

Ist jede von ChatGPT generierte Antwort einzigartig? Oder überschätzen wir seine Fähigkeit, unterschiedliche Texte zu produzieren? Diese Frage habe ich mir gestellt, nachdem ich 1000 von ChatGPT erzeugte Texte analysiert hatte. Um diese Frage zu beantworten, habe ich die Ähnlichkeit zwischen 1.000.000 von dieser künstlichen Intelligenz erzeugten Textpaaren verglichen. Die Ergebnisse sind überraschend und stellen das Versprechen von OpenAI in Frage. Erfahren Sie in diesem Artikel die Ergebnisse unserer eingehenden Analyse und was sie für die Zukunft der Texterstellung bedeuten. Wenn Sie über meine Analysen auf dem Laufenden bleiben möchten, sollten Sie den wöchentlichen Newsletter abonnieren und mir auf LinkedIn folgen.
ChatGPT: alle Ergebnisse in 30 Sekunden
- ChatGPT liefert recht ähnliche Antworten, wenn Sie ihm mehrmals die gleiche Frage stellen. Im Durchschnitt schwankt die Ähnlichkeit zwischen 70 und 75%.
- Unabhängig von der Frage gibt es aber auch “Unfälle”, bei denen die Antworten ganz anders ausfallen als bei anderen. Die gemessene Mindestähnlichkeit liegt bei 40%.
- ChatGPT hat die faszinierende Fähigkeit, ähnliche Antworten auf unterschiedliche Fragen zu geben. Die durchschnittliche Ähnlichkeit zwischen ChatGPT-Antworten auf verschiedene Fragen beträgt 60,93%.
- Die Länge der von ChatGPT vorgeschlagenen Antworten auf ein und dieselbe Frage variiert stark. Die 1000 produzierten Texte weisen maximale Abweichungen von +176% und -70% auf.
Zusammenfassung
- Methodik
- Entdecken Sie, wie konsistent ChatGPT ist: die Ähnlichkeit der Antworten auf dieselbe Frage
- Die faszinierende Fähigkeit von ChatGPT, ähnliche Antworten auf verschiedene Fragen zu produzieren
- Bonus: sind die von ChatGPT produzierten Texte immer gleich lang?
- Anhänge
Methodik: Lesen Sie diesen Abschnitt zuerst, um die folgenden Ergebnisse zu verstehen
Das Ziel dieser Forschung ist es, zu untersuchen, wie sehr sich die von ChatGPT gegebenen Antworten voneinander unterscheiden. Dies ist ein komplexes Forschungsprojekt, das ich in mehrere Experimente unterteilen musste. Ich stelle Ihnen heute die Ergebnisse des ersten vor. Abonnieren Sie meinen Newsletter, damit Sie die nächsten Experimente nicht verpassen.
Erstellung des untersuchten Korpus
In diesem ersten Experiment bat ich ChatGPT, einen Artikel zu einem bestimmten Thema zu schreiben (siehe Beispiel unten). Zur Strukturierung der Antworten wurde eine Gliederung vorgeschlagen. Zwanzig Themen (siehe Liste am Ende dieses Artikels) wurden festgelegt. Die an ChatGPT gerichtete Anfrage war immer dieselbe. Nur das Schlüsselwort zwischen den Anführungszeichen änderte sich.

Ich möchte einen bestimmten Plan durchsetzen, um den Bedürfnissen der Ersteller von Inhalten gerecht zu werden, die, wenn sie versuchen, sich zu generischen Schlüsselwörtern zu positionieren, eine Struktur verwenden, die sehr oft gleich ist. Für diesen ersten Test folgte ich einem sehr einfachen Plan. Beim zweiten Experiment werde ich logischerweise die Hinweise auf den Plan des Artikels entfernen, um zu beobachten, wie ChatGPT reagiert.
Diese Struktur wird es mir auch ermöglichen, Artikel zu vergleichen, die ohne künstliche Intelligenz für diesen Blog geschrieben wurden. Hier ist zum Beispiel der Artikel zum Thema Aktivierungs-Marketing.

Jede Antwort wurde 50 Mal regeneriert, eine nach der anderen, ohne Unterbrechung. Wenn der Regenerierungsprozess durch ein technisches Problem unterbrochen wurde, musste die Arbeit von vorne begonnen werden.
Hier sehen Sie ein Beispiel für die Antwort auf die oben gestellte Frage.

Datenaufbereitung und -verarbeitung
Die Datenverarbeitung und -analyse wurde mit Anatella durchgeführt und die Visualisierung der Daten wurde mit Tableau durchgeführt.
Dieses Projekt hätte ohne Anatella nicht durchgeführt werden können. Diese ETL-Lösung war in der Tat für mindestens 2 Aspekte entscheidend:
- die einfache und besonders schnelle Berechnung von Ähnlichkeiten (44 Sekunden für die Berechnung der Ähnlichkeit zwischen 1 Million Textpaaren)
- DE Pivotierung der Daten, damit sie in Tableau importiert werden können (mit Tableau können maximal 700 Spalten verwaltet werden, aber meine größte Ähnlichkeitsmatrix hatte 1000 Zeilen und 1000 Spalten)
Für weitere Informationen zur Datenvorbereitung verweise ich Sie auf das Ende dieses Artikels, wo ich die erforderlichen Schritte für die Datenvorbereitung erläutere.
Entdecken Sie, wie konsistent ChatGPT ist: die Ähnlichkeit der Antworten auf dieselbe Frage
Zunächst ging es darum, die Antworten auf dieselbe Frage zu vergleichen. Die Ähnlichkeit der erstellten Texte wurde mit Hilfe der Dice-Methode gemessen, die ich hier bereits erläutert habe. Ich verglich also die 50 Wiederholungen von jeder der 20 Fragen.
Wir erhalten 20 Matrizen von 50×50, die Sie unten sehen können. Die Farbe gibt einen Eindruck von der Ähnlichkeitsrate. Je heller sie ist, desto geringer ist die Ähnlichkeit. Ich wollte das Diagramm nicht mit unnötigen Details überladen, da ich nur einen “grafischen” Überblick über das Ganze geben wollte.
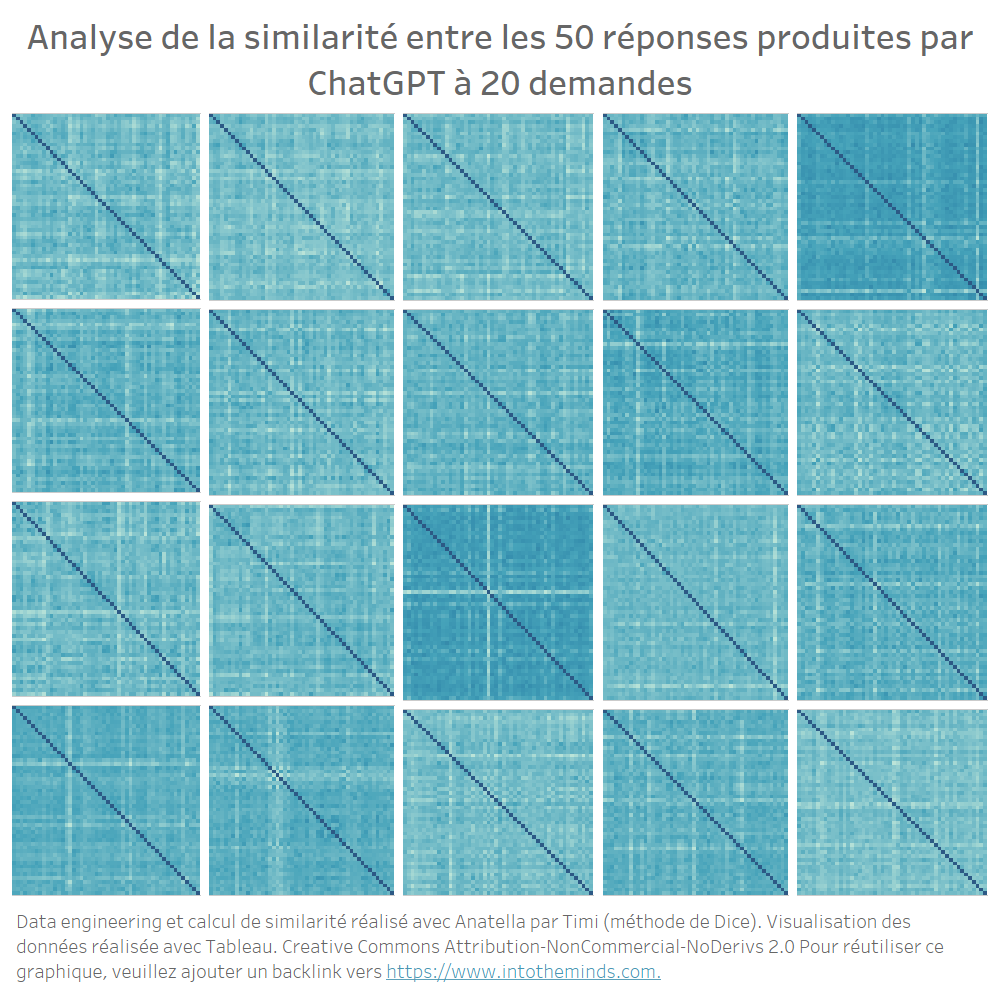
Sie können also visuell sehen, dass die Unterschiede recht ausgeprägt sind. Bei einigen Serien sind alle Iterationen ähnlich, bei anderen gibt es recht starke Abweichungen.
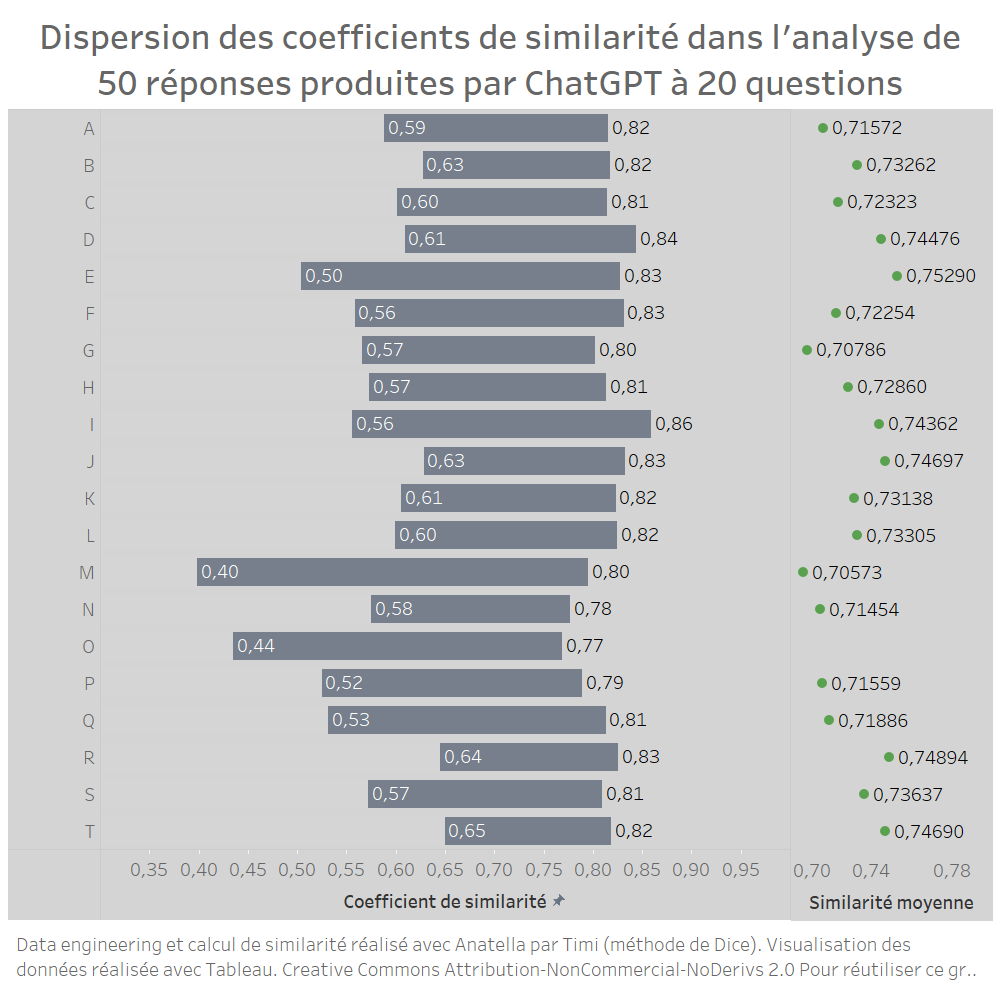
Im Durchschnitt liefert ChatGPT ähnliche Antworten, wenn Sie ihm die gleiche Frage mehrmals stellen. Konkret liegt der niedrigste Ähnlichkeitskoeffizient bei 0,40 (Frage M) und der höchste bei 0,86 (Frage I). Die Streuung der Ähnlichkeitskoeffizienten ist in der unten stehenden Grafik dargestellt. Sie können auch die durchschnittliche Ähnlichkeit für jede Serie ablesen. Sie werden feststellen, dass alle Werte zwischen 0,7 und 0,75 liegen.
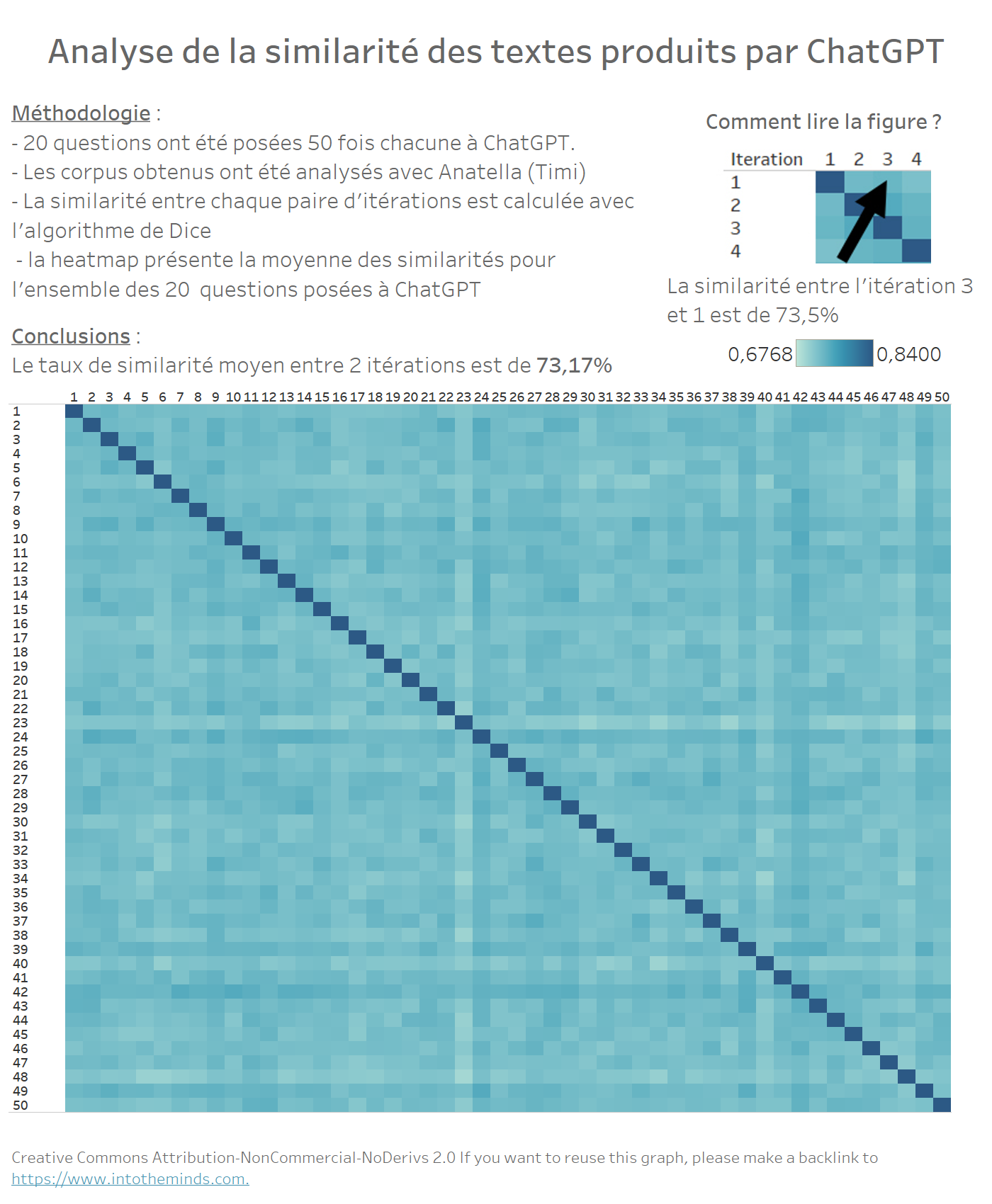
 Können wir im Laufe der Iterationen einen progressiven “Drift” der Antworten beobachten? Mit anderen Worten: Erzeugt ChatGPT im Laufe der Iterationen Antworten, die immer weiter von der ersten Iteration entfernt sind?
Können wir im Laufe der Iterationen einen progressiven “Drift” der Antworten beobachten? Mit anderen Worten: Erzeugt ChatGPT im Laufe der Iterationen Antworten, die immer weiter von der ersten Iteration entfernt sind?
Um diese Frage zu beantworten, genügt es, eine Heatmap zwischen den 50 Iterationen der 20 Serien zu erstellen. Es gibt kein besonderes Muster in den Daten. Dies deutet darauf hin, dass jede ChatGPT-Antwort neu generiert wird, ohne die vorherige zu berücksichtigen. Die durchschnittliche Ähnlichkeitsrate beträgt 73,17%.
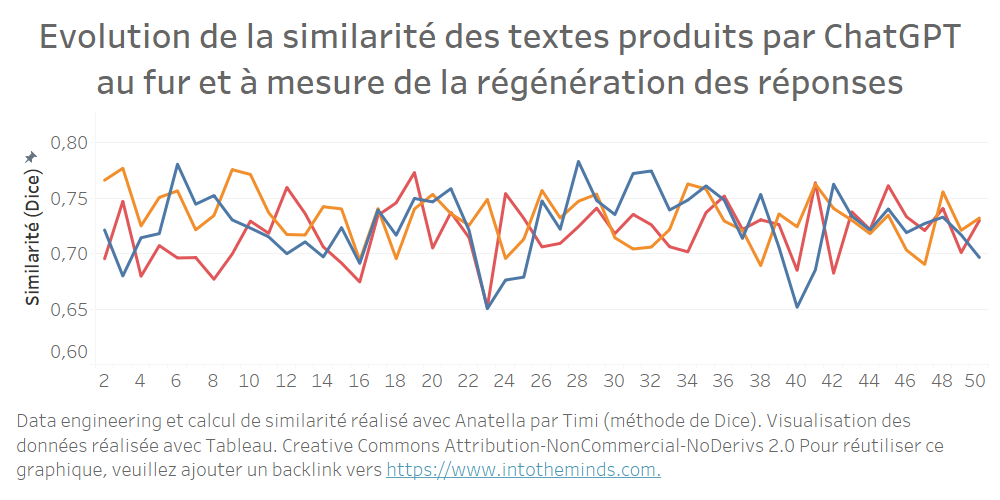
 Wenn wir eine Serie isolieren und jede Iteration mit der ersten Antwort vergleichen, können wir sehen, dass die Ähnlichkeit nicht abnimmt. In der untenstehenden Grafik habe ich die Serien A, B und C isoliert und die Ähnlichkeit jeder von ChatGPT erzeugten Antwort im Vergleich zum ersten erzeugten Text berechnet. Die Grafik beginnt logischerweise bei Iteration 2, da der Vergleichspunkt der Ausgangstext ist (Iteration 1).
Wenn wir eine Serie isolieren und jede Iteration mit der ersten Antwort vergleichen, können wir sehen, dass die Ähnlichkeit nicht abnimmt. In der untenstehenden Grafik habe ich die Serien A, B und C isoliert und die Ähnlichkeit jeder von ChatGPT erzeugten Antwort im Vergleich zum ersten erzeugten Text berechnet. Die Grafik beginnt logischerweise bei Iteration 2, da der Vergleichspunkt der Ausgangstext ist (Iteration 1).
Was können wir von dieser Analyse lernen?
Hier sind einige Lektionen, die Sie aus dieser ersten Analyse lernen können:
- Wenn Sie ChatGPT dieselbe Frage mehrmals stellen, sollten Sie nicht erwarten, grundlegend unterschiedliche Antworten zu erhalten. Die Antworten sind strukturell recht ähnlich. Das ist normal, da die algorithmische “Mechanik” hinter ChatGPT Sätze auf der Grundlage des nächstwahrscheinlichen Wortes bildet. Es ist also logisch, dass wir von einer Iteration zur nächsten ähnliche Satzstrukturen finden.
- Diese Untersuchung misst objektiv die Ähnlichkeitsrate zwischen den Antworten. Im Minimum liegt die Ähnlichkeitsrate bei 40%. Im Höchstfall liegt sie bei 86%. Im Durchschnitt liegt sie bei 73%.
Zwei von ChatGPT erstellte Texte zu unterschiedlichen Themen können sich zur Hälfte bzw. zu 2/3 ähneln.
Die faszinierende Fähigkeit von ChatGPT, ähnliche Antworten auf verschiedene Fragen zu geben
Unsere Methodik basiert auf identischen Fragen, bei denen sich nur der Gegenstand der Abfrage ändert. Von da an ist es möglich, Antworten auf verschiedene Fragen zu vergleichen.
Hier ist ein konkretes Beispiel. Wie nahe liegen die von ChatGPT verfassten Texte über Aktivierungs-Marketing (Thema A) denen über Astroturfing (Thema B)? Die Übung ähnelt derjenigen, die im ersten Teil dieses Artikels durchgeführt wurde. Der Unterschied liegt in der Aggregation der Punkte, die sich auf dieselbe Frage beziehen (Reihe A bis T). Für diesen Vorgang war die Datenvorbereitung in Anatella unerlässlich, denn es war notwendig, die Serien miteinander zu vergleichen. Ich werde die technischen Aspekte auslassen und Ihnen die Ergebnisse erläutern. Deshalb sind Sie ja hier, nicht wahr? 😉
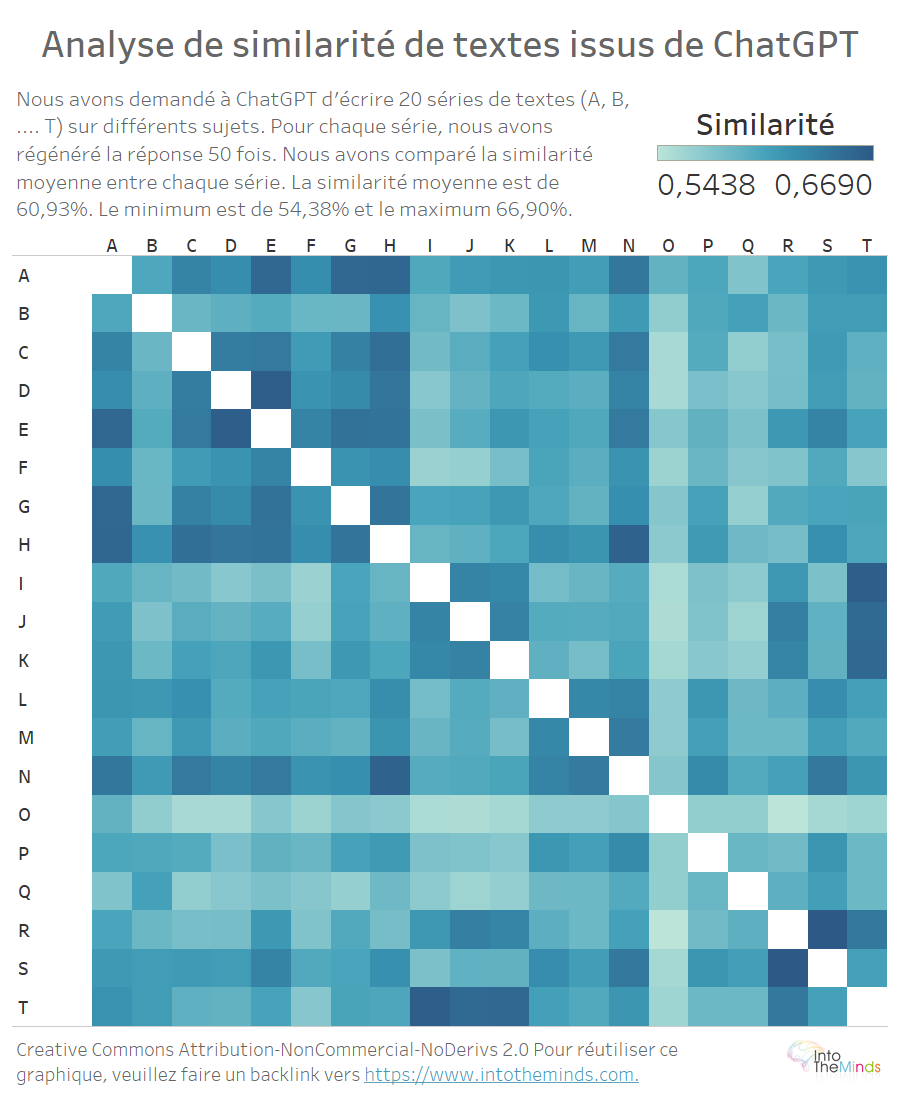 Anhand der obigen Heatmap können Sie die Ähnlichkeit zwischen den Texten, die für jede Frage erstellt wurden, visualisieren. Denken Sie daran, dass jeder Buchstabe (A bis T) für eine andere Frage steht. Das Thema ist von Satz zu Satz unterschiedlich, der Plan ist derselbe (Definition – Beispiele – Schlussfolgerungen – Referenzen). Man könnte meinen, dass die Ähnlichkeit zwischen Texten zu verschiedenen Themen gering ist. Ist sie aber nicht. Die minimale Ähnlichkeit liegt bei 54,38% und die maximale bei 66,90%. Die durchschnittliche Ähnlichkeit beträgt 60,93%. Das bedeutet, dass in unserem Experiment zwei von ChatGPT erstellte Texte zu verschiedenen Themen zur Hälfte oder zu 2/3 ähnlich sein können.
Anhand der obigen Heatmap können Sie die Ähnlichkeit zwischen den Texten, die für jede Frage erstellt wurden, visualisieren. Denken Sie daran, dass jeder Buchstabe (A bis T) für eine andere Frage steht. Das Thema ist von Satz zu Satz unterschiedlich, der Plan ist derselbe (Definition – Beispiele – Schlussfolgerungen – Referenzen). Man könnte meinen, dass die Ähnlichkeit zwischen Texten zu verschiedenen Themen gering ist. Ist sie aber nicht. Die minimale Ähnlichkeit liegt bei 54,38% und die maximale bei 66,90%. Die durchschnittliche Ähnlichkeit beträgt 60,93%. Das bedeutet, dass in unserem Experiment zwei von ChatGPT erstellte Texte zu verschiedenen Themen zur Hälfte oder zu 2/3 ähnlich sein können.
Was können wir von dieser Analyse lernen?
Die wichtigste Erkenntnis aus dieser Analyse ist, dass ChatGPT ähnliche Antworten auf unterschiedliche Fragen liefern kann. Das nächste Experiment ist eine Gelegenheit, das Verständnis für die Funktionsweise des Algorithmus zu erweitern, indem man ihm kein Design aufzwingt. Das vorgegebene Design hat etwas damit zu tun.
Bonus: Sind die von ChatGPT produzierten Texte immer gleich lang?
Um diese Untersuchung abzuschließen, schlage ich vor, die Unterschiede in der Länge der von ChatGPT produzierten Texte zu untersuchen. Da ChatGPT ein Plan auferlegt wird, sollten die Texte alle gleich lang sein. Auch hier ist das anders.
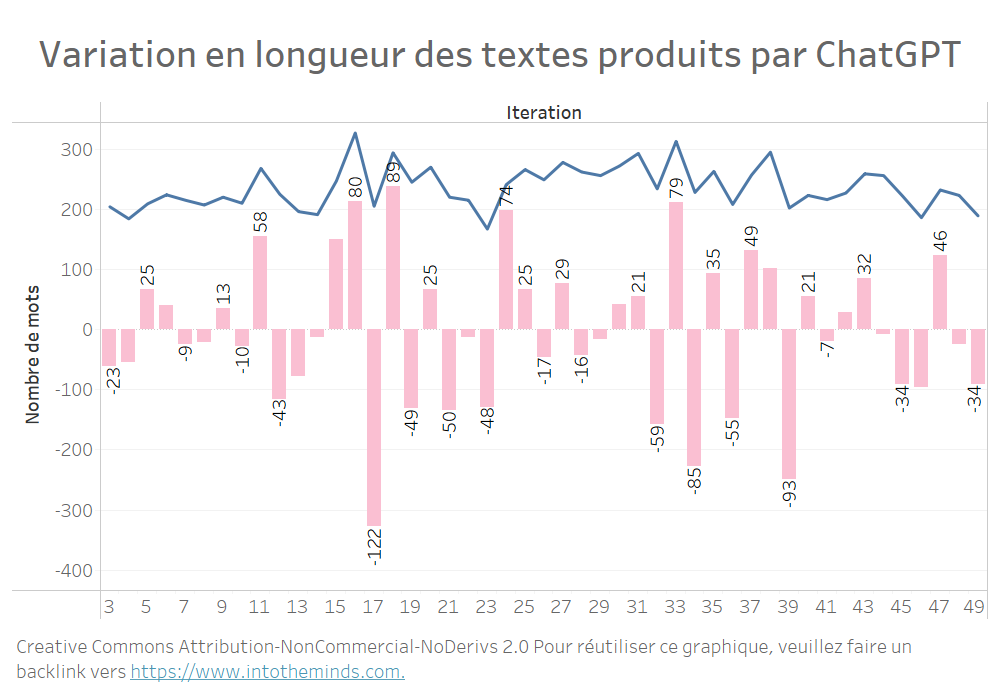
Beginnen wir mit Serie A, den 50 Iterationen von Texten, die ChatGPT zum Thema Aktivierungs-Marketing erstellt hat. Der durchschnittliche Text ist 237 Wörter lang. Aber zwischen einer Iteration und der nächsten kann die Länge drastisch variieren. Zwischen Iteration 16 und Iteration 17 verkürzt sich der von ChatGPT produzierte Text um 122 Wörter, von 328 auf 206 Wörter.
Bei allen 20 Themen sind die gleichen Schwankungen zu beobachten (Grafik unten). Ich wollte die Visualisierung nicht zu schwer machen, aber hier sind die maximalen Abweichungen:
- +200 Wörter zwischen den Iterationen 9 und 10 für das Thema I (“Net Promoter Score”)
- 232 Wörter zwischen den Iterationen 22 und 23 für das Thema M (“Celebrity Marketing”)
Bei den insgesamt 1000 produzierten Texten waren die maximalen relativen Abweichungen:
- +176%
- -70%
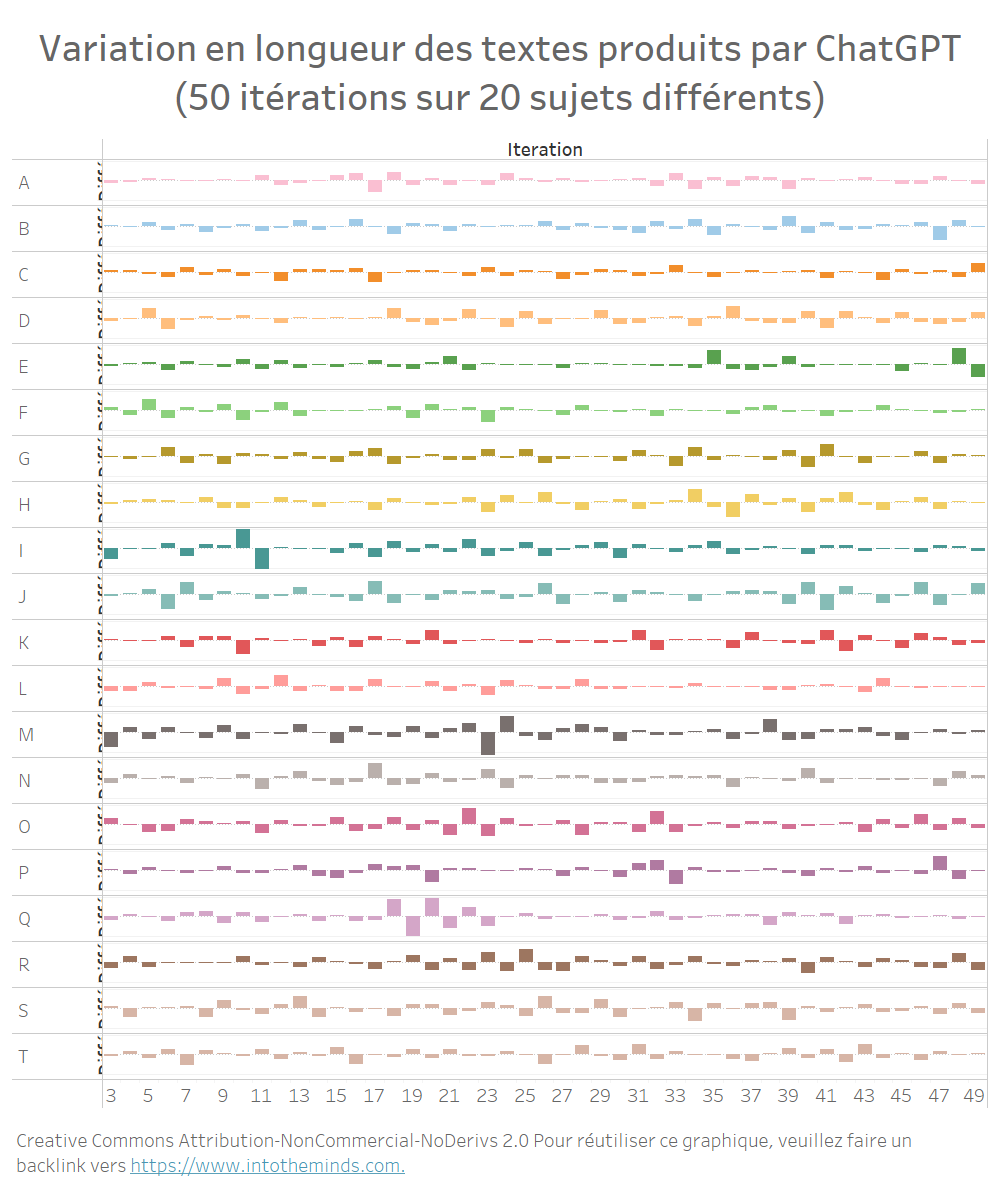
Was können wir aus dieser Analyse lernen?
ChatGPT produziert Antworten, die stark variieren, zumindest was die Textlänge betrifft. Die 1000 produzierten Texte weisen maximale Abweichungen von +176% und -70% auf. Die Länge der Texte ist also sehr schwankend.
Im nächsten Experiment werde ich den gesamten Korpus neu generieren, indem ich eine Wortzählung vorschreibe. Dies wird es mir ermöglichen, die Einhaltung der Anweisungen und die Streuung der Ergebnisse um das Ziel zu untersuchen.
Anhänge
Der Ablauf der Datenaufbereitung in Anatella
Erstens ist Anatella eine ETL-Software (Extract – Transform – Load), mit der Sie die Daten bearbeiten können, bevor Sie sie in eine andere Software einspeisen. Es ist aus mehreren Gründen meine Lieblings-ETL-Lösung:
- Erstens, weil sie ultraschnell ist (sehen Sie hier einen Benchmark).
- zweitens, weil sie eine viel breitere Palette von Tools anbietet als seine Konkurrenten. Sie können also problemlos komplexe Probleme angehen.
- der Editor (Timi) ist sehr reaktionsschnell und hat mir sogar eine benutzerdefinierte Funktion zur Verfügung gestellt, mit der ich eine spezielle Anforderung leicht erfüllen konnte (Berechnung der Ähnlichkeit zwischen einer großen Anzahl von Textpaaren (siehe Ablauf 2 unten)
Drei spezifische Datenaufbereitungsabläufe wurden in Anatella erstellt.
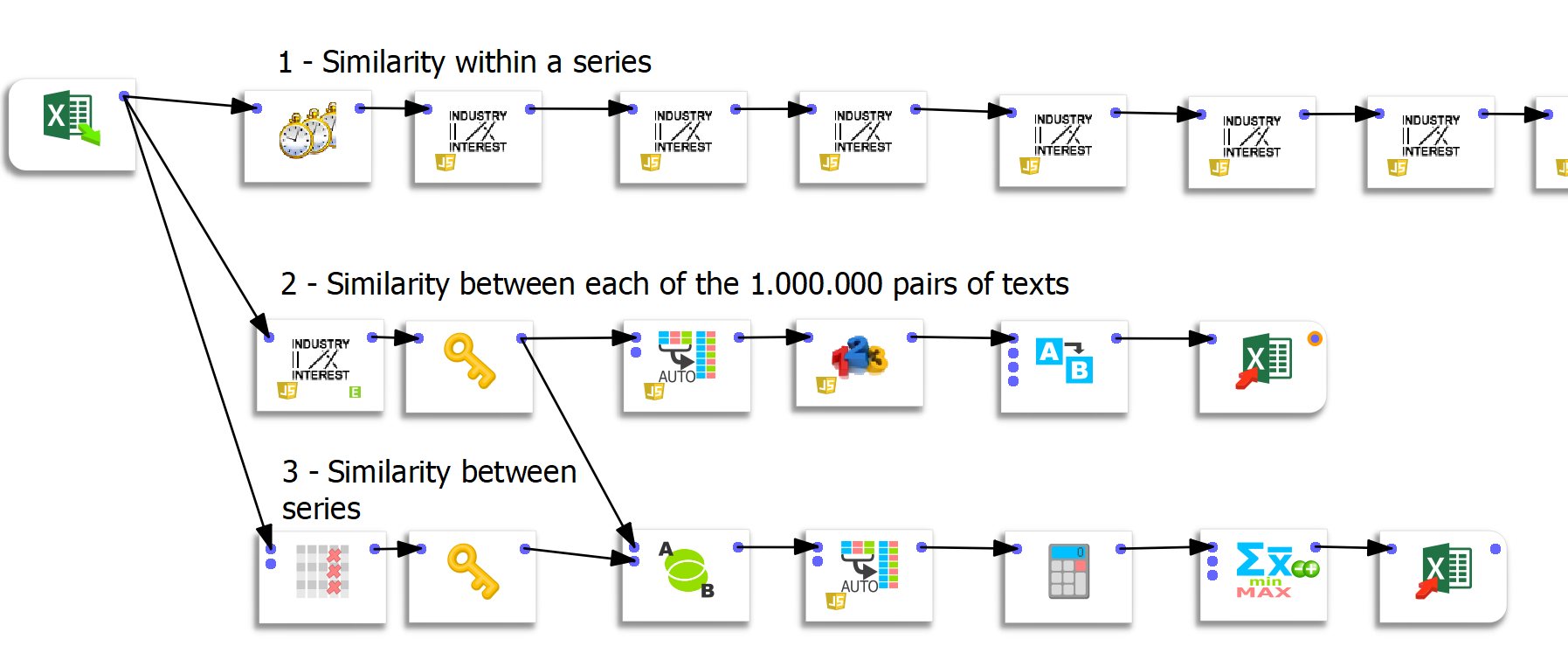
Ablauf 1: Berechnen von Ähnlichkeiten innerhalb einer Serie
This first flow is simple but rather redundant. The following boxes (there are 50) compute the similarity between iteration n and iteration 1. The first 2 boxes allow us to compute the similarity of an iteration concerning the previous one.
Ablauf 2: Berechnung der Ähnlichkeiten zwischen den einzelnen Textpaaren
Für diesen Ablauf danke ich Frank Vanden Berghen, der mir eine maßgeschneiderte Funktionalität zur Verfügung gestellt hat. Ich habe bereits ausführlich über die Qualitäten von Anatella gesprochen, und die Geschwindigkeit der Ausführung ist ein Vorteil gegenüber anderen ETLs. Die Herausforderung bestand hier darin, die Ähnlichkeit zwischen den einzelnen Textpaaren schnell zu berechnen. Da wir wussten, dass es für jede der 20 Fragen 50 Iterationen gab, entsprach dies 1000²=1.000.000 Möglichkeiten. Lassen Sie mich hier die extreme Geschwindigkeit des Prozesses hervorheben, denn die Berechnung von einer Million Ähnlichkeiten dauert nur 44 Sekunden.
Die Funktion “Unflatten” von Anatella erwies sich bei dieser Übung als sehr nützlich. Um Daten in Tableau zu importieren, müssen die Daten “entflacht” werden. Tableau kann jedoch nur maximal 700 Spalten verwalten. Da die Matrix 1000 Spalten lang ist, war es nur möglich, die Daten zu visualisieren, indem sie außerhalb von Tableau aufbereitet wurden.
Ablauf 3: Berechnung der Ähnlichkeit zwischen Serien
Der letzte Ablauf erzeugt eine Matrix zwischen den Serien. Es handelt sich also um eine 20×20-Matrix. Die Funktion “Gruppieren nach” vor dem Export in Excel ermöglicht es uns, die Ähnlichkeitswerte zu mitteln.
Liste der Themen
Hier ist die Liste der Themen, die bei ChatGPT eingereicht wurden.
| Référence | Sujet |
| A | Aktivierungs-Marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing als Dienstleistung |
| E | Marketing-Automatisierung |
| F | Emoji marketing |
| G | Reaktives Marketing |
| H | Straßen-Marketing |
| I | Net Promoter Score |
| J | Kundenerlebnis |
| K | Customer Lifetime Value |
| L | Markensicherheit |
| M | Promi-Marketing |
| N | Buzz marketing |
| O | Aufruf zum Handeln |
| P | Newsjacking |
| Q | Microblogging |
| R | Soziales CRM |
| S | Social-Media-Planung |
| T | Abwanderungsrate |





