
En matière de data preparation, force est de constater qu’une grande partie des processus se passent encore « offline », avec des archives extraites des bases de données relationnelles. Et quand il s’agit pour les data engineers de manipuler ces archives, mieux vaut avoir un ETL qui tienne la charge.
Dans l’article d’aujourd’hui je vous propose d’aborder le sujet passionnant des fichiers de grande taille en comparant 2 ETL’s que j’utilise au quotidien : Alteryx et Anatella.
Contexte métier : quand doit-on manipuler des fichiers de grande taille ?
Comme le rappelait mon ami Marc Bouvet de DaltaLab dans une vidéo consacrée au sujet (voir ci-dessous), les archives (zip, rar, …) sont le fruit des extractions de systèmes de bases de données relationnelles. Avec un fichier plat par table, on se retrouve vite à manipuler des fichiers de plusieurs Go ce qui constitue un premier défi pour un ETL.
Malgré les mythes couramment répandus autour de la centralisation des données, il faut bien se rendre à l’évidence. De nombreuses opérations de traitement des données nécessitent encore que les manipulations soient faites en dehors du data warehouse. Traiter les données à l’intérieur est consommateur de temps et de ressources machine. Pour l’avoir pratiquée dans des environnements cloud, je peux aussi affirmer que la préparation y est beaucoup plus lente qu’en local.
Mais même en local le traitement d’archives de très grande taille peut poser problème.Je vous propose de faire un petit test pratique avec Alteryx et Anatella.
Benchmark 1 Alteryx vs. Anatella : ouverture d’un fichier de 7,4m de lignes
Pour commencer en douceur je vous propose de comparer les temps de traitement sur une archive de taille raisonnable : un fichier plat de 7,334 millions de lignes disponible sous forme d’archive au format .zip (45 Mb).
Pour comparer les temps de traitement je vais me contenter d’une opération simple :
- ouverture de l’archive zippée
- tri par ordre descendant des données de la première colonne
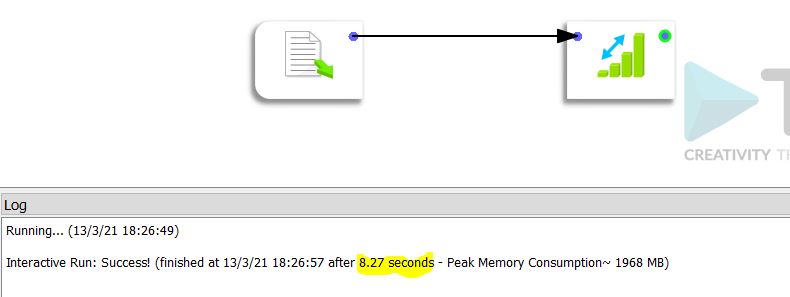
Le temps de traitement dans Anatella est de 8,27 secondes.
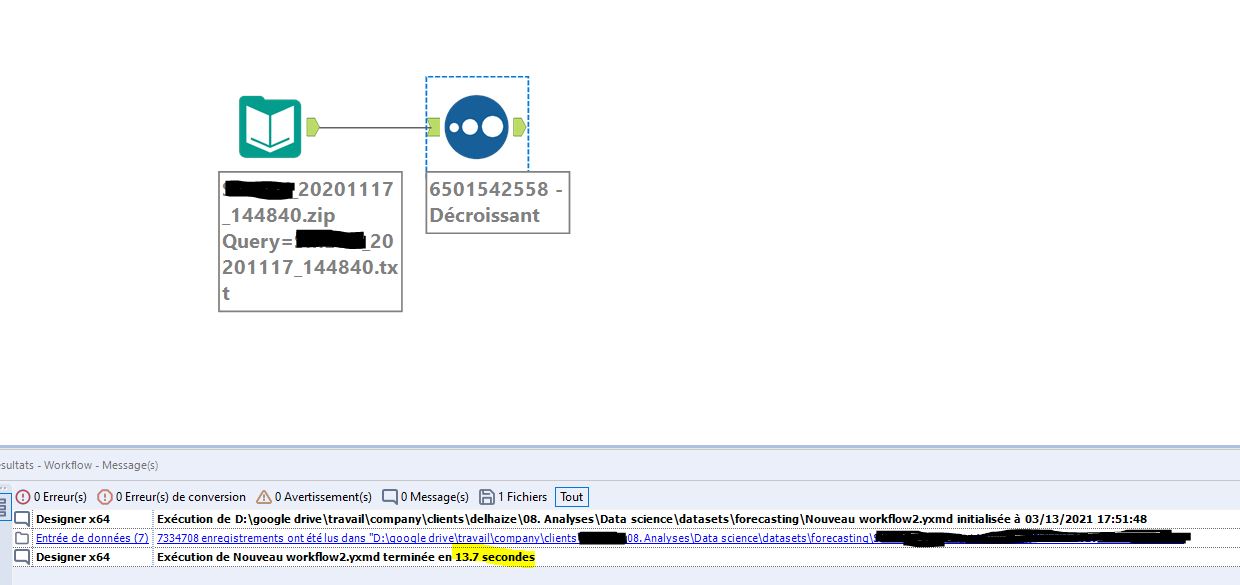
La même opération dans Alteryx prend 13,7 secondes.
Comme vous pouvez donc le constater, sur un « petit » fichier la différence est déjà sensible. Anatella est 39% plus rapide qu’Alteryx. Pourtant les deux solutions tournent en local. Je n’ose imaginer ce que le traitement prendrait avec une solution online du type Dataiku.
Benchmark 2 Alteryx vs. Anatella : ouverture d’un fichier de 108m de lignes
Pour le 2ème test nous allons utiliser ce que l’on peut vraiment appeler une archive de grande taille. Le fichier zippé fait 550 Mo et contient un fichier plat de 108 millions de lignes qui pèse 9,88 Go. Cette fois-ci c’est du sérieux.
Le processus est toujours le même : ouverture et tri descendant sur les données de la première colonne.
Les résultats sont conformes au premier test.
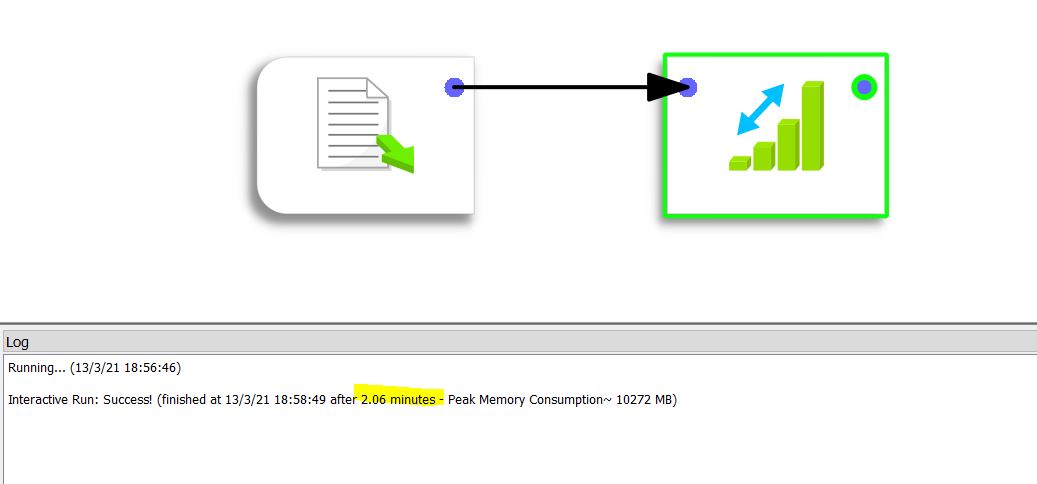
Le traitement prend 2,06 minutes (soit 123 secondes) sous Anatella
Le même traitement sous Alteryx prend 202 secondes.
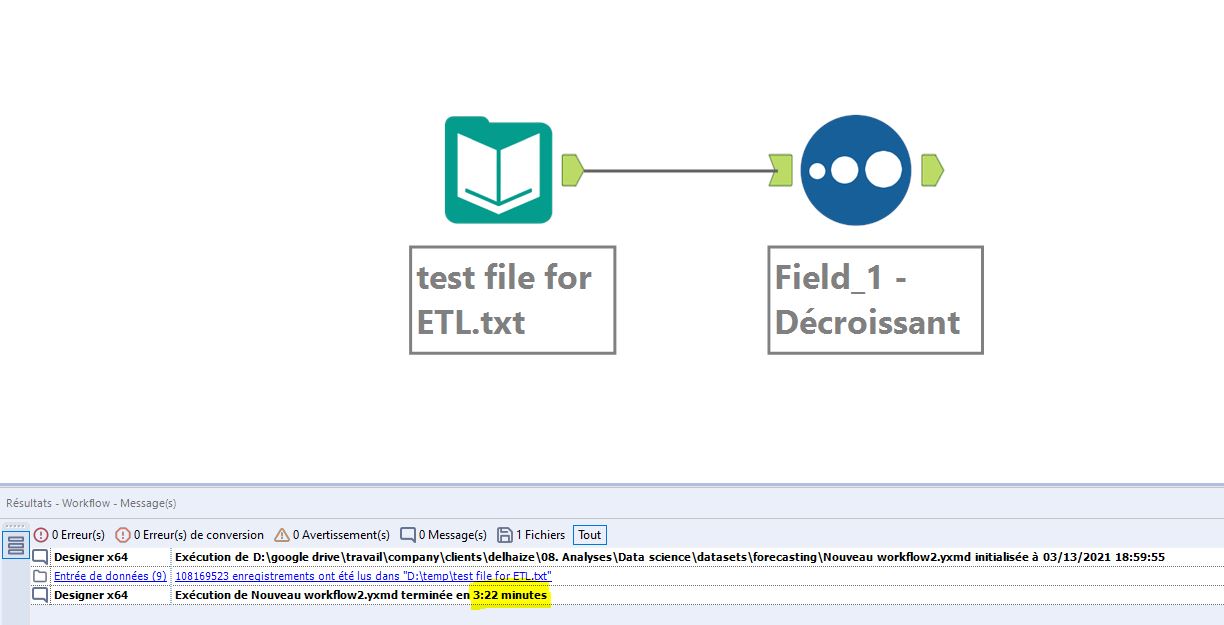
Logiquement la différence est toujours la même entre Anatella et Alteryx : 39% en faveur d’Anatella.
Conclusion
Ce petit test illustre donc concrètement l’impact que peut avoir un ETL sur l’agilité du processus de data preparation. Des opérations très simples (ouverture – tri) peuvent consommer un temps non négligeable et ce temps varie largement en fonction de l’ETL choisi.
Si vous souhaitez gagner en agilité il est donc nécessaire de bien s’interroger sur la solution à adopter. En ce qui me concerne, j’estime que cette manipulation de fichiers de grande taille devrait se faire en local. Réalisée dans le cloud le traitement prendra sans doute plus de temps et coûtera également plus. Rappelez-vous en effet que des solutions cloud telles qu’Azure ou AWS ont pour objectif de vous faire consommer du temps de processing. L’exécution de process n’y sera donc pas optimisée (économiquement parlant) comme sur une machine physique.





