
Als we het over data preparation hebben, zien we dat een groot deel van de processen nog altijd offline verloopt, met archieven die uit relationele gegevensbanken worden getrokken. En wat de data engineers betreft die deze archieven behandelen, is het beter om een ETL te hebben die deze taak op zich neemt.
In het artikel van vandaag stel ik voor om het fascinerende onderwerp van grote bestanden te benaderen door 2 ETL’s te vergelijken die ik dagelijks gebruik: Alteryx en Anatella.
Professionele context: wanneer moeten grote bestanden worden verwerkt?
Zoals mijn vriend Marc Bouvet van DataLab ons eraan herinnerde in een video over dit onderwerp (zie hieronder), zijn archieven (zip, rar, …) het resultaat van extracties uit relationele databasesystemen. Met een flat file per tabel hebben we al snel te maken met bestanden van meerdere GB, wat een eerste uitdaging vormt voor een ETL.
Ondanks de gangbare mythen rond datacentralisatie moeten we de realiteit onder ogen zien. Veel processen van gegevensverwerking vereisen nog altijd verwerking buiten het data warehouse. De verwerking van gegevens binnenin is tijdrovend en vereist grote machinecapaciteit. Ik heb het in cloudomgevingen toegepast en kan bevestigen dat de voorbereiding daar veel trager verloopt dan lokaal.
Maar zelfs lokaal kan de verwerking van zeer grote archieven een probleem vormen. Laten we een kleine praktische test doen met Alteryx en Anatella.
Benchmark 1 Alteryx vs. Anatella: openen van een bestand van 7,4m regels
Om te beginnen stel ik voor de verwerkingstijden te vergelijken op een archief van redelijke omvang: een plat bestand van 7,334 miljoen regels dat beschikbaar is als .zip-archief (45 Mb).
Om de verwerkingstijden te vergelijken, hou ik het bij een eenvoudige bewerking:
- Openen van het gezipte archief
- Sortering in aflopende volgorde van de gegevens in de eerste kolom
De verwerkingstijd in Anatella is 8,27 seconden.
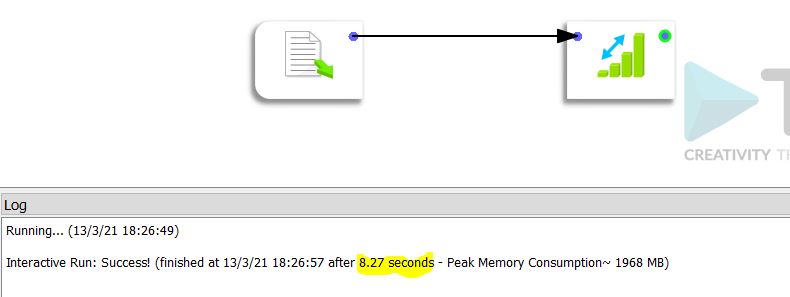
Dezelfde verwerking in Alteryx duurt 13,7 seconden.
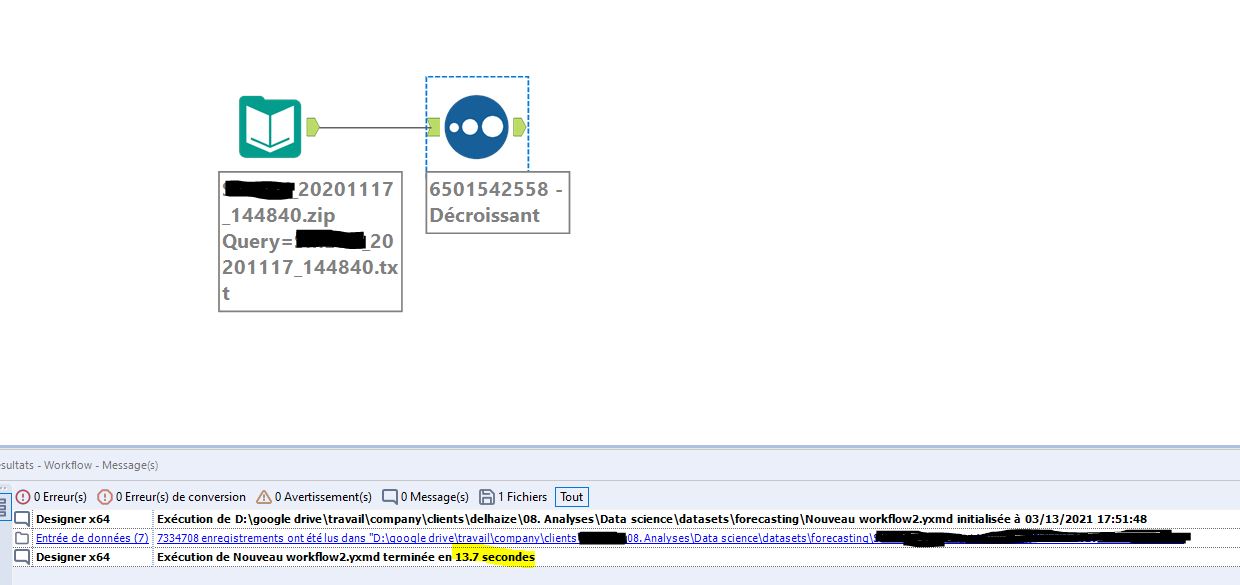
Zoals u merkt, is op een “klein” bestand het verschil al merkbaar. Anatella is 39% sneller dan Alteryx. Toch draaien beide oplossingen lokaal. Ik durf er niet aan te denken hoe lang de verwerking zou duren met online software als Dataiku.
Benchmark 2 Alteryx vs. Anatella: openen van een bestand van 108m regels
Voor de tweede test maken we gebruik van wat echt een groot archief kan worden genoemd. Het gezipte bestand is 550 MB groot en bevat een plat bestand van 108 miljoen regels van in totaal 9,88 GB. Dit is het grote werk.
We volgen hetzelfde proces: openen en naar beneden sorteren op de gegevens van de eerste kolom.
De resultaten komen overeen met de eerste test.
De verwerking duurt 2,06 minuten (of 123 seconden) op Anatella.
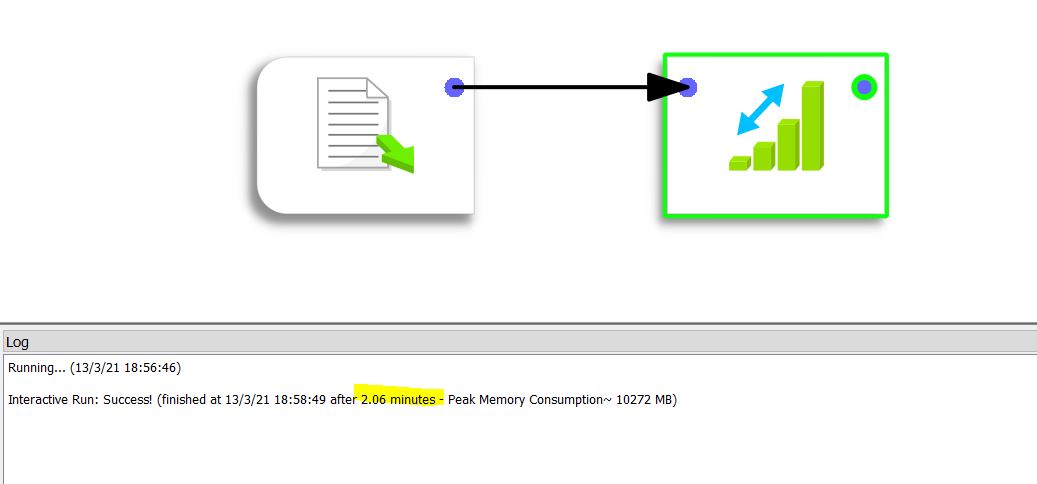
Dezelfde verwerking in Alteryx neemt 202 seconden in beslag.
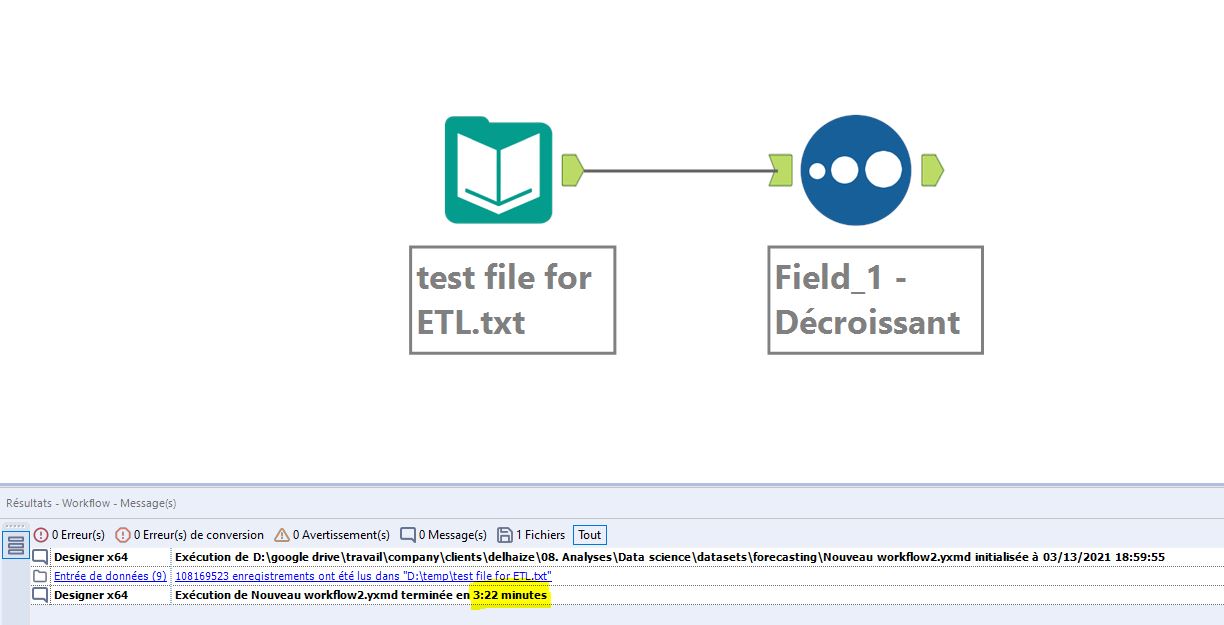
Logischerwijs is het verschil tussen Anatella en Alteryx hetzelfde: 39% in het voordeel van Anatella.
Conclusie
Deze kleine test illustreert de impact die een ETL kan hebben op de flexibiliteit van de data preparation. Zeer eenvoudige bewerkingen (openen – sorteren) kunnen een aanzienlijke hoeveelheid tijd in beslag nemen en de duur varieert sterk naargelang de gekozen ETL.
Als u aan flexibiliteit wilt winnen, moet u dus goed nadenken over de te kiezen oplossing. Wat mij betreft, moet deze afhandeling van grote bestanden lokaal gebeuren. Als het in de cloud gebeurt, zal de verwerking waarschijnlijk langer duren en meer kosten. Vergeet niet dat cloudoplossingen zoals Azure of AWS zijn ontworpen om u verwerkingstijd te laten verbruiken. De procesuitvoering wordt er (economisch gesproken) niet geoptimaliseerd zoals op een fysieke machine.

![Illustratie van onze post "Gratis generatieve AI-detectoren: welke kiezen? [Volledige test 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)



