

Is elk antwoord dat door ChatGPT wordt gegenereerd echt uniek? Of overschatten we haar vermogen om verschillende teksten te produceren? Dit is de vraag die ik mezelf stelde na het analyseren van 1.000 door ChatGPT geproduceerde teksten. Om deze vraag te beantwoorden vergeleek ik de overeenkomst tussen 1.000.000 paren teksten die door deze kunstmatige intelligentie werden gegenereerd. De resultaten zijn verrassend en stellen de belofte van OpenAI ter discussie. Ontdek in dit artikel de resultaten van onze grondige analyse en wat dit betekent voor de toekomst van tekstgeneratie. Om op de hoogte te blijven van mijn analyses kunt u zich abonneren op de wekelijkse nieuwsbrief en mij volgen op LinkedIn.
ChatGPT: alle resultaten in 30 seconden
• ChatGPT geeft vrij gelijkaardige antwoorden wanneer u dezelfde vraag verschillende keren stelt. Gemiddeld varieert de overeenkomst tussen 70 en 75%.
• Wat de vraag ook is, er doen zich “ongelukjes” voor, die leiden tot antwoorden die heel anders zijn dan de andere. De minimaal gemeten overeenkomst is 40%.
• ChatGPT heeft een fascinerend vermogen om vergelijkbare antwoorden op verschillende vragen te produceren. De gemiddelde overeenkomst tussen de antwoorden van ChatGPT op verschillende vragen is 60,93%.
• De lengte van de door ChatGPT voorgestelde antwoorden voor dezelfde vraag loopt sterk uiteen. De 1000 geproduceerde teksten vertonen maximale variaties van +176% en -70%.
Inhoud
- Methode
- Ontdek hoe consistent ChatGPT is: gelijkenis van antwoorden op dezelfde vraag
- Het fascinerende vermogen van ChatGPT om vergelijkbare antwoorden op verschillende vragen te produceren…
- Bonus: zijn de door ChatGPT geproduceerde teksten altijd even lang?
- Bijlagen
Methode: lees vooraf om de resultaten achteraf te begrijpen
Het doel van dit onderzoek is te onderzoeken hoe sterk de antwoorden van ChatGPT werkelijk van elkaar verschillen. Dit is een complex onderzoeksproject, dat ik heb moeten opdelen in verschillende experimenten. Vandaag presenteer ik de resultaten van het eerste experiment. Schrijf je in op mijn nieuwsbrief zodat je de volgende niet mist.
Samenstelling van het bestudeerde corpus
In dit eerste experiment vroeg ik ChatGPT een artikel te schrijven over een specifiek onderwerp (zie een voorbeeld hieronder). Er werd een schema voorgesteld om de antwoorden te structureren. Er werden twintig onderwerpen (zie lijst aan het eind van dit artikel) werden gedefinieerd. Het verzoek aan ChatGPT was dus steeds hetzelfde. Alleen het sleutelwoord tussen aanhalingstekens wijzigde.

Ik wilde een bepaald plan opleggen om tegemoet te komen aan de behoeften van content-makers die, wanneer zij zich willen positioneren op generieke trefwoorden, een structuur aannemen die heel vaak hetzelfde is. Voor deze eerste poging volgde ik een heel eenvoudig plan. Het tweede experiment zal logischerwijs bestaan uit het verwijderen van de aanwijzingen betreffende het plan van het artikel om te observeren hoe chatGPT reageert.
Door deze structuur kan ik ook vergelijkingen maken met artikelen die zonder kunstmatige intelligentie voor dit blog zijn geschreven. Hier is een voorbeeld van een artikel gewijd aan marketingactivatie.

Elk antwoord werd 50 keer geregenereerd, het ene na het ander, zonder onderbreking. Toen het regeneratieproces werd onderbroken door een technisch probleem, moesten de werkzaamheden van voren af aan beginnen.
Hieronder volgt een voorbeeld van een antwoord op de hierboven gestelde vraag.

Voorbereiding en verwerking van gegevens
De gegevensverwerking en -analyse werden uitgevoerd met Anatella. De visualisatie van de gegevens gebeurde met Tableau.
Ik wil benadrukken dat dit project zonder Anatella niet tot stand had kunnen komen. Deze ETL was inderdaad cruciaal voor ten minste 2 aspecten:
- Het gemakkelijk en vooral snel berekenen van overeenkomsten (44 seconden om de overeenkomsten tussen 1 miljoen tekstparen te berekenen)
- Het opheffen (unpivot) van gegevens zodat ze in Tableau kunnen worden geïmporteerd (in Tableau kunnen maximaal 700 kolommen worden beheerd, en mijn grootste similariteitsmatrix telde 1000 rijen en 1000 kolommen)
Voor meer informatie over de data preparation verwijs ik u naar het einde van dit artikel, waar ik de verschillende stappen uitleg die nodig zijn om dit uit te voeren.
Ontdek hoe consistent ChatGPT is: gelijkenis van de antwoorden op dezelfde vraag
Eerst was het de bedoeling de antwoorden op dezelfde vraag te vergelijken. De gelijkenis van de geproduceerde teksten werd gemeten met behulp van de Dice-methode, die ik hier al beschreef. Daarom heb ik de 50 iteraties van elk van de 20 vragen vergeleken.
Dit geeft ons 20 matrices van 50×50, die u hieronder kunt zien. De kleur geeft een idee van de gelijkenis. Hoe lichter de kleur, hoe kleiner de gelijkenis. Ik wilde de grafiek niet volstoppen met onnodige details, omdat het mijn bedoeling was slechts een “grafisch” overzicht van het geheel te geven.
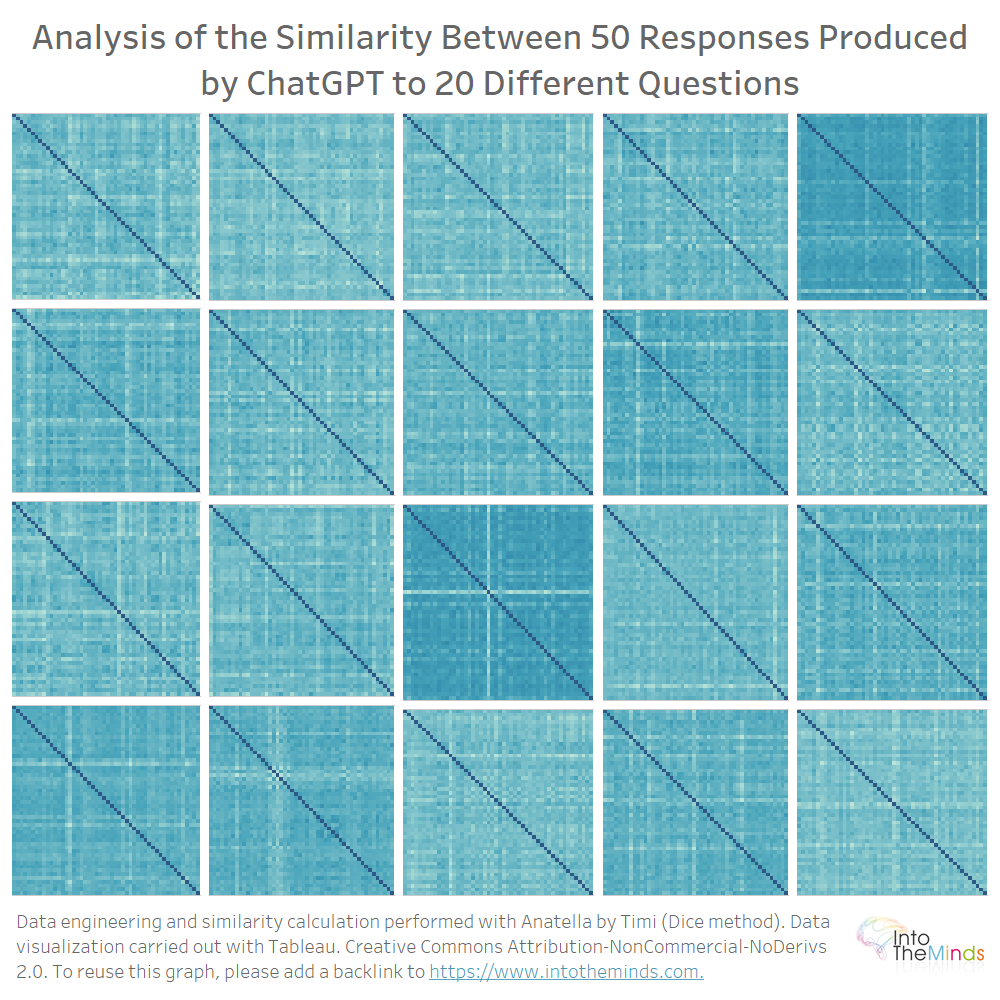
U ziet dus dat de verschillen vrij uitgesproken zijn. Voor sommige reeksen zijn alle iteraties gelijk; voor andere zijn er vrij sterke variaties.
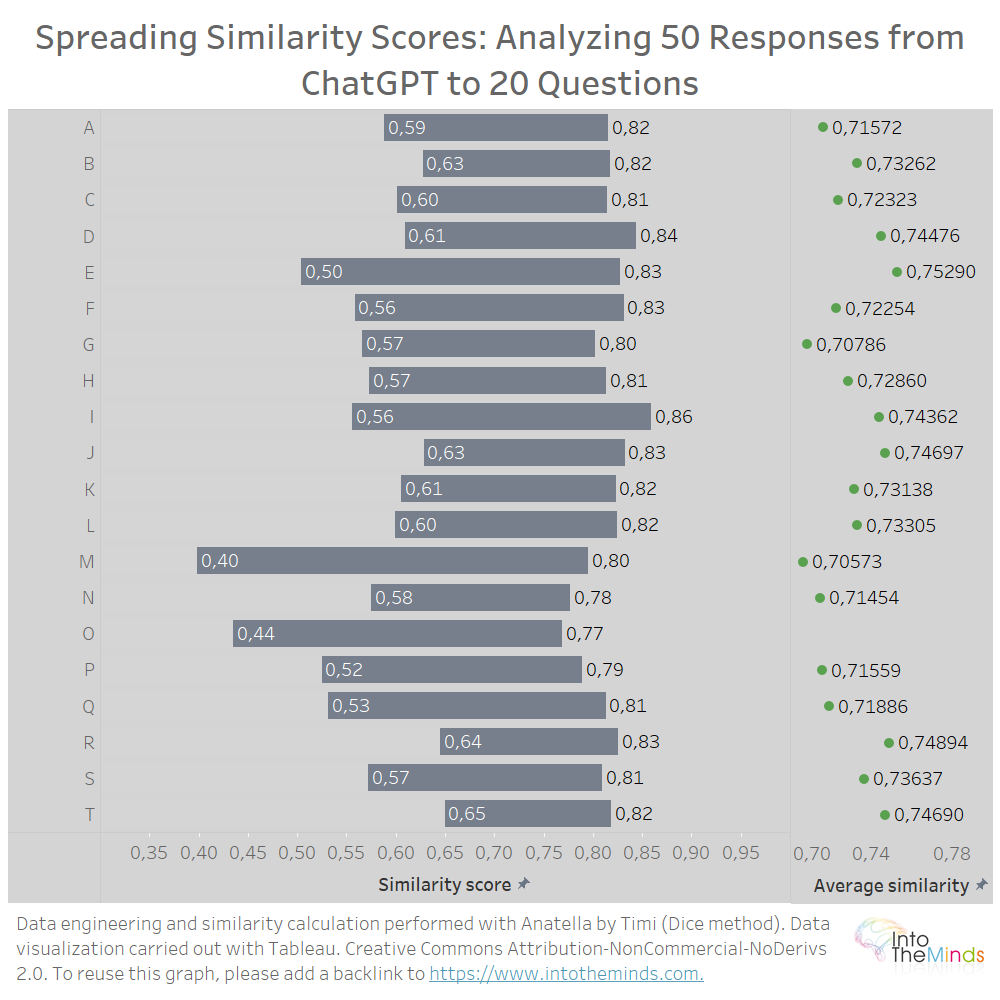
Concreet bedraagt de laagste gelijkeniscoëfficiënt 0,40 (vraag M) en de hoogste 0,86 (vraag I). De spreiding van de gelijkeniscoëfficiënten wordt weergegeven in onderstaande grafiek. U kunt ook de gemiddelde overeenkomst voor elk van de reeksen lezen. U zult zien dat alle waarden tussen 0,7 en 0,75 liggen. Gemiddeld geeft ChatGPT vrij gelijkaardige antwoorden wanneer u dezelfde vraag meerdere keren stelt.
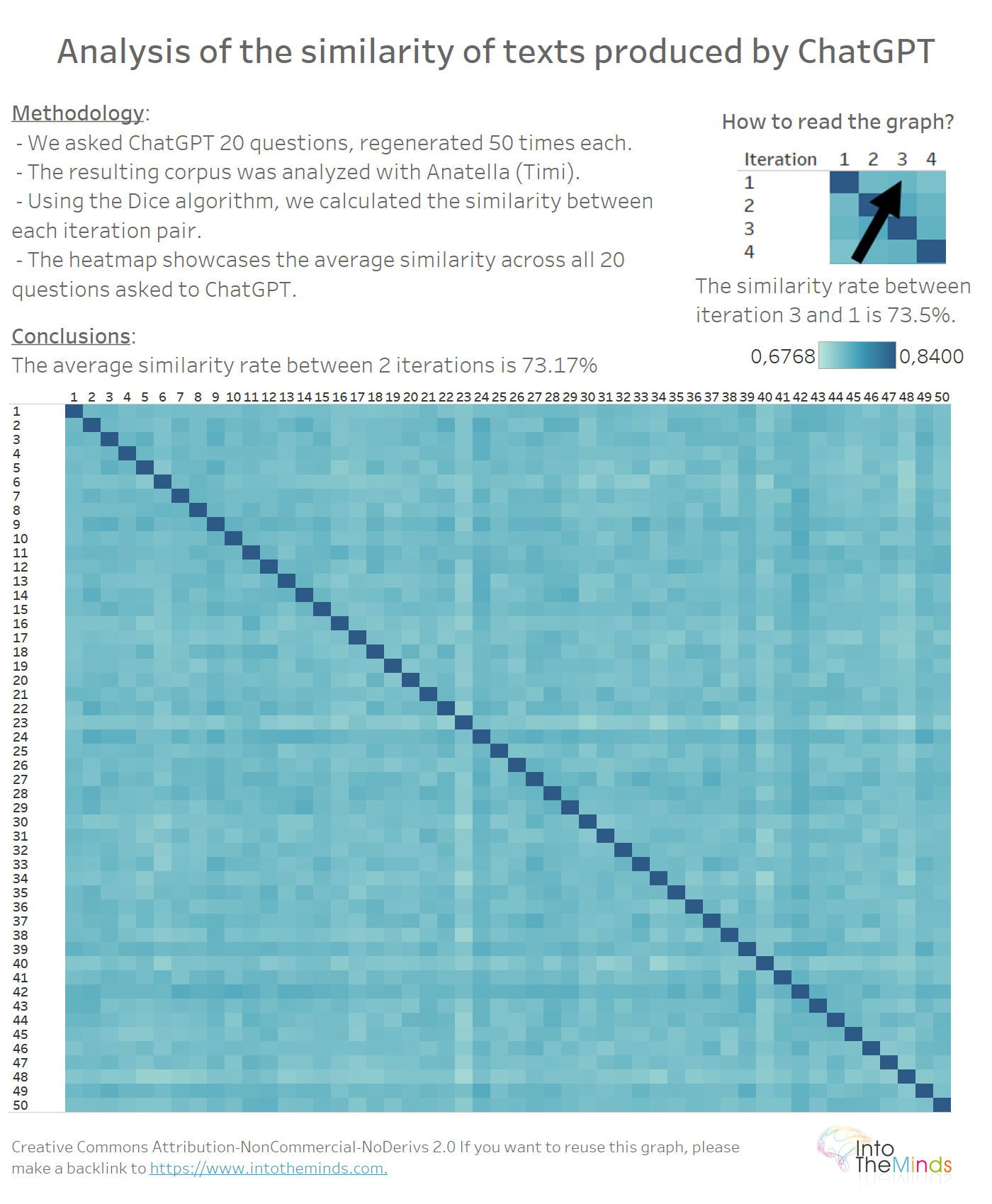
Kunnen we een progressieve “afwijking” van reacties waarnemen naarmate de iteraties toenemen? Met andere woorden, produceert ChatGPT antwoorden die steeds verder afwijken van de eerste iteratie?
Om deze vraag te beantwoorden volstaat het een heatmap te maken tussen de 50 iteraties van de 20 reeksen. Er is geen specifiek patroon in de gegevens. Dit betekent dat elk ChatGPT-antwoord opnieuw wordt gegenereerd, ongeacht het vorige. De gemiddelde gelijkenis bedraagt 73,17%.
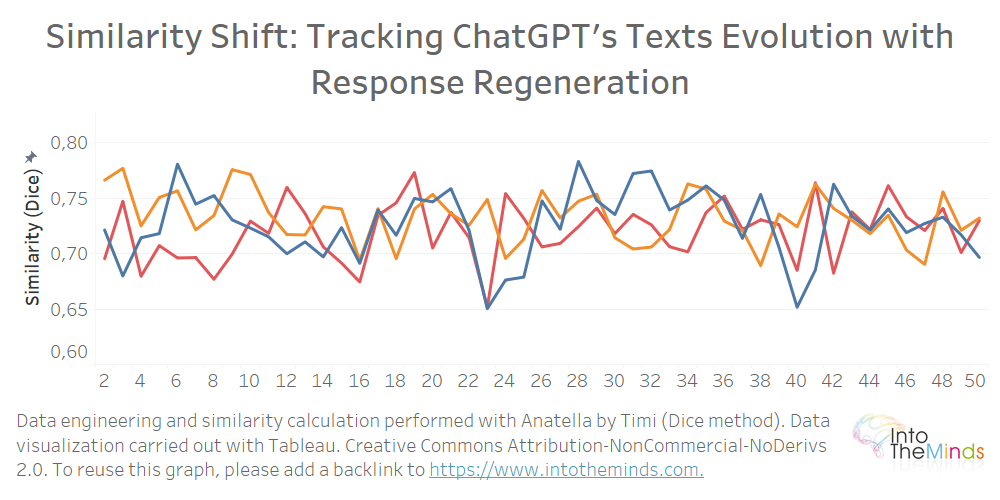
Door een reeks te isoleren en elke iteratie te vergelijken met het eerste antwoord, wordt duidelijk dat de gelijkenis niet afneemt. In onderstaande grafiek heb ik de reeksen A, B en C geïsoleerd en de overeenkomst van elk door ChatGPT geproduceerd antwoord met de eerst geproduceerde tekst berekend. De grafiek begint logischerwijs bij iteratie 2, aangezien het vergelijkingspunt de oorspronkelijke tekst is (iteratie 1).
Wat kunnen we van deze analyse leren?
Hier volgen enkele lessen die uit deze eerste analyse kunnen worden getrokken:
- Als u ChatGPT verschillende keren dezelfde vraag stelt, verwacht dan niet dat u fundamenteel verschillende antwoorden krijgt. Ze zijn structureel vrij vergelijkbaar. In principe is dit normaal, omdat de algoritmische “mechanica” achter chatGPT zinnen maakt op basis van het eerstvolgende meest waarschijnlijke woord. Dus logischerwijs vinden we soortgelijke zinswendingen van de ene iteratie naar de andere.
- Deze studie meet objectief de gelijkenis tussen de antwoorden. De gelijkenis is minimaal 40%. Het maximum is 86%. Gemiddeld is het 73%.
Twee door ChatGPT geproduceerde teksten over verschillende onderwerpen kunnen dus voor de helft of voor 2/3 op elkaar lijken.
Het fascinerende vermogen van ChatGPT om vergelijkbare antwoorden op verschillende vragen te produceren…
De door ons gebruikte methode is gebaseerd op identieke vragen waarbij alleen het onderwerp van het verzoek verandert. Daarom wordt het ook mogelijk de antwoorden op verschillende vragen te vergelijken.
Hier volgt een concreet voorbeeld. Hoe dicht liggen de teksten van ChatGPT over marketingactivatie (onderwerp A) bij die over Astroturfing (onderwerp B)? Het experiment is vergelijkbaar met dat in het eerste deel van dit artikel. Het verschil ligt in de samentelling die moest plaatsvinden van de punten die betrekking hebben op dezelfde vraag (reeksen A tot en met T). Voor het uitvoeren van deze operatie bleek de voorbereiding van de gegevens in Anatella onontbeerlijk, omdat het noodzakelijk was reeksen onderling te vergelijken. Ik zal de technische aspecten overslaan en met u praten over de resultaten. Daarvoor bent u toch hier? ?
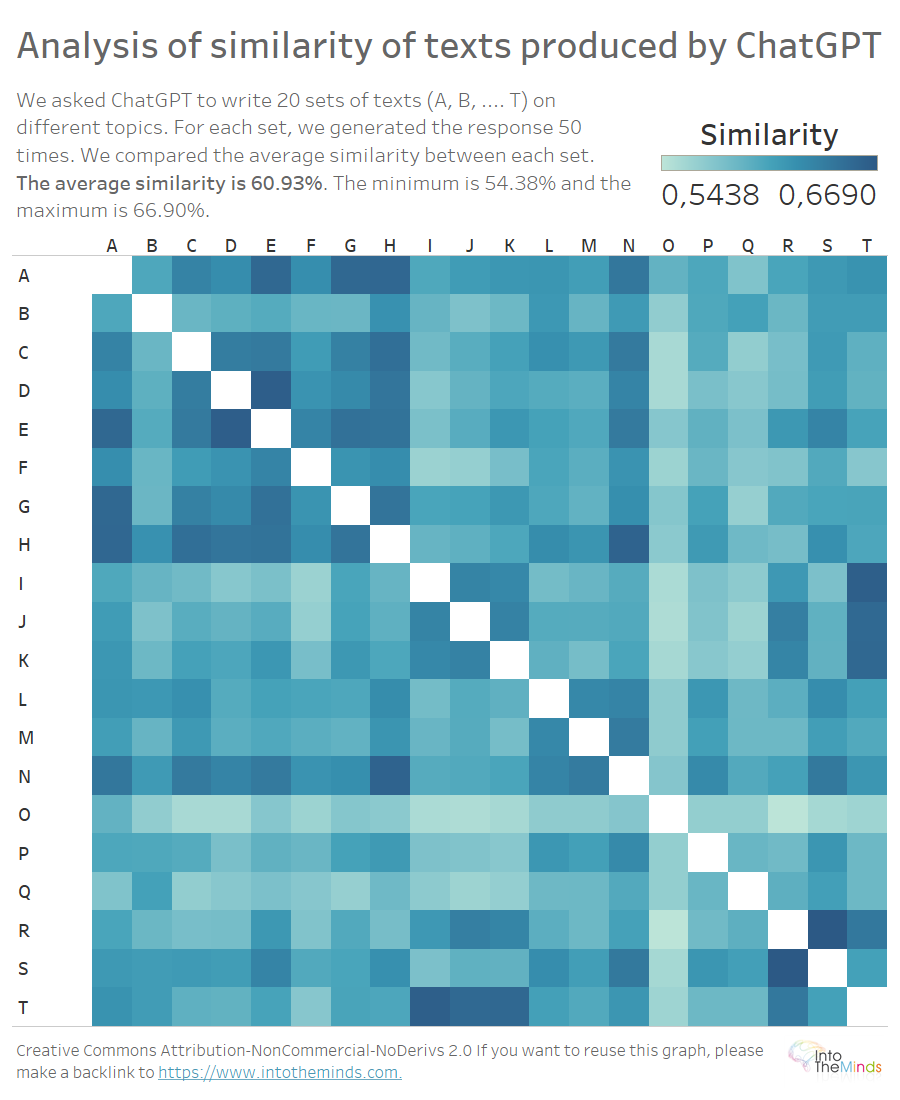
De heatmap hierboven toont de overeenkomst tussen de teksten die voor elke vraag zijn geproduceerd. Elke letter (A tot T) staat voor een andere vraag. Het onderwerp verschilt van reeks tot reeks; alleen het plan is hetzelfde (definitie – voorbeelden – conclusies – referenties). Het is dus redelijk te verwachten dat de gelijkenis tussen teksten over verschillende onderwerpen gering is. Maar dat is niet zo. De minimale overeenkomst is 54,38% en de maximale overeenkomst 66,90%. De gemiddelde overeenkomst is 60,93%. Dit betekent dat in ons experiment twee door ChatGPT geproduceerde teksten over verschillende onderwerpen in feite voor de helft tot 2/3 op elkaar kunnen lijken.
Wat kunnen we van deze analyse leren?
De belangrijkste les van deze analyse is dat ChatGPT verrassend vergelijkbare antwoorden op verschillende vragen kan opleveren. Ongetwijfeld heeft het opgelegde ontwerp er iets mee te maken. Het volgende experiment zal ons de kans bieden om meer inzicht in de werking van het algoritme te krijgen door geen plan meer op te leggen.
Bonus: zijn de door ChatGPT geproduceerde teksten altijd even lang?
Om dit eerste onderzoek af te ronden, stel ik voor de variatie in lengte van de door ChatGPT geproduceerde teksten te onderzoeken. Aangezien aan ChatGPT een plan wordt opgelegd, zouden de teksten logischerwijs allemaal ongeveer even lang moeten zijn. Maar ook dit is niet het geval.
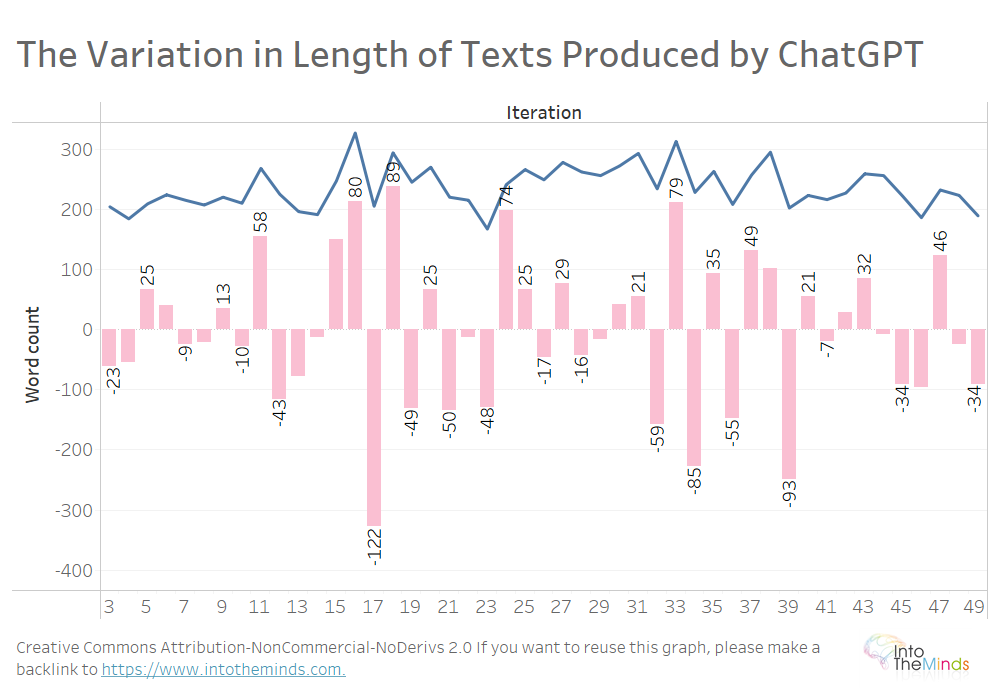
Laten we beginnen met de A-reeks, de 50 iteraties van door ChatGPT geproduceerde teksten over het onderwerp marketingactivatie. De teksten zijn gemiddeld 237 woorden lang. Maar tussen de ene iteratie en de volgende kan de lengte sterk variëren. Tussen iteratie 16 en iteratie 17 verliest de door ChatGPT geproduceerde tekst 122 woorden, van 328 naar 206 woorden.
Bij alle 20 de onderzocht onderwerpen kunnen dezelfde variaties worden waargenomen (onderstaande grafiek). Ik wilde de visualisatie niet te zwaar maken, maar hier zijn de maximale variaties:
- +200 woorden tussen iteraties 9 en 10 voor onderwerp I (“Net Promoter Score”)
- -232 woorden tussen iteraties 22 en 23 voor onderwerp M (“Celebrity marketing”)
Van de 1000 geproduceerde teksten bedroegen de maximale relatieve variaties:
- +176%
- -70%
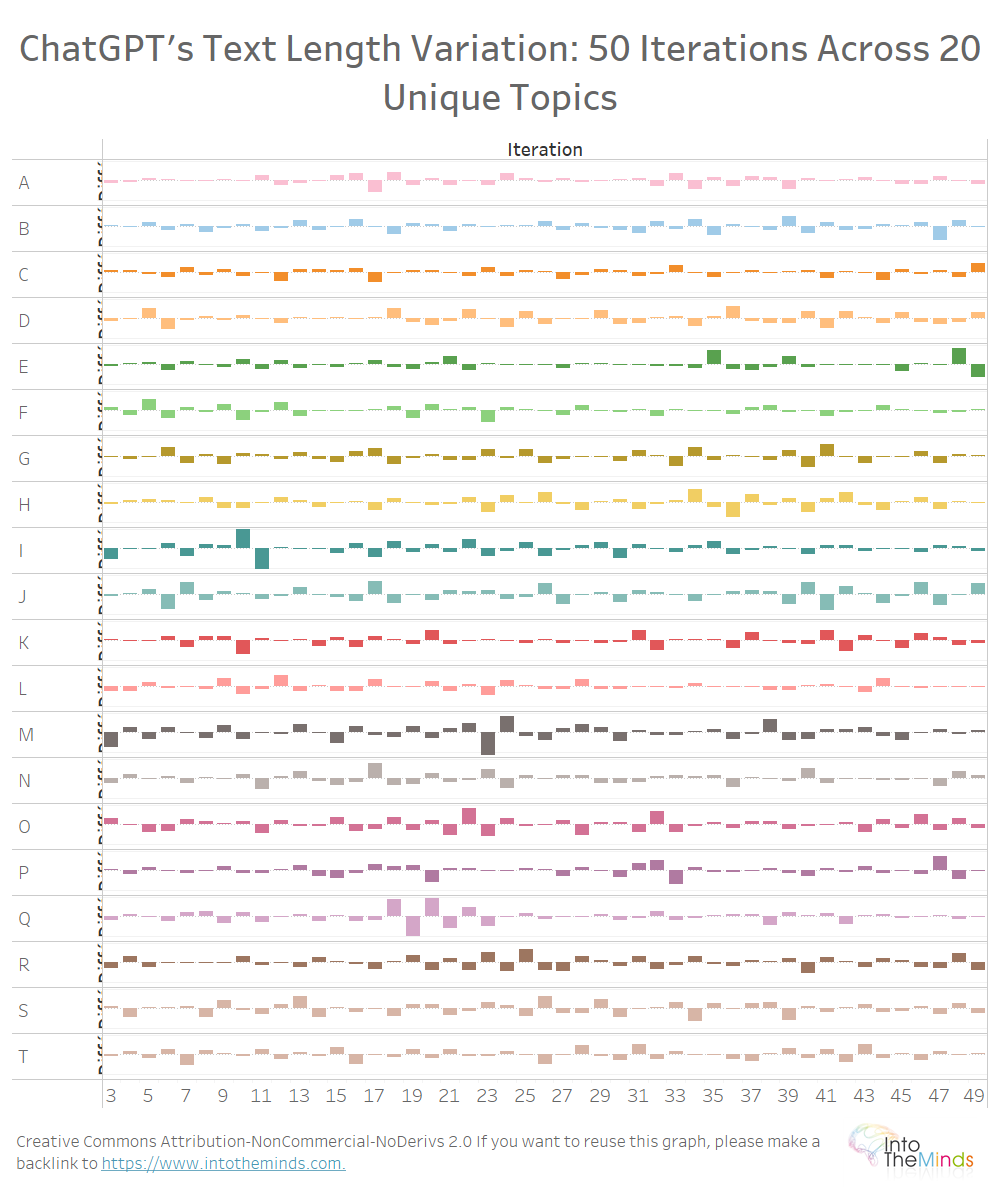
Wat te onthouden uit deze analyse?
ChatGPT produceert antwoorden die redelijk uiteenlopend zijn, althans wat de tekstlengte betreft. De 1000 geproduceerde teksten vertonen maximale variaties van +176% en -70%. De lengte van de teksten schommelt dus sterk.
In een volgend experiment ga ik het hele corpus regenereren door een woordentelling op te leggen. Zo kan ik de naleving van de instructie en de spreiding van de resultaten rond het doel bestuderen.
Bijlagen
Data preparation in Anatella
Allereerst wil ik u eraan herinneren dat Anatella een ETL-software (Extract – Transform – Load) is waarmee u gegevens kunt bewerken voordat u ze opnieuw in een andere software invoer. Het is mijn favoriete ETL om verschillende redenen:
- ten eerste omdat het supersnel is (bekijk deze benchmark).
- ten tweede omdat het standaard een veel breder scala aan gereedschappen biedt dan zijn concurrenten. Dit betekent dat u complexe problemen met gemak kunt aanpakken.
- de uitgeverij (Timi) is zeer reactief en heeft me zelfs een functionaliteit op maat geleverd om gemakkelijk aan een specifieke behoefte te voldoen (berekening van de gelijkenis tussen een groot aantal tekstparen (zie stroom 2 hieronder)
In Anatella werden drie afzonderlijke werkstromen voor gegevensvoorbereiding gecreëerd.
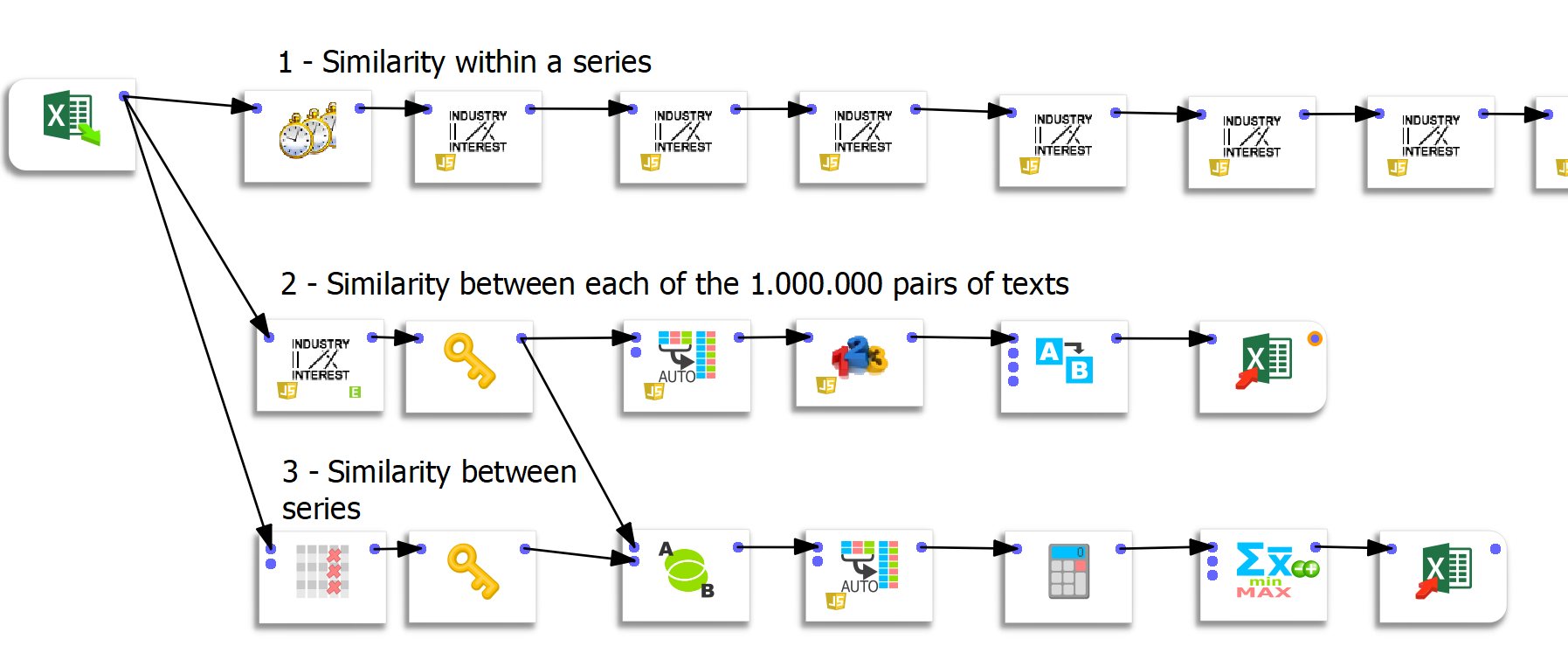
Stroom 1: berekening van overeenkomsten binnen een reeks
Deze eerste stroom is eenvoudig, maar nogal overbodig. De eerste 2 vakjes berekenen de gelijkenis van een iteratie met de vorige. De volgende vakjes (er zijn er 50) berekenen elk de overeenkomst tussen iteratie n en iteratie 1.
Stroom 2: berekening van de overeenkomsten tussen elk tekstpaar
Voor deze stroom wil ik Frank Vanden Berghen bedanken voor het leveren van een functionaliteit op maat. De uitdaging was hier om snel de overeenkomst tussen elk paar teksten te berekenen. Wetende dat er 50 iteraties waren voor elk van de 20 vragen, vertegenwoordigde dit 1000²=1.000.000 mogelijkheden. Ik wil hier de extreme snelheid van het proces benadrukken, aangezien de berekening van een miljoen overeenkomsten slechts 44 seconden in beslag neemt. Ik heb al uitvoerig gesproken over de kwaliteiten van Anatella en de snelheid van uitvoering is duidelijk een voordeel ten opzichte van andere ETL’s.
Bij deze oefening bleek de functie “unflatten” van Anatella zeer nuttig. Om de gegevens in Tableau te kunnen invoeren, moeten ze worden “opgeheven”. Tableau beheert immers slechts maximaal 700 kolommen. Met een matrix van 1000 kolommen werd het onmogelijk om de gegevens te visualiseren zonder ze buiten Tableau voor te bereiden.
Stroom 3: berekening van de gelijkenis tussen reeksen
De laatste stroom genereert een matrix tussen reeksen. Het is dus een matrix van 20×20. Met de functie “group by” vóór het exporteren naar Excel kan het gemiddelde worden gemaakt van de gelijkeniswaarden.
Lijst van onderwerpen
Hier is de lijst met onderwerpen die zijn ingediend bij ChatGPT.
| Referentie | Onderwerp |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |


![Illustratie van onze post "Generatie Z en werk: de perceptie van werkgevers [Studie]"](/blog/app/uploads/generation_y_youngsters-120x90.jpg)


