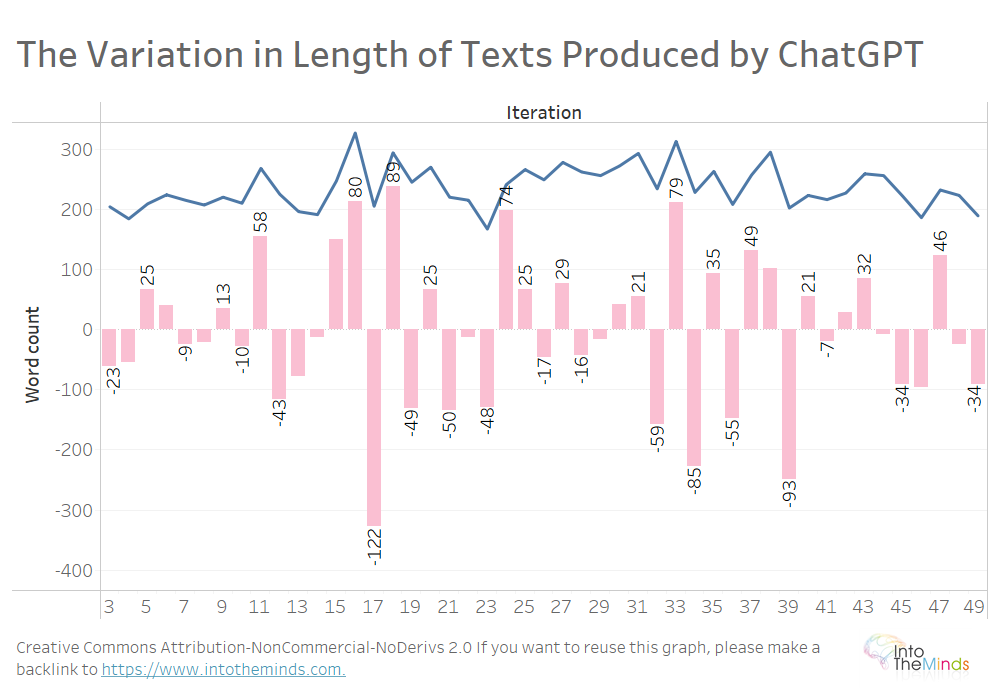
Empecemos echando un vistazo a la Serie A, las 50 iteraciones de textos producidas por ChatGPT sobre marketing de activación. El texto medio es de 237 palabras, pero entre una iteración y la siguiente, la longitud puede sufrir una variación dramática. Entre la iteración 16 y la 17, por ejemplo, el texto producido por ChatGPT desciende en 122 palabras, pasando de 328 a 206.
Se puede observar la misma variación en las 20 temáticas (ver gráfico a continuación). No he querido cargar demasiado la visualización, pero aquí tienes las variaciones máximas:
- +200 palabras entre la iteración 9 y la 10 para el tema I (“Net Promoter Score”)
- 232 palabras entre la iteración 22 y la 23 para el tema M (“Celebrity marketing”)
Teniendo en cuenta la totalidad de 1000 textos producidos, las variaciones máximas relativas fueron de:
- +176%
- -70%
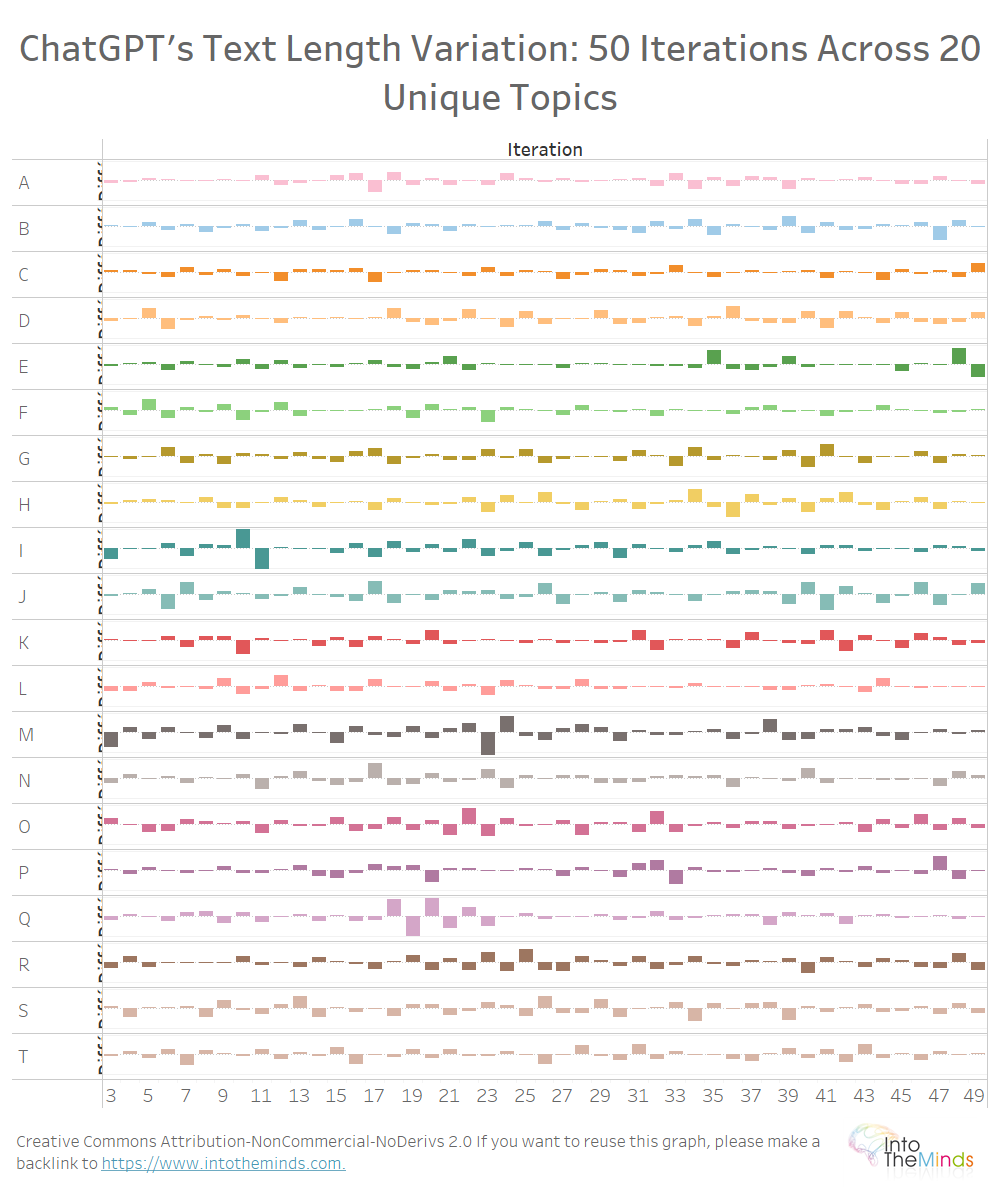
¿Qué podemos aprender de este análisis?
ChatGPT produce respuestas que varían ampliamente, al menos en cuanto a longitud. Los 1000 textos producidos muestran variaciones máximas de +176% y -70%. La longitud de los textos tiene, así, una alta fluctuación. En el siguiente experimento regeneraré todo este corpus imponiendo el número de palabras, lo que me permitirá investigar las instrucciones en relación con la dispersión de los resultados alrededor del objetivo.
Anexos
El procedimiento de la preparación de datos de Anatella
Para empezar, Anatella es un software ETL (Extraer – Transformar – Cargar) que te permite trabajar los datos antes de volver a inyectarlos en otro software. Es mi ETL preferido por varias razones:
Primero, porque es extremadamente rápido (comprueba un benchmark aquí).
Segundo, propone un rango de herramientas mucho más amplio que sus competidores, por lo que facilita hacer frente a problemas complejos.
El editor (Timi) es muy reactivo e incluso me ofrece una característica personalizada para dar una respuesta fácil a una necesidad específica (calcular el parecido entre un gran número de parejas de textos – ver flujo 2 a continuación)
Se crearon tres flujos de preparación de datos concretos en Anatella.
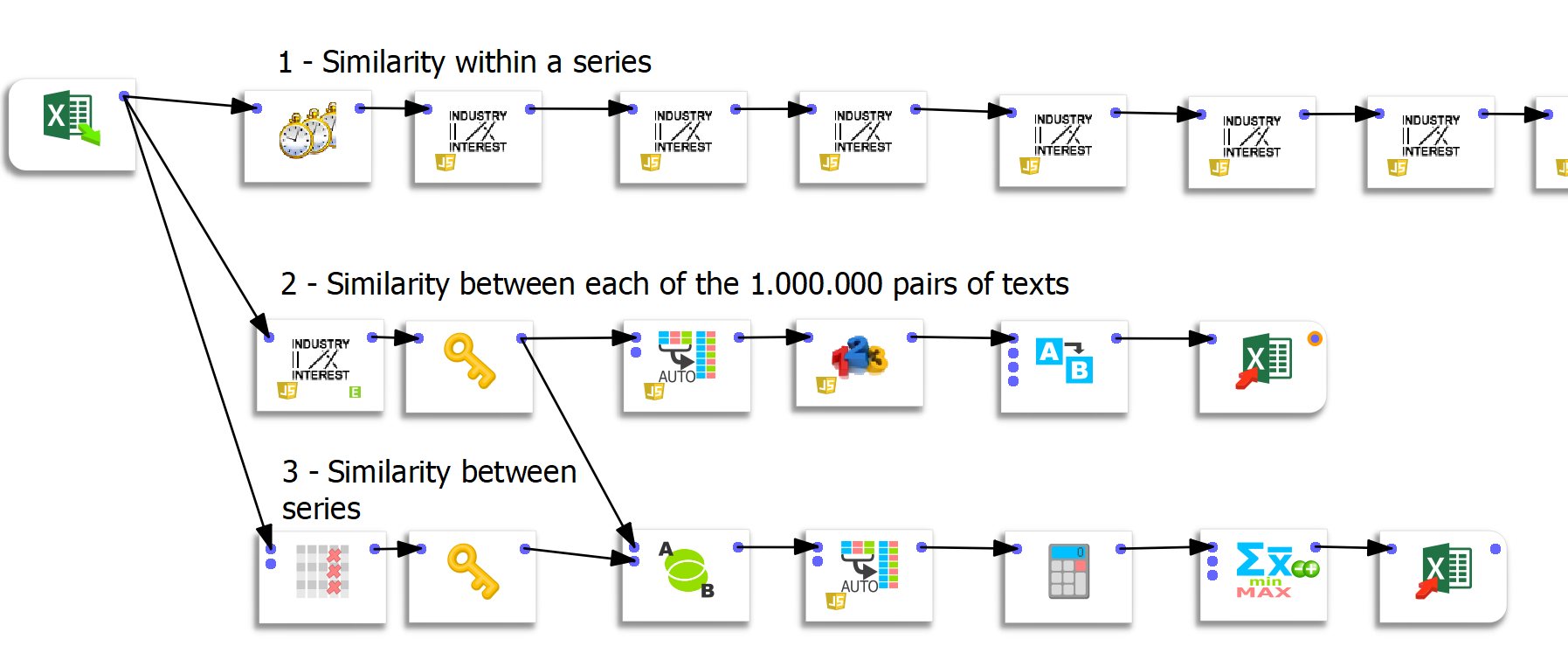
Flujo 1: computo de parecidos dentro de una serie
El primer flujo es sencillo pero bastante redundante. Las siguientes cajas (hay 50) computan el parecido entre la iteración n y la iteración 1. Las primeras 2 cajas nos permiten computar el parecido de una iteración respecto a la anterior.
Flujo 2: computación de parecidos entre cada pareja de textos
Para este flujo debo darle las gracias a Frank Vanden Berghen por ofrecerme una funcionalidad hecha a medida. Ya he hablado en profundidad de las cualidades de Anatella, y la velocidad de ejecución es una ventaja que tiene sobre los demás ETL. El reto aquí era calcular con rapidez el parecido entre cada pareja de textos. Sabiendo que había 50 iteraciones para cada una de las 20 preguntas, esto representaba 1000²=1.000.000 posibilidades. Deja que destaque de nuevo la velocidad extrema del proceso, puesto que el cálculo de un millón de parecidos solo llevó 44 segundos.
La función de «desaplanar» de Anatella demostró ser muy útil en este ejercicio. Al inyectar los datos en Tableau, estos deben ser «desaplanados», pero Tableau solo puede hacerlo hasta un máximo de 700 columnas. Puesto que la matriz tiene una longitud de 1000 columnas, visualizar los datos solo era posible preparándolos fuera de Tableau.
Flujo 3: cálculo del parecido entre las series
El último flujo genera una matriz entre series, por lo que es una matriz de 20×20. La función de «grupo por» antes de exportar a Excel nos permite obtener valores de parecido medios.
Lista de temas
Aquí tienes la lista de temas que presentamos a ChatGPT.
| Referencia | Temática |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |



![Ilustración de nuestra publicación "Digital en tiendas: los clientes quieren eficiencia [Encuesta]"](/blog/app/uploads/flagship-store-lacoste-paris-champs-elysees-14-120x90.jpg)