
![Preparación de datos: definición, ejemplos, consejos [guía 2023]](/blog/app/uploads/desk-research-data-graphs-figures.jpg)
Para hablar de la preparación de datos, lo mejor es empezar desde la observación. En el mundo de los datos, hay una regla que conoce todo el mundo: el 80% del tiempo de un científico de datos se dedica a preparar sus datos, y sólo el 20% a trabajar en ellos, especialmente en su visualización. Este artículo se centrará en la preparación de los datos: los problemas más frecuentes, las herramientas y las tendencias. ¡Vamos a por nuevas aventuras de datos!
Resumen
- Introducción
- Preparación de datos: definición
- Los 5 pasos de la preparación de datos
- Herramientas útiles para la preparación de datos
- Problemas recurrentes en la preparación de datos
 Introducción
Introducción

Todos sabemos que los datos están en todas partes y son el motor de la innovación digital. La multiplicación de las aplicaciones, la creciente participación de Internet en nuestras vidas, el auge del IoT (Internet de las cosas) son factores que explican el desarrollo de actividades específicas en torno a los datos. Por lo tanto, han aparecido nuevas funciones en los departamentos de TI: ingeniero de datos, especialista en visualización de datos y científico de datos. Cada uno de ellos interviene en distintas fases del proceso de mejora de los datos. Pero todos tienen una necesidad común: datos de calidad. En eso consiste la preparación de datos.
3 consejos para elegir una herramienta de preparación de datos (ETL)
- Elegir una herramienta con muchos conectores de entrada
- Es fundamental disponer de muchas funciones para transformar los datos. Las ETL suelen trabajar con “cajas” que hay que conectar. Por lo tanto, asegúrese de que el ETL que elija sea completo en cuanto a estas cajas.
- Las combinaciones son especialmente importantes. Elija una herramienta que tenga varios tipos de combinación. Una con el fuzzy matching suele ser muy útil y debería formar parte de las características ofrecidas
Preparación de los datos: definición
El término “preparación de datos” se refiere a las operaciones realizadas en los datos brutos para hacerlos analizables.
La preparación de los datos, a menudo tediosa, implica la importación de los datos, la comprobación de su coherencia, la corrección de los problemas de calidad y, si es necesario, el enriquecimiento con otros conjuntos de datos.
Cada paso es esencial y requiere funcionalidades específicas, especialmente en el momento de la transformación de los datos.
preparación de los datos = las operaciones que se realizan sobre los datos brutos para hacerlos analizables
Las 5 etapas de la preparación de datos
Hay que reconocerlo: no existe un único “flujo de trabajo”, y no pretendo presentar la verdad absoluta sobre la preparación de datos. Basándome en mi experiencia, he intentado agrupar las tareas recurrentes en pasos lógicos. Al final, que sean 5, 6 o 7 tiene poca importancia. Lo que importa es que usted entienda el contenido de cada operación.
Importar o adquirir datos
 Importar o adquirir datos
Importar o adquirir datosEl primer paso es “adquirir” los datos necesarios para el trabajo. Estos datos pueden proceder de diferentes lugares, tener diferentes formatos. Por lo tanto, es fundamental elegir una herramienta que disponga de múltiples conectores para no quedarse atascado. Si los archivos planos son uno de los formatos más comunes, no hay que descuidar los formatos más exóticos. En este ejemplo de preparación de datos a partir de archivos extraídos de LinkedIn, fue necesario preparar archivos planos (en formato CSV) junto con archivos .har y JSON. Cuando se habla de importar datos, hay que estar preparados para cualquier eventualidad.
Descubrimiento
 Descubrimiento
DescubrimientoLa segunda etapa es bastante emocionante. Se trata de descubrir los datos, de explorarlos. En esta etapa, el objetivo no es analizar las correlaciones, sino buscar los errores que puedan haberse colado. Es esencial identificar los campos vacíos, los formatos de los datos. Una visualización rápida es útil para este propósito porque le permitirá ver de inmediato si el formato de los datos es el correcto (intente hacer un gráfico si sus datos están almacenados en texto). Cuando uso Anatella, aprecio poder consultar las estadísticas descriptivas de los datos en 1 clic. De esta manera, tengo la oportunidad de identificar inmediatamente las categorías erróneas, los valores atípicos y, especialmente, los valores “nulos”. Aproveche la etapa de descubrimiento de datos para realizar algunas pruebas sencillas para detectar problemas menos obvios que deban corregirse en la siguiente etapa. Por ejemplo, utilice funciones de clasificación para detectar duplicados.
Limpieza de datos
 Limpieza de datos
Limpieza de datosEn la tercera etapa de la preparación de los datos (también llamada “data prep” si queremos parecer más profesionales), hay que organizar y limpiar los datos. En esta etapa, me gusta reorganizar ya y renombrar las columnas y eliminar las redundantes cuando sea el caso. De esta manera podemos tener las premisas de un modelo de datos y la primera piedra de tu diagrama UML. Luego llega el momento de entrar en más detalles. Durante la etapa del descubrimiento, ya ha podido corregir los problemas de formato más evidentes. Ahora es el momento de sacar a la luz los problemas menos evidentes. Por ejemplo, las dificultades de los duplicados (deduplicación), la separación de datos. La limpieza de datos también puede incluir una parte de “transformación”. Por ejemplo, se puede detectar una categoría de datos que necesita ser modificada para ser utilizable. En caso de que su conjunto de datos contenga valores atípicos, las operaciones de transformación son útiles para explotar sus valiosos datos.
Mejora de datos
 Mejora de datos
Mejora de datosLa mejora de datos (cada vez más llamada “data wrangling” o “data munging”) consiste en “aumentar” su conjunto de datos con datos externos. Para ello, es necesario crear una combinación. Hay diferentes tipos de ombinaciones. Lo que me gusta de una solución como Anatella es la posibilidad de elegir entre diferentes tipos de combinaciones. Uno de ellos es increíblemente único porque es un tipo de combinación de fuzzy matching. Esta característica es tan única que incluso escribí un artículo comparando los procesos de Anatella, Alteryx y Tableau Prep. Es posible realizar uniones simples (después de haber limpiado todos los datos) directamente en su solución de visualización de datos (vea nuestra guía de DataViz aquí). Esta práctica tiene ventajas y desventajas. Yo prefiero preparar mis datos en un solo paquete de software y, una vez terminado el proceso, comenzar el trabajo de análisis.
Publicación
 Publicación
PublicaciónUna vez terminados los procesos de organización, limpieza y mejora, lo único que queda por hacer es publicar el conjunto de datos final. La mayoría de las veces, los datos se “suben” a la nube o se exportan. Dependiendo de cómo vaya a utilizar los datos después de la preparación de los mismos, puede ser útil optar por la exportación en un formato de datos optimizado. Por ejemplo, si trabajas como yo con Tableau, es recomendable exportar los archivos en formato .hyper. Que yo sepa, el ETL que utilizo (Anatella) fue el primero en tener salida en este formato.

Preparación de datos: las herramientas
A pesar de que algunos desarrolladores empedernidos prefieran realizar todo el trabajo a mano con líneas de código, yo hace tiempo opté por soluciones “sin código” que funcionan de forma mucho más eficiente. Tabajo con Tableau Prep, Alteryx y Anatella. Pero hay quien prefiere Talend, Azure Data Factory, Informatica Power Center. Como puede ver, las herramientas son muchas, y ese puede ser el problema. Hay tantas que la elección se hace difícil.
Si está buscando una solución gratuita, le aconsejo Anatella, comercializada por Timi. Yo soy un fanático, e incluso le estoy enseñando a usarlo a mi hijo de 11 años. Hace algunas demostraciones en vídeos sobre diversos problemas de datos (separación de datos, deduplicación).
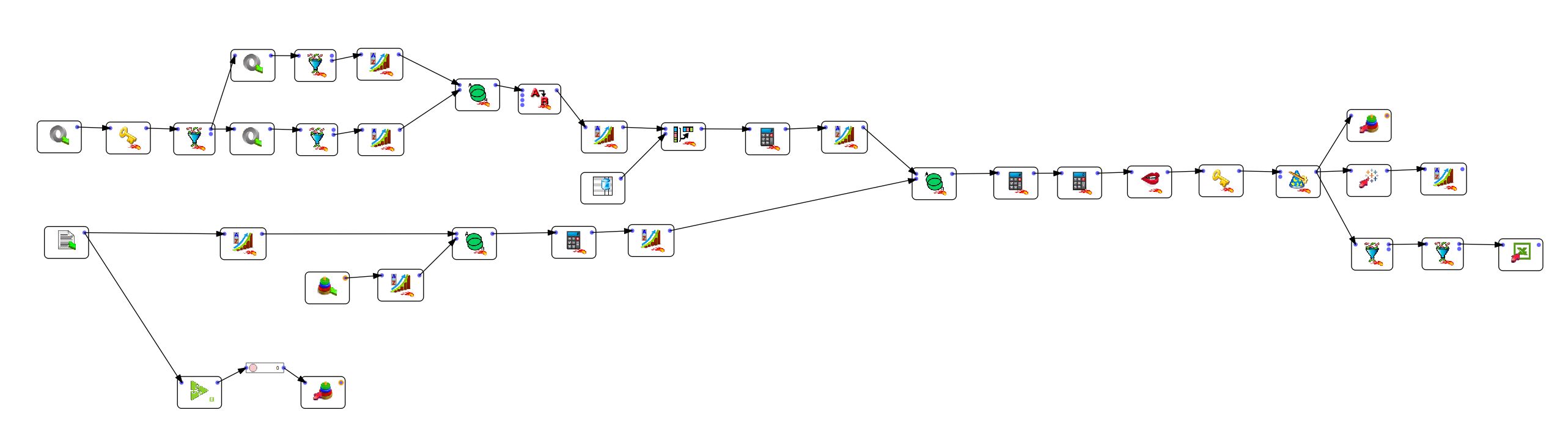
Para algunos puntos específicos de la preparación de datos, existen soluciones alternativas. Por ejemplo, se puede realizar una combinación en un ETL o directamente en la mayoría de las soluciones de visualización de datos. Used elige. Consulte la siguiente tabla para ver las desventajas de ambos enfoques.
| Ventajas | Desventajas | |
| Combinación en el software de preparación de datos (ETL) | Es posible gestionar todos los aspectos de la preparación de datos en un único lugar. La limpieza de datos, en particular, no siempre es posible utilizando un software de visualización de datos. Sólo es posible realizar las operaciones más sencillas con el software DataViz. | Si ha cometido un error (descubierto en el software de visualización), tendrá que reabrir su ETL y volver a exportar los datos |
| Combinación en el software de visualización de datos | La simplificación: usted realiza la combinación, y puede visualizar directamente el resultado. No es necesario, como con el software ETL, exportar los datos en un formato intermedio. | Es imposible realizar operaciones de transformación complejas en los datos. En PowerBI o Tableau, puedes cambiar los formatos de los datos, separarlos en la misma columna, y poco más. |
¿Qué es el ETL (Extract – Transform – Load)?
El software ETL, o Extract-Transform-Load, se utiliza para gestionar todos los aspectos de la preparación de datos:
- Extraer: extraer los datos de un archivo, sea cual sea su formato.
- Transformar: limpiar y transformar los datos para hacerlos utilizables.
- Cargar: Exportar los datos y cargarlos en un entorno en el que estén disponibles para la siguiente fase de valoración.

Preparación de datos: problemas frecuentes
A continuación, he tratado de enumerar algunos de los problemas más frecuentes en la preparación de datos
| Problema | Descripción | Solución |
| duplicados | Los datos están duplicados en el conjunto de datos, lo que puede inducir errores de análisis | Deduplicación de datos en uno o más campos |
| combinaciones | La combinación de 2 o más conjuntos de datos mediante una “clave” de unión. | Los ETL suelen tener varios tipos de uniones. Anatella, por ejemplo, propone 6 tipos de combinaciones, uno de los cuales es un tipo de fuzzy matching. |
| diferencias ortográficas | Los usuarios han introducido los datos (nombre, apellido, ciudad) de forma diferente, lo que imposibilita el análisis. | Corrección basada en un diccionario o en el fuzzy matching (véase este artículo para más información sobre el fuzzy matching) |
| diferencias de formato | El problema más común es el uso del punto para el decimal en el mundo anglosajón en lugar de la coma. | Adaptación de los formatos regionales durante la importación de los datos o transformación posterior. En las herramientas de BI, es posible especificar el formato regional en el momento de la importación de los datos. |
| números almacenados como texto | Error a menudo debido a la presencia de espacios u otros signos que impiden el reconocimiento del formato. | Elimine los signos que “contaminan” el campo (sean visibles o no) y luego cambie el formato. En las herramientas de BI, puede utilizar el comando “split” (extraer en PowerBI). En los ETL como Anatella, la operación es aún más sencilla, ya que se pueden eliminar los caracteres innecesarios al importar los datos. |
| diferencias de codificación | “Codificación de texto” que cambia entre 2 archivos que deben ser procesados en el mismo proceso (Latin1/iso8859 y utf-8 por ejemplo). | Especificación del método de codificación al importar los datos |
| espacios en las celdas | Se trata de un problema muy común pero difícil de detectar porque no todas las celdas pueden tener espacios en ellas. | Eliminación de espacios no deseados al importar los datos. En Anatella utilice la opción “Recorte”. |





