
Cuando se trata de preparar datos, está claro que una buena parte de los procesos siguen produciéndose offline con archivos extraídos de bases de datos relacionales. Y cuando los ingenieros de datos tienen que manipular esos archivos, tener una ETL que pueda soportar la carga se vuelve esencial.
En el artículo de hoy propongo que abordemos el fascinante tema de los grandes archivos comparando 2 ETL que uso de manera diaria: Alteryx y Anatella.
Contexto empresarial: ¿cuándo se manejan archivos de gran tamaño?
Tal y como mi amigo Marc Bouvet de DaltaLab nos recordaba en un vídeo dedicado al tema, los archivos (zip, rar, etc.) son el resultado de extracciones de sistemas de bases de datos relacionales. Un archivo plano por tabla puede verse manipulando archivos de varios gigabytes, lo cual es el primer reto para una ETL.
A pesar de los mitos habituales que rodean a la centralización de datos, debemos hacer frente a los hechos. Muchas operaciones de procesamiento de datos todavía exigen una manipulación más allá del almacén de datos. El procesamiento de los datos en el interior lleva mucho tiempo e implica recurrir a los recursos de la máquina. Tras haberlo practicado en entornos de nube, también puedo decir que la preparación es mucho más lenta que en local.
Pero procesar grandes archivos puede ser también un problema en una situación local. Te sugeriría que hicieras un pequeño test de prueba con Alteryx y Anatella.
Benchmark 1 Alteryx vs. Anatella: abrir un archive de 7,4 millones de líneas
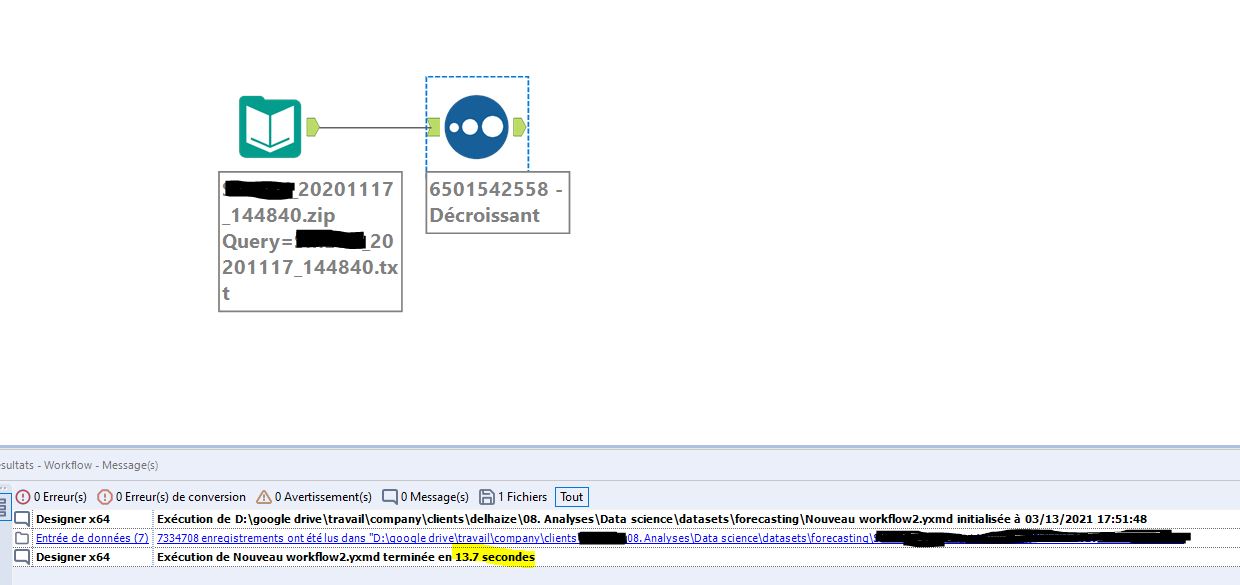
Para empezar, propongo una comparación entre los tiempos de procesamiento con un archivo de un tamaño razonable: un archivo plano de 7.3334 millones de líneas disponible como archivo zip (45 Mb).
Para comparar los tiempos de procesamiento realizaré una operación sencilla:
- Abrir el archivo zip
- Ordenar los datos de la primera columna en orden descendente
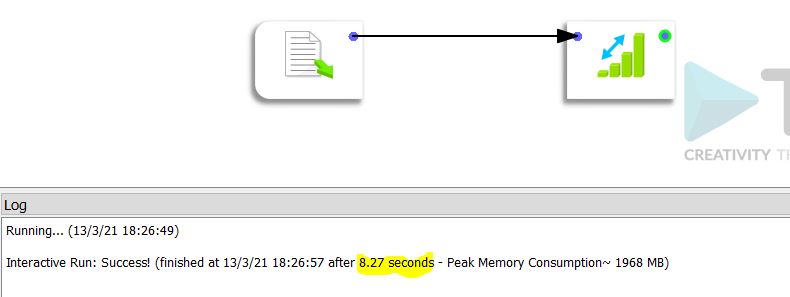
El tiempo de procesamiento con Anatella es de 8,27 segundos.
La misma operación usando Alteryx lleva 13,7 segundos.
Tal y como puedes ver, la diferencia con un archivo «pequeño» ya es de por sí notable. Anatella es un 39% más rápida que Alteryx, pero ambas soluciones se gestionan de manera local. No me imagino cuánto tardaría el procesamiento con una solución online como puede ser Dataiku.
Benchmark 2 Alteryx vs. Anatella: abrir un archive e 108 millones de líneas
Para el segundo test usaremos lo que podemos considerar un archivo extensivo. El archivo zip pesa 550MB y contiene un archivo plano de 108 millones de líneas con un peso de 9,88 GB. En esta ocasión es un tema serio.
El proceso seguirá siendo el mismo: abrir el archivo y ordenar los datos de la primera columna en orden descendente.
Los resultados son consistentes con la primera prueba.
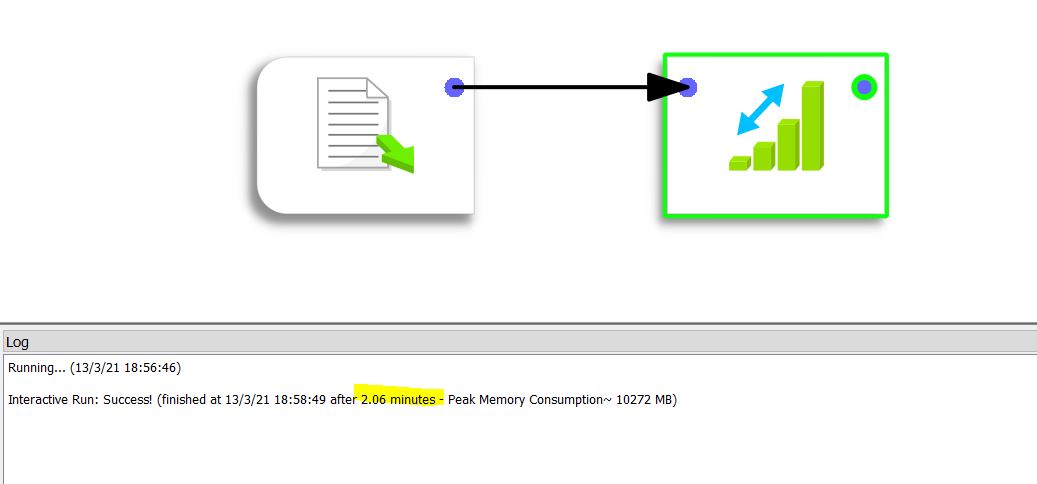
El procesamiento tarda 2,06 minutos (o 123 segundos con Anatella.
El mismo proceso con Alteryx tarda 202 segundos.
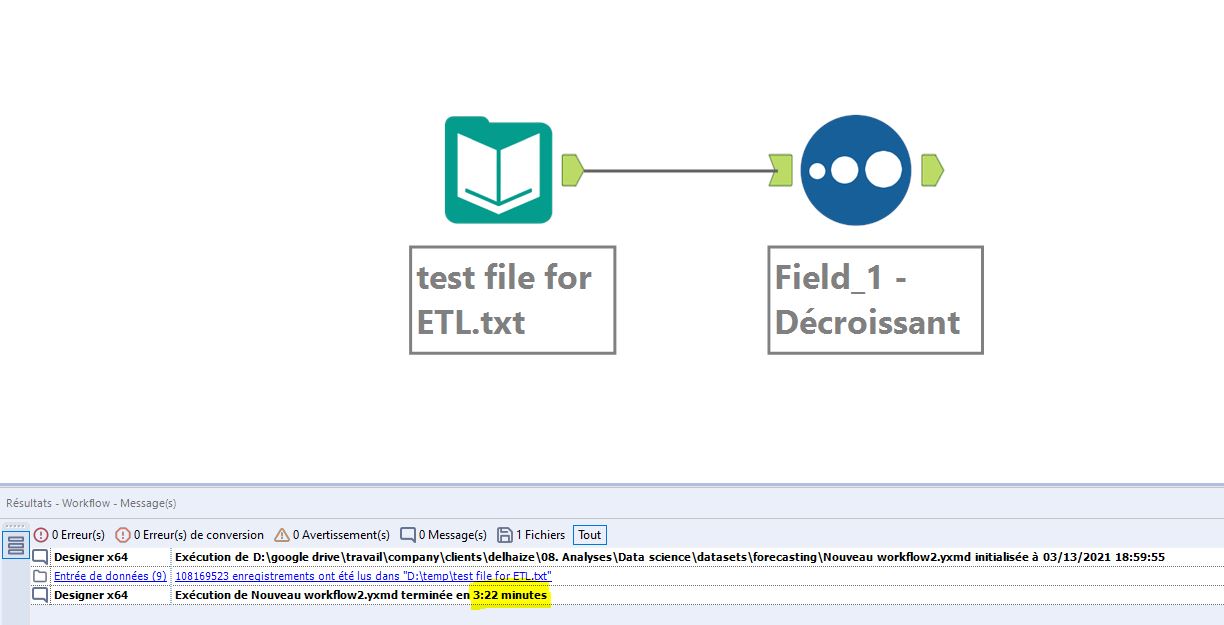
Lógicamente, la diferencia siempre es la misma entre Anatella y Alteryx: 39% a favor de Anatella.
Conclusión
Esta pequeña prueba ilustra el impacto que puede tener una ETL en la agilidad del proceso de preparación de datos. Las operaciones básicas (abrir y ordenar) pueden consumir una cantidad considerable de tiempo, el cual varía ampliamente según el ETL que se elija.
Por lo tanto, si quieres ganar agilidad hará falta que consideres cuidadosamente qué solución eliges. Creo que esta clase de gestión de grandes archivos debería realizarse de manera local ya que, cuando se hace en la nube, lo más seguro es que el proceso tarde y cueste más. Recuerda que las soluciones en la nube como por ejemplo Azure o AWS están diseñadas para que consumas tiempo de procesamiento, por lo que la ejecución del proceso no estará optimizada (económicamente hablando) tal y como lo está en una máquina física.

![Ilustración de nuestra publicación "Detectores de IA generativa gratuitos: ¿cuáles elegir? [Prueba completa 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)


