

En el mundo de los datos, la gestión de datos se ha convertido en la actualidad en una palabra de moda. Ya hemos propuesto una visión general aquí. En el artículo de hoy, lo explicamos en más detalle y ubicamos la gestión de datos dentro del ciclo de valor de los datos.
Resumen
- Recordatorio sobre la gestión de datos
- Paso 1: Adquisición de datos
- Paso 2: Almacenaje de datos
- Paso 3: Explotación de datos
¿Qué es la gestión de datos?
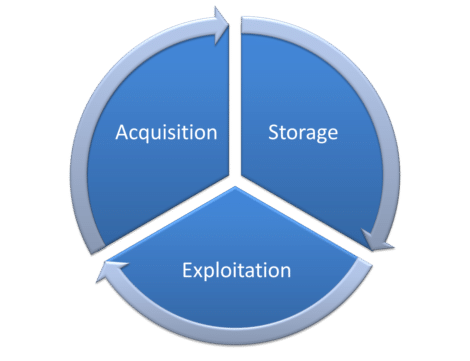
La gestión de datos es un término que hace referencia a una serie de actividades necesarias para extraer valor de los datos. Estas actividades se ubican principalmente en el nivel 1 (adquisición) del ciclo de gestión de datos (diagrama a continuación). También se encuentran, en menor medida, en la parte 3 (explotación).
La diferencia entre la gestión de datos, por un lado, y la preparación de datos / exploración de datos, por la otra, es minúscula; el término se usa principalmente en un contexto en el que los datos son «un caos» y el volumen es alto.
El uso comercial del término «gestión de datos» se debe a Trifacta. Para marcar la diferencia en la preparación de datos / exploración de datos, Trifacta añade la gestión de datos a través de una inteligencia artificial. Pero no nos engañemos; no se trata más que de un truco comercial.

crédits : Shutterstock
PASO 1: Adquisición de datos
La adquisición de datos es el núcleo de la actividad de gestión de datos. Es en este nivel donde tienen lugar las actividades relacionadas con la preparación y exploración de datos.
Recoger datos a partir de varias fuentes
Uno de los primeros retos es recopilar la información que hoy en día está «dividida» en multitud de archivos. La expansión de los datos es tal que estudios recientes estiman que las empresas no listan el 52% de los «datos a la sombra». Los archivos pueden ser estructurados (Excel, CSV, archivos de tablas relacionadas) o no estructurados (XML, JSON, PDF), y pueden provenir del negocio en sí mismo o del exterior.
Descubrimiento de datos y comprender la fase
Durante esta fase, intentamos dar respuesta a la pregunta: «¿Qué contiene cada fuente de datos?». Para hacerlo, resulta útil tener:
- Una herramienta que te permita preparar rápidamente algunos gráficos para orientarte visualmente en cuanto a los datos (ver mi clasificación de funcionalidades ETL esenciales para este propósito)
- Una diccionario de metadatos
Limpieza de datos
Pensar que tus datos quedarán «listos para usar» directamente es engañarte a ti mismo. Primero tendrás que limpiarlos, asegurándote de que, por ejemplo, la columna «sexo» solo contiene 3 valores distintos (masculino, femenino, desconocido) y ninguno más.
Enriquecimiento de datos
En la época de la LOPD y el borrado de las cookies de terceros, el enriquecimiento de datos se realiza principalmente cruzando fuentes de datos internas, aunque el enriquecimiento a través de fuentes de «datos abiertos» también resulta interesante.
Aquí tienes un ejemplo bastante extendido: la primera tabla contiene todos los clientes con sus nombres de pila, mientras que la segunda tabla es un diccionario de los nombres de pila e incluye, para cada uno de esos nombres, el sexo (disponible en este caso como datos abiertos). Al cruzar estas dos tablas basándonos en el nombre de pila, podemos hacer una suposición sobre cuál es el sexo del cliente.
En esta fase o en la anterior (limpieza de datos), las coincidencias difusas podrían resultar interesantes para corregir errores dispersos aquí y allá.
Reestructurando los datos
Si se han usado datos no estructurados (XML, JSON, PDF), tendrán que ser reestructurados (ej.: organizados en un formato tipo tabla).

crédits : Shutterstock
PASO 2: Almacenaje de datos
Una vez los datos recogidos hayan sido limpiados, estructurados y enriquecidos, será hora de almacenarlos en un data lake (o, históricamente, en un almacén de datos).

crédits : Shutterstock
PASO 3: Explotación de los datos del data lake
¿De qué servirían los datos si no los explotáramos? Esa es la razón del último paso en el ciclo de explotación de datos.
La explotación de datos habitualmente incluye:
Análisis de datos
El análisis de datos puede hacerse, por un lado, a través de la visualización, y por el otro identificando los indicadores de rendimiento (KPI). Un buen gráfico o un KPI bien diseñado destacará los procesos que se estén deteriorando. A menudo se usan modelos predictivos para comprender por qué una función en concreto se está deteriorando (y para remediarlo). La gestión de datos incluirá la implementación de KPI con el objetivo de monitorizarlos.
Modelo predictivo
La construcción de esos modelos predictivos incluye:
Ingeniería de características: consiste en crear las variables correctas para obtener modelos predictivos precisos y robustos. Al final de este paso, obtendremos un conjunto de datos «mejorado» llamado CAR o ABT.
El uso de herramientas de «machine learning» (llamadas habitualmente «herramientas IA») que analizan las variables disponibles para obtener «modelos predictivos». Se trata de observar los patrones recurrentes del pasado y extraer conclusiones que nos permitan predecir el futuro.
Segmentación
En el mundo del marketing adoramos la segmentación, excepto que la mayor parte del tiempo esta no se basa en el comportamiento real (observado) del consumidor. Ahí es donde los datos se vuelven extremadamente valiosos, ya que pueden permitirte agrupar a tus clientes según unas variables que no se te habrían ocurrido de manera espontánea.

crédits : Shutterstock
Para concluir
Hemos explicado las 3 fases principales del ciclo vital de los datos: adquisición, almacenaje, explotación, haciendo así que el concepto de gestión de datos vuelva a hacer acto de presencia en el escenario.
Estas 3 fases no tienen por qué ser secuenciales. De hecho, cuando se ejecuta el paso 3 (la explotación de los datos), es muy habitual descubrir que:
- Faltan datos imprescindibles para que las KPI calculadas sean relevantes.
- Parte de los datos recogidos se ha corrompido o no es válida (ej.: se lleva a cabo una unión que debería funcionar en el 100% de las líneas, y nos damos cuenta de que las claves unidas a menudo están mal, lo cual lleva a errores en la unión y esa unión acaba funcionando exclusivamente el 20% del tiempo).
Cuando ocurre algo así, es necesario volver al punto 1 y reunir los datos adicionales necesarios o mejorar el proceso de extracción para conseguir datos de más calidad. En la práctica, a menudo en un mismo negocio hay diversos equipos trabajando en paralelo en cada uno de estos pasos.
![Ilustración de nuestra publicación "Detectores de IA generativa gratuitos: ¿cuáles elegir? [Prueba completa 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)




