
When it comes to data preparation, it is clear that a large part of the processes still takes place offline, with archives extracted from relational databases. And when these archives need to be manipulated by data engineers, it is essential to have an ETL that can handle the load.
In today’s article, I propose to tackle the fascinating subject of large files by comparing 2 ETL’s that I use daily: Alteryx and Anatella.
Business context: when are large files being handled?
As my friend Marc Bouvet from DaltaLab reminded us in a video dedicated to the subject, archives (zip, rar, …) are the result of extractions from relational database systems. One flat file per table quickly finds oneself manipulating multiple gigabyte files, which is the first challenge for an ETL.
Despite the common myths surrounding data centralization, we must face the facts. Many data processing operations still require manipulation outside the data warehouse. Processing data inside is time-consuming and involves machine resources. Having practiced it in cloud environments, I can also say that the preparation is much slower than locally.
But even in local environments, processing extensive archives can be a problem. I would suggest you do a small practical test with Alteryx and Anatella.
Benchmark 1 Alteryx vs. Anatella: opening a file of 7.4m lines
To start with, I propose to compare the processing times on a reasonable size archive: a flat-file of 7.334 million lines available as a .zip archive (45 Mb).
To compare the processing times, I will do a simple operation:
- opening the zipped archive
- sort the data in the first column in descending order
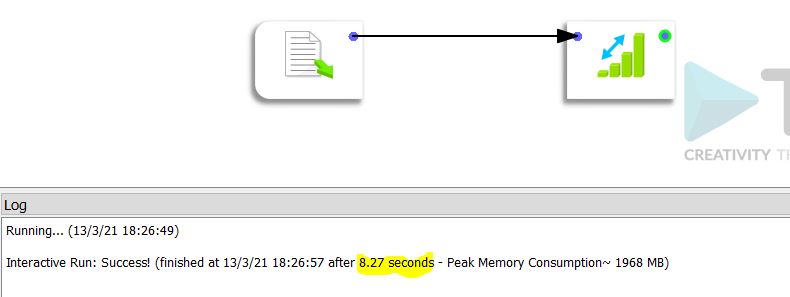
The processing time using Anatella is 8.27 seconds.
The same operation using Alteryx takes 13.7 seconds.
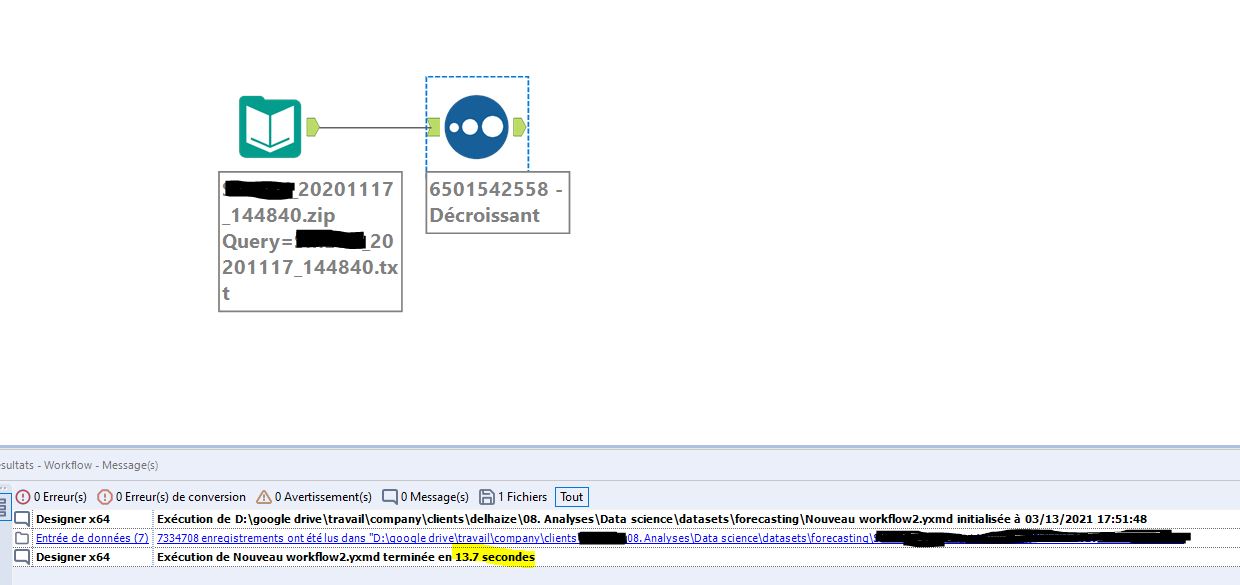
As you can see, on a “small” file, the difference is already noticeable. Anatella is 39% faster than Alteryx. However, both solutions are running locally. I can’t imagine what the processing would take with an online solution like Dataiku.
Benchmark 2 Alteryx vs. Anatella: opening a 108m lines file
For the 2nd test, we will use what can be called an extensive archive. The zipped file is 550 MB and contains a flat-file of 108 million lines that weighs 9.88 GB. This time it’s serious business.
The process is still the same: open and sort downwards on the data in the first column.
The results are consistent with the first test.
The processing takes 2.06 minutes (or 123 seconds) with Anatella
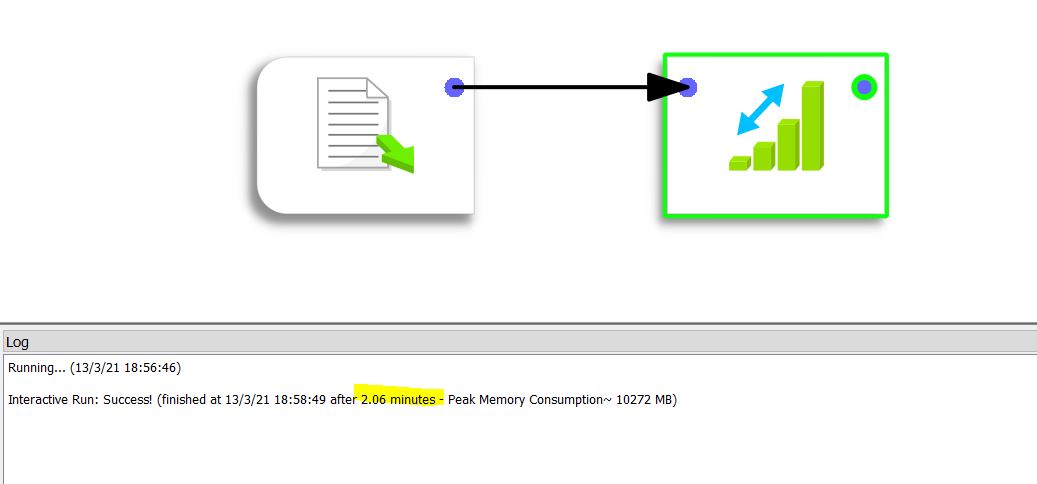
The same treatment with Alteryx takes 202 seconds.
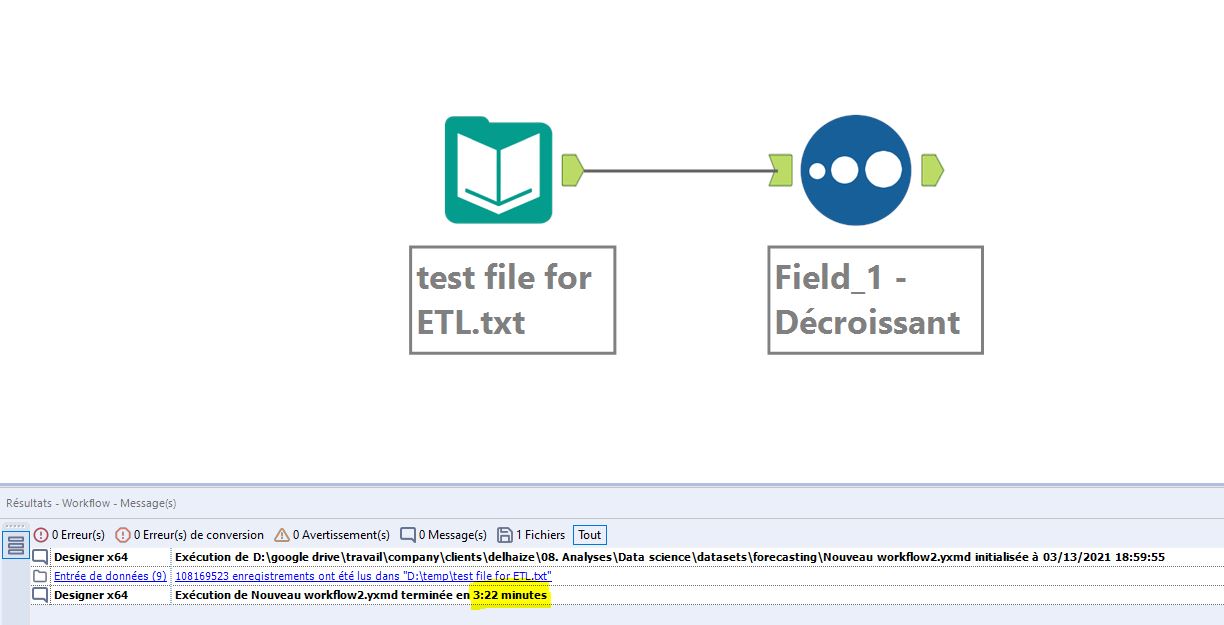
Logically the difference is always the same between Anatella and Alteryx: 39% in favor of Anatella.
Conclusion
This small test illustrates the impact that an ETL can have on the data preparation process’s agility. Elementary operations (opening – sorting) can consume a significant amount of time, which varies widely depending on the ETL chosen.
Therefore, if you want to gain agility, it is necessary to think carefully about the solution to adopt. I believe that this handling of large files should be done locally. When done in the cloud, the processing will probably take longer and cost more. Remember that cloud solutions such as Azure or AWS are designed to make you consume processing time. The process execution will not be optimized (economically speaking) as on a physical machine.




