

In het artikel van vandaag wil ik een nieuw perspectief presenteren op de evolutie van de modellering van consumentengedrag in de afgelopen 30 tot 40 jaar. Ik ga meer specifiek in op voorspellingsalgoritmen die legio zijn in onze Big Data-samenleving.
Inleiding
Inzicht in het consumentengedrag is niet iets van recente datum. Gedragsmodellering is lange tijd een prioriteit geweest voor marktonderzoekers, zowel academici als mensen uit de praktijk.
In de jaren zeventig (en daarvoor) had de sociale wetenschappen controle over de definitie van standaard consumentenprofielen. Dit maakte het mogelijk om de veranderingen in de samenleving te begrijpen. De vooruitgang op het gebied van de informatica (en met name de democratisering van de gedistribueerde informatica) heeft het mogelijk gemaakt zich los te maken van de sociologische analyse en alleen de sporen en signalen te gebruiken die de consumenten achterlieten. Deze sporen en signalen zijn aanwijzingen geworden die ons in staat stellen gedrag nauwkeuriger te modelleren. Het aantal verschillende modellen is dankzij de rekenkracht vermenigvuldigd tot het punt waarop elke consument nu individueel kan worden gemodelleerd. Met andere woorden, in plaats van u in een vooraf gedefinieerde box te dwingen, kunnen we nu een aangepaste box maken.
Expliciete en impliciete feedback
Zonder computers en geavanceerde verwerkingsmogelijkheden, was de enige manier om een momentopname van gedrag te krijgen het verzamelen van expliciete evaluaties van gebruikers: enquêtes, peilingen, het doel was om gebruikers expliciet om feedback te vragen over dit of dat aspect. Vandaag de dag wordt nog steeds op grote schaal gebruik gemaakt van expliciete feedback, maar een massale verwerking van de verzamelde gegevens is vereist: beoordeling van een film, beoordeling van een hotel of restaurant, beoordeling toegekend aan een Uberchauffeur, enz.
Expliciete feedback is dus zeker nog steeds relevant. Maar in termen van volume van verwerkte data zijn het de impliciete sporen die het grootste deel van het volume uitmaken.
Vandaag zijn de meeste geanalyseerde gegevens impliciete sporen: het nummer waarnaar u luistert, de film die u bekijkt, waar u die film pauzeert, wanneer u een snelle vooruitspoeling deed. Het systeem vraagt je niet om jezelf expliciet uit te drukken; je handelingen zijn voldoende impliciete elementen om je gedrag te modelleren en dingen over jezelf af te leiden. Dit wordt gevolgtrekking genoemd.
Expliciet of impliciet: wat te kiezen?
Er is geen antwoord op die vraag. Beide types van variabelen zijn vereist. Als we echter naar de laatste 30 tot 40 jaar kijken, zien we een duidelijke evolutie tussen deze twee soorten gegevens.
Vóór de opkomst van het internet waren de enige beschikbare gegevens van expliciete aard. Maar met de ontwikkeling van gewoonten met betrekking tot het gebruik van internet, is dit alles veranderd. Vandaag wordt prioriteit gegeven aan impliciete gegevens. Daar zijn verschillende redenen voor.
3 redenen waarom impliciete gegevens tegenwoordig Big Data domineren
Reden 1: Volume
Het volume aan impliciete gegevens dat kan worden verzameld is veel groter dan dat van expliciete gegevens, en het gaat om iedereen. In de expliciete wereld is iedereen vrij om te antwoorden of niet, waardoor het aantal verzamelde gegevens afneemt.
Reden 2: Waarneming feitelijk gedrag
Impliciete gegevens zijn opmerkelijk in die zin dat ze ons in staat stellen om de realiteit van gedrag te observeren en niet een projectie of een intentie van het individu.
Reden #3: Kosten
Het verzamelen van impliciete gegevens is een geautomatiseerde taak. De enige kosten die hieraan verbonden zijn, zijn opslagkosten. Voor expliciete gegevens is het soms nodig om ad-hoc verzamelinstrumenten te ontwikkelen om te enquêteren en om advies te vragen, en dat brengt kosten met zich mee.
Zijn er nog expliciete gegevens nodig?
Zorgvuldig marktonderzoek laat zien dat bedrijven die Big Data gebruiken voor voorspellende doeleinden zich nu min of meer op hetzelfde niveau bevinden op het gebied van modellering. Het rekening houden met expliciete variabelen maakt het mogelijk om modellen te verbeteren en een concurrentievoordeel te herstellen. Een recent opmerkelijk voorbeeld zijn de YouTube-aanbevelingen. Ten slotte krijgt de gebruiker de mogelijkheid om negatieve feedback te geven (“niet geïnteresseerd”) en zo een soortgelijke aanbeveling in de toekomst te vermijden.
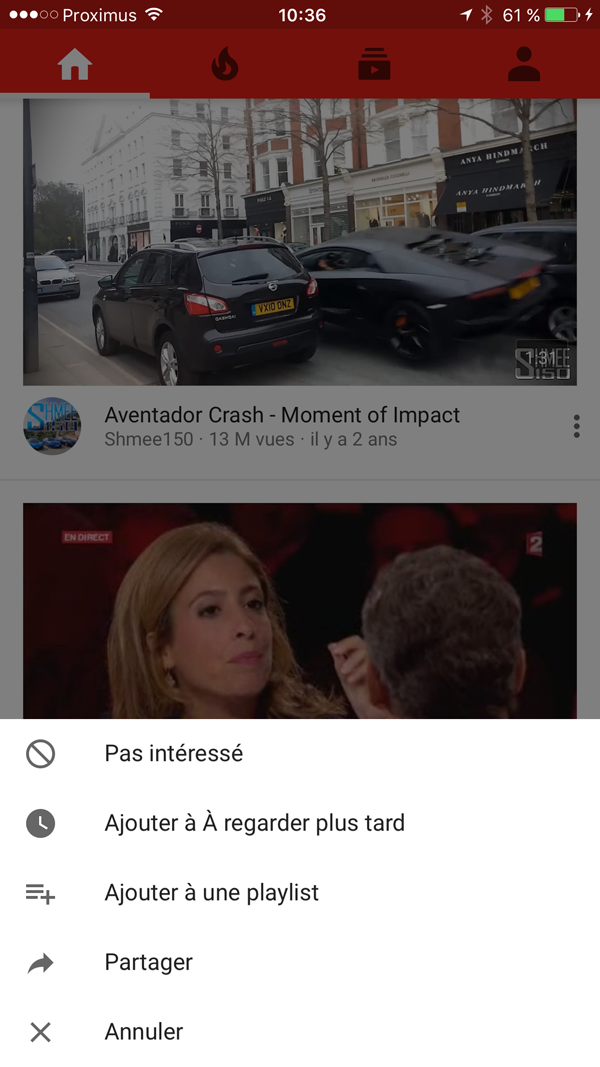
Voorbeelden van dit type zijn legio, zoals is aangetoond op de recente RecSys 2016-conferentie (Engelse tekst) in Boston. Ik vond met name het voorbeeld van Quora leuk (zie foto hieronder). Zoals je kunt zien heeft de gebruiker verschillende mogelijkheden om expliciet te interageren met de inhoud: upvote, downvote, commentaar, share.

Sommige vormen van expliciete feedback zijn subtieler
Wanneer een website alleen de eerste regels van een artikel toont en u vraagt om te klikken op “lees volgende” / “lees volledig artikel”, is het ook een vorm van expliciete feedback die het bedrijf een signaal geeft dat u een sterke interesse hebt in de inhoud die u zojuist aangeboden wordt.

Waarom expliciete variabelen belangrijker zijn dan ooit
Gewoontes veranderen en, zoals we in een ander artikel hebben uitgelegd, hebben marketingonderzoekers aangetoond dat gebruikers de neiging hebben om zich aan te passen aan de verwachtingen van algoritmen. Als gevolg daarvan verliezen impliciete signalen een deel van hun voorspellende kracht.
Belangrijker is dat in sectoren waar intensief gebruik wordt gemaakt van voorspellingsmodellen, nu wordt gestreden voor marginale verbeteringen. Iedereen beschikt over dezelfde gegevens, datawetenschappers verhuizen van het ene bedrijf naar het andere, maken gebruik van vergelijkbare modellen. De resultaten zijn over het algemeen vergelijkbaar en de differentiatiecriteria moeten elders worden gezocht.
Deze laatste kunnen zich dan ook verschuilen achter de verscheidenheid van de verzamelde gegevens. Vandaar de huidige nadruk op expliciete variabelen als middel om modellen te verbeteren.


![Illustratie van onze post "Dark stores: analyse van cijfers en vooruitzichten [Onderzoek]"](/blog/app/uploads/dark-store-120x120.jpg)

![Illustratie van onze post "Pricing: strategieën, technieken, voorbeelden [gids 2025]"](/blog/app/uploads/pricing-120x90.jpg)
