

De eerste dag van de RecSys 2018-conferentie was gewijd aan tutorials. Een daarvan (Engels) ging over gemengde methoden voor de beoordeling van de tevredenheid van gebruikers. Ze werd georganiseerd door een team van Spotify onderzoekers (Jean Garcia-Gathright, Christine Hosey, Brian St. Thomas, Ben Carterette) en Fernando Diaz van Microsoft Research (Canada). De behandelde onderwerpen waren onder meer methoden van kwalitatief onderzoek, kwantitatief onderzoek en data-analyse; een combinatie van technieken die in feite zeer vergelijkbaar is met wat er in het marktonderzoek gebeurt.
Aanbevelingssystemen worden geëvalueerd aan de hand van systeemgerichte maatregelen.
Dit is het uitgangspunt en de rechtvaardiging van deze tutorial. De meeste metrieken die worden gebruikt om aanbevelingsalgoritmen te evalueren zijn eigenlijk “systeem-georiënteerd”: ze meten voornamelijk systeemfouten. Een uitstekend overzicht van deze metriek werd na RecSys 2017 door Marco Creatura voorgesteld. Zijn analyse toont in hoeverre deze metriek het onderzoek in de 2017-editie domineerde.
- MSE: gemiddelde kwadratische fouten
- maatregel F1
- MAE: gemiddelde absolute fout
- RMSE: gemiddelde kwadratische fout
- MAP: gemiddelde van de gemiddelde nauwkeurigheid
- Precisie en recall: recall is de fractie van de positieven die correct gelabeld zijn (recall = echte positieven /(echte positieven + valse negatieven)); precisie is de fractie van de als positief ingedeelde voorbeelden die echt positief zijn (precisie = echte positieven /(echte positieven + valse positieven)).
- nDCG : net discounted cumulative gain
- AUC (gebied onder de curve)
- MRR of “Mean Reciprocal Rank”: dit is de rang van het eerste correcte antwoord van een systeem.
Om meer te weten te komen over precisie, recall en de link naar de OCR-curve, verwijs ik u naar dit artikel (Engels).
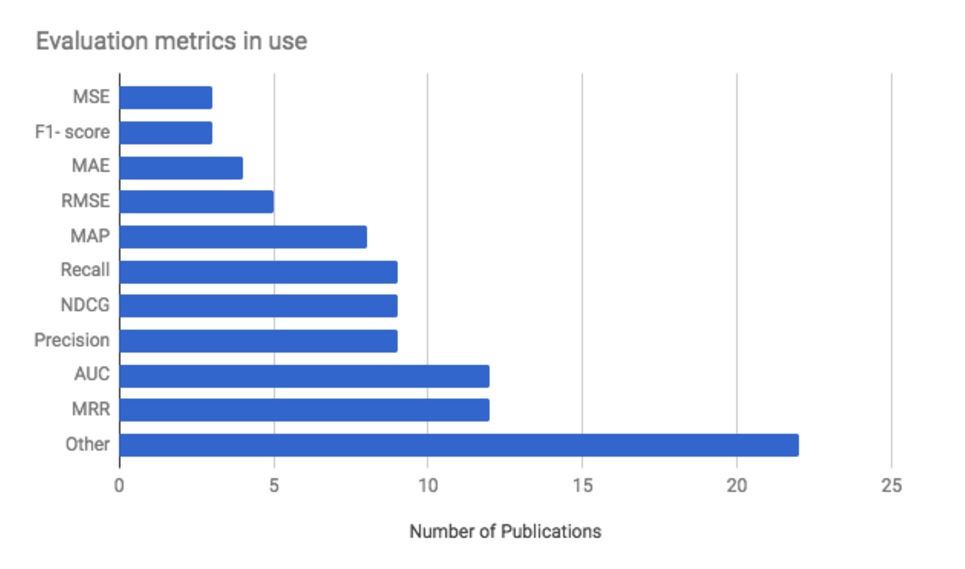
Marco Creatura’s analyse van de gebruikte metriek voor de evaluatie van de aanbevelingssystemen op RecSys2017
Om de tevredenheid te meten, moeten verschillende technieken worden gecombineerd
Naast systeemgeoriënteerde metrieken worden ook gebruikersgerichte kwantitatieve onderzoeken gebruikt (weliswaar minder vaak). Deze twee methoden worden echter zelden gecombineerd.
De voordelen van het combineren van de twee technieken (gebruikersstudies en systeemmetingen) stonden centraal in deze tutorial en waren voor veel deelnemers (waaronder ikzelf) een openbaring (of een heilzame herinnering). Ondanks mijn specialisatie in klanttevredenheid moet ik toegeven dat de dagelijkse routine van het ontwikkelen van aanbevelingsalgoritmen het perspectief doet verliezen op datgene dat er echt toe doet: klanttevredenheid!
Voorrang aan tevredenheid: gebruik eerst een kwalitatieve, dan een kwantitatieve methode
De sprekers beschreven de ideale methodologie als gemengd. Het begint met kwalitatieve onderzoekstechnieken om de betrokken gedragsfactoren te begrijpen en een uitgebreid gedragsmodel voor te stellen. Kwantitatieve technieken (enquêtes enerzijds, geregistreerde gegevens over gebruikersgedrag anderzijds) maken het vervolgens mogelijk om het model te verifiëren en de verschillende factoren die het gedrag beïnvloeden te kwantificeren.
We gaan niet in op de details van het kwalitatieve deel (we schreven een whitepaper over marktonderzoekstechnieken met een gedetailleerd hoofdstuk over kwalitatief onderzoek) en richten ons in plaats daarvan op het vastleggen van online gedrag.
Interpretatie van de prestaties van algoritmen: welk gedrag moet worden vastgelegd?
De vraag welke informatie moet worden verzameld om de prestaties van algoritmen te meten is cruciaal, maar wordt vaak oppervlakkig behandeld. De meeste metingen (inclusief de bovenstaande) zijn gebaseerd op een klikmeting. Dit is echter zeer onvoldoende om een constructie te begrijpen die zo complex is als de tevredenheid van de gebruiker met een algoritmische aanbeveling. De organisatoren van de workshop stelden voor om dit probleem aan te pakken door zich te richten op 4 gebieden:
- aandacht
- interactie
- succes van de uitgevoerde taak
- retentie/loyaliteit
Wat ik veel interessanter vind, is hun vermogen om eenvoudige definities voor elk van deze 4 assen voor te stellen. Wat kan bijvoorbeeld het nut van een aanbeveling zijn als de gebruiker deze niet ziet (“aandacht”) en wat wil de gebruiker bereiken als hij of zij een aanbeveling krijgt?
Dit zijn fundamentele vragen, maar vaak volledig genegeerd (weet ik uit ervaring).
Gemeenschappelijk online gedrag van gebruikers en hoe dat vast te leggen
Laten we verder ingaan op de details van deze 4 assen.
Oplettendheid
De vraag hier is of de gebruiker de keuze van het systeem heeft opgemerkt, met andere woorden of de gebruiker de algoritmische aanbeveling al dan niet heeft gezien. Deze niet zien leidt duidelijk tot inactiviteit, een gedrag dat we in een ander artikel hebben besproken.
Het meten van aandacht, een breder begrip dan alleen maar “gezien te hebben”, vereist registratie en analyse:
- laden van de pagina’s: een lange laadtijd kan aanbevelingen onzichtbaar maken.
- scrollen: gaat de gebruiker door over de pagina te scrollen voorbij aan de aanbevelingen zonder deze te zien? Kunt u aan de hand van de scroltijd afleiden of hij of zij de tijd had om de aanbevelingen daadwerkelijk te zien?
- cursor tracking: cursor tracking kan u helpen na te gaan of de gebruiker de aanbevelingen heeft gezien. Er zijn studies die de correlaties tussen oogbewegingen en cursorbewegingen vaststellen, waardoor we kunnen nagaan of er een aanbeveling is gevonden in het gezichtsveld van de gebruiker.
- tactiele aspecten voor mobiele apparaten: inzoomen op een aanbeveling is een voor de hand liggende manier om de aandacht van de gebruiker af te leiden
- oculometrie: het is de ideale methode om de ogen van de gebruikers te volgen en met zekerheid hun aandacht af te leiden. Deze methode geeft u informatie over zowel de oogbewegingen (het traject van de ogen bij het navigeren door een pagina) als de tijd die u aan de verschillende elementen besteedt.
Interactie met aanbevelingen
De interactie met de aanbevelingen is uiteraard erg belangrijk en omvat een reeks signalen die interessant zijn om te volgen. Dit zijn er enkele:
- klikken
- consumptietijd: hoe voor de hand liggend het ook lijkt, de consumptietijd wordt afhankelijk van het platform verschillend geïnterpreteerd. Het verbruiken van meer dan 3 seconden van een video op Facebook wordt beschouwd als iets te hebben gezien. Op YouTube is dat 30 seconden. De drempel is uiterst belangrijk en zal een belangrijke impact hebben op de manier waarop u uw gegevens analyseert.
- het opnemen van een item in een afspeellijst is ook een sterk signaal dat aangeeft hoeveel u van de aanbeveling houdt
- Het delen van een artikel over sociale media kan worden beschouwd als mond-tot-mondreclame en is een sterk signaal dat de gebruiker iets bijzonders voelt. Wees echter voorzichtig. Dit betekent niet noodzakelijkerwijs dat het gevoel van de gebruiker positief is. Mond-tot-mondreclame kan ook worden veroorzaakt door negatieve gevoelens.
- opmerkingen onder een aanbeveling zijn ook een sterk signaal dat de gebruiker iets voelt (weer positief of negatief)
- een expliciet feedbackmechanisme gekoppeld aan emoties is uiterst nuttig om het gedrag van de gebruiker met uw interface beter te begrijpen. Facebook-emoticons zijn een uitstekend voorbeeld van hoe u een onderscheid kunt maken tussen de verschillende gevoelens die een gebruiker kan voelen bij de interactie met uw content.
- de herconsumptie (vergeef met het neologisme) van een artikel is een uiterst sterk signaal. Zoals in het geval van “sharing” is dit gedrag niet noodzakelijkerwijs gekoppeld aan een positief gevoel. U haat de inhoud misschien zozeer dat u ze opnieuw wilt consumeren, maar de kans is nog altijd klein. Herconsumptie is over het algemeen een teken van een sterke affiniteit.
- Verdieping: dit is een zeer interessant gedrag dat vaak wordt vergeten. In de Spotify interface, bijvoorbeeld, kunt u op de naam van de artiest klikken voor meer informatie over hem/haar.
Succes van de taak
De belangrijkste vraag die u hier probeert te beantwoorden is: “Bereikt de gebruiker zijn doel met de aanbeveling?” Met andere woorden, is hij tevreden met de algoritmische aanbeveling?
Om het succes van een taak te evalueren, moet u volledig begrijpen wat de gebruiker probeert te bereiken. Het succes wordt gemeten aan de hand van het doel van de gebruiker. Als u een aanbeveling of een reeks aanbevelingen (bijvoorbeeld een afspeellijst) geeft, is een volledig verbruik een goed signaal dat de gebruiker tevreden is met de aanbeveling. De organisatoren van de workshop vestigden de aandacht van de deelnemers op een zeer interessante studie van Mehrotra et al (2017) (Engels). Dit artikel laat zien dat de context bepaalt hoe bepaalde signalen moeten worden geïnterpreteerd.
“Een verzoek is niets meer dan een veronderstelling over de attributen die het gewenste document moet hebben”
Behoud / loyaliteit
Als de algoritmische aanbevelingen door de gebruiker als nuttig worden ervaren, kunt u verwachten dat de gebruiker terugkomt en meer zal consumeren. Bijgevolg kan de gebruiker, als hij of zij de aanbevelingen apprecieert:
- vaker terugkomen (frequentie van gebruik)
- meer consumeren (verbruiksvolume)
- zijn of haar gedrag te veranderen (bijvoorbeeld op zoek gaan naar nieuwe onderwerpen)
- verder verkennen en zich “wagen” aan categorieën die ze voorheen niet gewend waren
Retentie/loyaliteit kan vele vormen aannemen. Dit is niet alleen de klassieke indicator van “pageviews per bezoek”. U moet zorgvuldig kiezen op basis van de context en uw begrip van wat de gebruiker wil bereiken.
Conclusies
Uiteindelijk vond ik deze workshop zeer nuttig. Ze heeft me geholpen om na te denken over hoe we gegevens verzamelen en analyseren voor onze klanten. Ik realiseer me dat het soms nodig is om terug te keren naar de basis en echt te proberen te begrijpen wat klanttevredenheid betekent. Ironisch genoeg kan ik als klanttevredenheidsexpert niet uitleggen hoe ik het belang van kwalitatief onderzoek en de dwingende noodzaak om een gedragsmodel te bouwen in een context van algoritmische aanbevelingen uit het oog ben verloren. Dit is waarschijnlijk een teken dat als men iets te lang doet, men riskeert zijn kritische geest te verliezen.
Referenties : R. Mehrotra, A. Hassan Awadallah, M. Shokouhi, E. Yilmaz, I. Zitouni, A. El Kholy, M. Khabsa. Deep sequential models for task satisfaction prediction. CIKM 2017.

![Illustratie van onze post "Turnover: welke strategieën implementeren bedrijven? [Studie]"](/blog/app/uploads/banner-millenial-employee-120x90.jpg)


![Illustratie van onze post "Human resources: stand van zaken met betrekking tot de digitalisering van processen [Onderzoek]"](/blog/app/uploads/concept-shapes-120x90.jpg)
![Illustratie van onze post "Generatie Z en werk: de perceptie van werkgevers [Studie]"](/blog/app/uploads/generation_y_youngsters-120x90.jpg)