
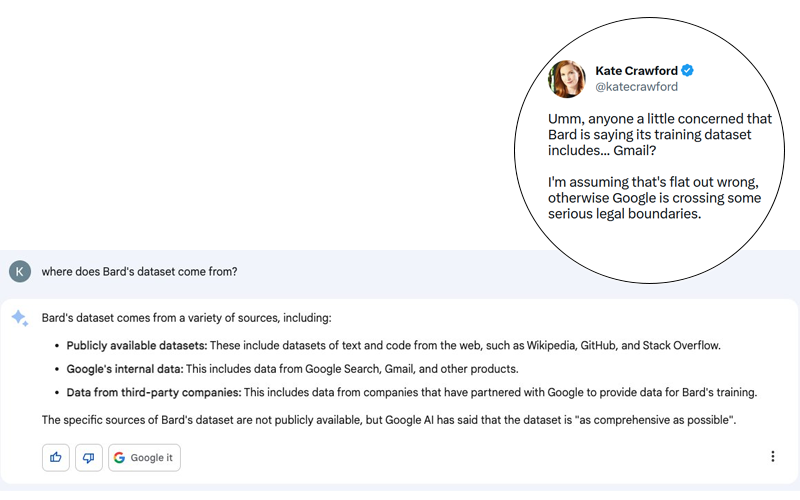
El escándalo es potencialmente enorme. Kate Crawford publicó en Twitter (ver la siguiente captura de pantalla) una respuesta de Bard, el agente conversacional de Google que utiliza una IA generativa, a una pregunta aparentemente inocua: «¿De dónde provienen los datos de Bard?».
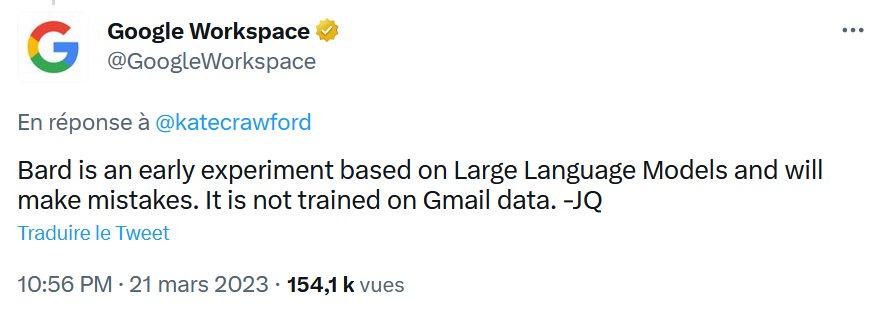
Aunque la respuesta de Bard puede ser una alucinación, es importante recordar que Google ha demostrado su habilidad para ignorar las normas más básicas de privacidad y protección de datos personales en el pasado. No me sorprendería que hubiese algo de verdad en esta historia, incluso si Google la negó relativamente rápido (ver tweet a continuación).
Recuerda que, hasta 2017, Google escaneó los correos electrónicos de sus usuarios para proponer anuncios contextuales. Google dejó de llevar a cabo esta práctica altamente intrusiva con tal de no ahuyentar a sus clientes de pago con las acciones legales, incluyendo el caso Matera V Google. Aun así, Google no ha dejado de analizar tus correos. Hoy en día todavía se desarrollan características en Gmail que utilizan datos estructurados contenidos en correos electrónicos recibidos a través de Gmail, como por ejemplo:
- Añadir eventos a tu calendario
- Escritura predictiva
- Proponer recordatorios
Lo que queda claro es que esta alucinación de Bard debería alertarnos de los posibles peligros de tales avances tecnológicos. Lo que me asusta no es el progreso en sí mismo, sino los seres humanos que hay detrás de ese progreso y sus decisiones. En el caso de las IA generativas y de las LLM que constituyen sus bases, lo que más me preocupa son los datos de entrenamiento, especialmente cuando la explicación ofrecida por OpenAI en la presentación de GPT-4 fueron de todos menos trasparentes en cuanto a los datos utilizados para entrenar este nuevo modelo.

Los peligros de utilizar agentes conversacionales
Los peligros se relacionan principalmente con violaciones de las leyes vigentes en cuanto a la privacidad de la correspondencia, lo que ya fue en su momento el centro del caso Matera vs. Google. Sorprendentemente, el acuerdo amistoso entre las partes fue rechazado por los jueces ya que las medidas propuestas por Google eran insuficientes para garantizar que las causas del problema se corrigiesen.
Esta intrusión en la privacidad de la correspondencia supone un riesgo todavía mayor para las empresas por el respeto a la privacidad profesional. ¿Te imaginas por un segundo que tus conversaciones confidenciales (potencialmente protegidas por un NDA) se utilizasen como base de entrenamiento para una inteligencia artificial? Algo más adelante en este artículo, hablo de un ejemplo ampliamente conocido.
Imagina por un momento este escenario. Un banco de inversiones está trabajando en un proyecto para comprar la empresa A de la empresa B. Estos intercambios sirven como base de entrenamiento para Bard. A 10.000 kilómetros de distancia, un analista le pide a Bard un resumen de la situación relacionada con la empresa A y Bard responde que A podría ser comprada a B. ¿De verdad es un escenario tan utópico?
Lo que más me asusta en esta historia es que los datos confidenciales están integrados en las respuestas de un algoritmo cuyo funcionamiento todavía se escapa a sus diseñadores. Tal y como expliqué aquí, el valor añadido de mi agencia de investigaciones de mercado se basa en la generación de los llamados datos «primarios». Estos datos se recogen ad hoc según las necesidades de los clientes y estos clientes pagan por ellos, así que sería incomprensible que los datos que intercambiamos a diario por correo electrónico pudiesen robarse y ser transferidos a terceros.
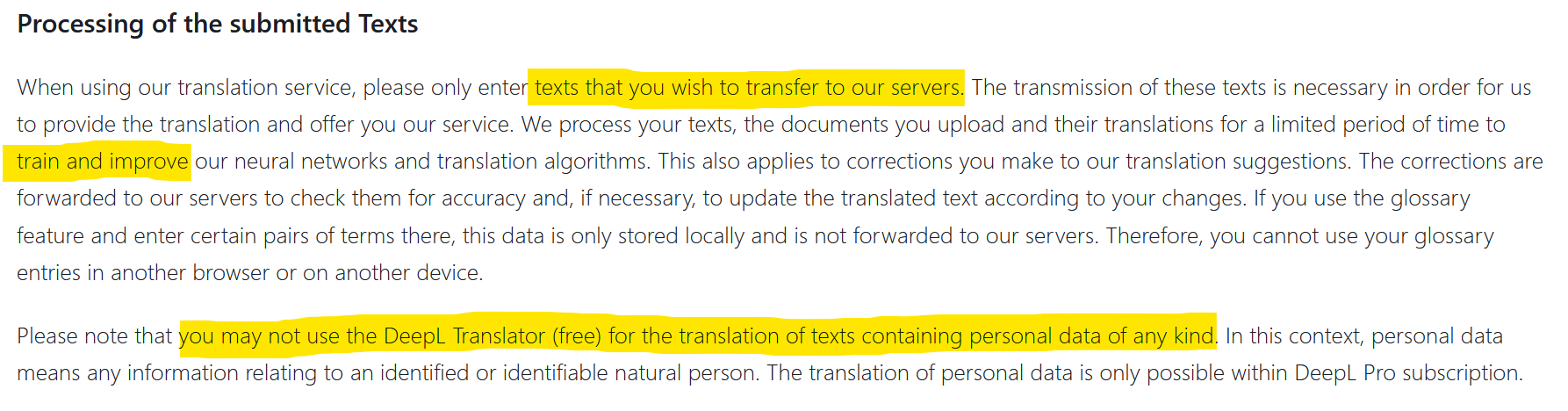
Hasta ahora, los datos de las empresas que se filtraban al mundo exterior eran frutos de hackeos, pero en ocasiones también era la negligencia lo que exponía datos al exterior. El uso de DeepL, por ejemplo, está sujeto a la autorización de la transferencia y difusión de la información que transmites (ver captura de pantalla anterior). Los datos confidenciales pueden terminar así en Internet, algo que ya le pasó a Statoil en 2017 tras utilizar translate.com. Una investigación llevada a cabo por el medio noruego NRK reveló que en esta página de traducción había una abundancia de datos privados y altamente confidenciales. ¿Qué pasará cuando miles de empresas utilicen los plugins de ChatGPT? ¿Cuál será el nivel de privacidad? ¿Dónde irá ese intercambio de datos, y se integrará en conjuntos de datos de entrenamiento?

En conclusión

En conclusión, me gustaría que el lector recordarse que los primeros usuarios de las nuevas herramientas tecnológicas son también conejillos de indias potenciales. En el caso de ChatGPT, el número masivo de usuarios adquiridos en sus primeros días fue una poderosa palanca para OpenAI, pero la opacidad de este producto gratuito me lleva a creer que quizás veamos algunas sorpresas en los próximos meses. Es una perspectiva especialmente realista si tenemos en cuenta que los diseñadores de GPT no comprenden cómo funciona su creación y están (y con razón) impresionados con los resultados.




