

En un artículo anterior, compartí con ustedes una solución útil para realizar un fuzzy matching entre 2 tablas diferentes. Luego, compartí 2 soluciones ETL (Extract Transform Load). Tableau Prep Builder no logró el resultado deseado. Así que recurrí a Anatella. En el artículo de hoy, exploraré los diferentes algoritmos de Fuzzy Matching disponibles en esta herramienta y sus efectos. Como verá, tenemos un algoritmo ganador en esta comparación.
 Introducción
Introducción
 Introducción
IntroducciónPara realizar una combinación entre varias tablas, tenemos 2 soluciones. O bien la clave de unión sigue exactamente la misma nomenclatura en ambas tablas, o no. Si se encuentra bendito caso de la primera situación, puede dejar aquí su lectura, este artículo no le enseñará nada. Si, por el contrario, se encuentra en el 2º caso (o simplemente tiene curiosidad), le deseo una feliz lectura..
Algoritmos de fuzzy matching
 Algoritmos de fuzzy matching
Algoritmos de fuzzy matchingEn este caso, el fuzzy matching se realiza a partir de una clave de combinación que contiene nombres de países. Existen muchos métodos útiles para calcular la similitud entre 2 entidades. Lo que me gusta de Anatella es que, a diferencia de otros ETL, te ofrece la posibilidad de elegir entre 4 métodos:
- Damereau Levenshtein distance
- Damereau Levenshtein similarity (igual que el primero incluso delimitado entre 0 y 1)
- Jaro Winkler similarity
- Dice similarity
Existen, por supuesto, otros métodos para calcular la similitud. Raffael Vogler ofrece un buen resumen de las diferentes técnicas disponibles en el paquete “stringdist” para R.
Similitud de Jaro-Winkler
Este método, aplicado desde el 1999, es una evolución del método de Jaro (1989). La puntuación obtenida varía entre 0 y 1 y se calcula comparando los caracteres correspondientes en una cadena y en la otra, teniendo en cuenta las transposiciones de los caracteres.
Damereau Levenshtein distance
Se trata de un método antiguo (1964) que permite calcular el número de pasos necesarios para transformar una cadena (a) en una cadena (b). Las operaciones permitidas son la supresión, la inserción, la sustitución de un solo carácter y la transposición de 2 caracteres adyacentes. La distancia calculada es, por tanto, un número entero que corresponde al número de pasos necesarios para la transformación (0 cuando las cadenas a y b son idénticas).
Similitud DICE
También este método es bastante antiguo (1948) y consiste en una simple comparación de diagramas. El coeficiente se aproxima al índice de Jaccard. Le remito a la página de Wikipedia para ver algunos ejemplos importantes.
Resultados

Aquí están los resultados. Le recuerdo que no son transponibles a ningún caso concreto. Hay que estudiar previamente cada caso para encontrar el método más adecuado. En este caso, se trata de un fuzzy matching entre nombres de países que corresponden a nomenclaturas diferentes. Le remito a mi artículo de la semana pasada para consultar la lista de casos.
Para comparar los resultados producidos por los diferentes algoritmos, he modificado un poco el flujo en el ETL (Anatella) para poner en paralelo los 4 tipos de “fuzzy joins” propuestos. El proceso se muestra en azul en el diagrama de abajo (haga clic en él para ampliarlo).
Para facilitar la lectura he exportado los resultados a un archivo Excel (descargar aquí).
Los resultados a veces son sorprendentes.
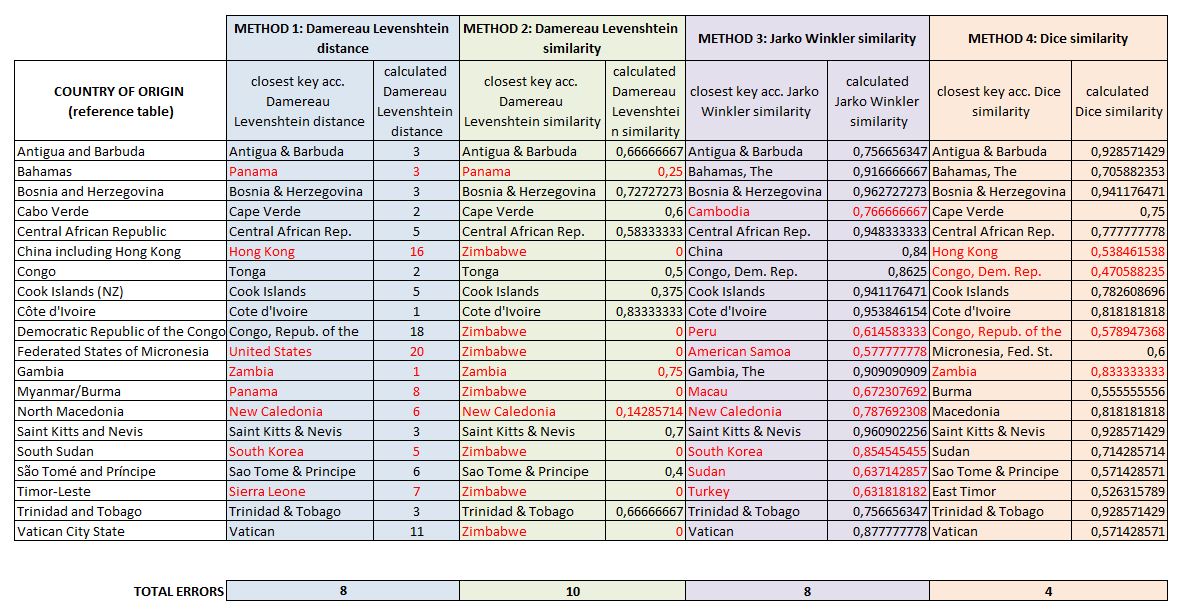
El segundo método parece ser el preferido en Zimbabue y difiere del método 1 (que está más o menos cerca). Podemos ver que los errores de clasificación a veces son bastante crudos (Sudán del Sur / Corea del Sur).
El método 3 (Jaro Winkler) es ligeramente mejor, pero los errores de clasificación siguen siendo demasiado frecuentes. Sin embargo, tiene una ventaja importante (véase el párrafo siguiente).
El método 4 (similitud de Dice) ofrece los mejores resultados. El error de clasificación de Hong Kong puede atribuirse a razones obvias (véase la casilla en la tabla de referencia). El error sobre “Gambia” se explica fácilmente por el enfoque diagramático del método Dice-Sorensen.
Definición de un coeficiente umbral
Para evitar acabar con falsos positivos o falsos negativos, es útil definir un coeficiente de umbral para rechazar los resultados que requieren un tratamiento manual.
Para el método de Damereau Levenshtein (métodos 1 y 2) vemos que este enfoque no es muy eficiente porque el algoritmo da falsos positivos con distancias calculadas bajas (ver Bahamas, Gambia, Macedonia del Norte, Sudán del Sur).
Para Dice, la definición de un umbral en torno a 0,5 no permitiría detectar los 2 falsos positivos y también daría un falso negativo (Congo).
Para el método 3, la definición del umbral en torno a 0,8 habría eliminado todas las coincidencias pérdidas, pero también habría generado un falso negativo (Trinidad y Tobago).
 Conclusión
Conclusión
 Conclusión
ConclusiónEl método de Dice (también llamado método de Sorensen) ofrece en este ejercicio los mejores resultados para realizar un fuzzy matching entre nombres de países. El método de Jaro-Winkler, en cambio, permite definir un umbral en 0,8, que elimina los resultados incoherentes.


![Ilustración de nuestra publicación "Detectores de IA generativa gratuitos: ¿cuáles elegir? [Prueba completa 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)


