
Le scandale est potentiellement énorme. Kate Crawford a publié sur Twitter (voir capture d’écran ci-dessous) une réponse faite par Bard, l’agent conversationnel de Google utilisant une IA générative, à une question pourtant anodine : « D’où viennent les données de Bard ? ».
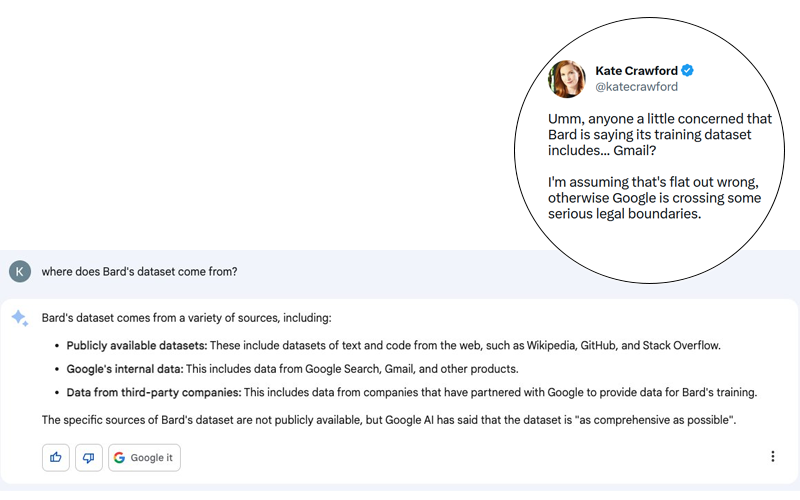
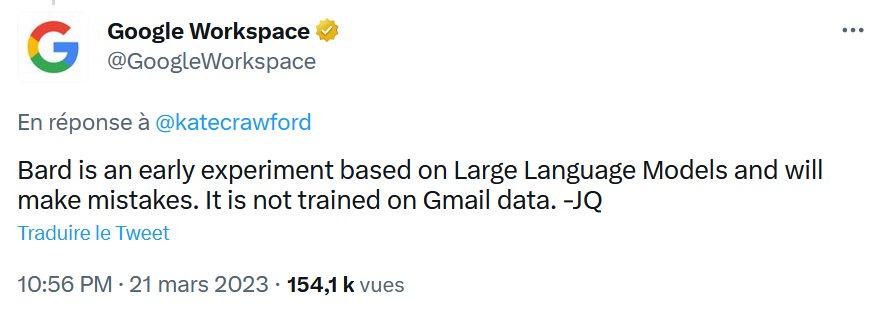
Bien que la réponse de Bard puisse relever d’une hallucination, je pense qu’il faut garder à l’esprit que Google a démontré, par le passé, sa capacité à s’affranchir des règles les plus élémentaires en matière de respect de la vie privée et des données à caractère personnel. Je ne serais donc pas étonné qu’il y ait une part de vrai dans cette histoire même si elle a été démentie par Google relativement rapidement (voir tweet ci-dessous).
Rappelons-nous en effet que jusqu’en 2017 Google scannait les emails de ses utilisateurs pour leur proposer des publicités contextuelles. Google avait arrêté cette pratique hautement intrusive pour ne pas effrayer ses clients payants … et à cause d’actions en justice, notamment le cas Matera V. Google. Néanmoins, Google n’a pas arrêté pour autant d’analyser vos emails. Des fonctionnalités sont aujourd’hui encore déployées dans gmail qui utilisent les données non structurées contenues dans les emails reçus via Gmail :
- ajout d’événements dans votre calendrier
- frappe prédictive
- proposition de rappels
Ce qui est clair, c’est que cette hallucination de Bard doit nous alerter sur les dangers possibles que représentent les avancées technologiques de ce type. Ce qui me fait peur n’est pas tant le progrès lui-même, mais plutôt les êtres humains derrière ce progrès et leurs choix. Dans le cas de l’IA générative et des LLM qui en constituent les fondements, ce sont les données d’entraînement qui m’inquiètent le plus. D’autant que les explications données par OpenAI à la sortie de GPT-4 sont tout sauf transparentes sur les données utilisées pour entraîner ce nouveau modèle.

Risques liés à l’utilisation des agents conversationnels
Les risques relèvent principalement des infractions sur les lois qui régissent le secret de la correspondance. C’était du reste déjà le cœur du procès Matera vs. Google. Chose assez extraordinaire, l’accord amiable entre les parties avait d’ailleurs été rejeté par les juges au motif que les mesures proposées par Google n’étaient pas suffisantes pour garantir que les causes du problème seraient corrigées.
Cette intrusion dans le secret des correspondances fait peser un risque bien plus grand encore pour les entreprises: le respect du secret des affaires. Pouvez-vous une seconde imaginer que vos conversations confidentielles (et potentiellement protégées par un NDA) puissent servir de corpus d’entraînement à une intelligence artificielle ? Un peu plus loin dans cet article je parle d’un exemple assez connu.
Imaginez un instant ce scénario. Une banque d’affaires travaille sur un projet de rachat d’une entreprise A par une entreprise B. Les échanges servent de base d’entraînement à Bard. A 10.000 km de là un analyste demande à Bard un résumé de la situation sur l’entreprise A. Bard répond que A pourrait être rachetée par B. Ce scénario est-il si utopique que cela ?
Ce qui me fait le plus peur dans cette histoire c’est que des données confidentielles se retrouvent intégrées dans les réponses d’un algorithme dont le fonctionnement échappe encore à ses concepteurs. Comme je l’ai expliqué ici, la valeur ajoutée de mon cabinet d’études de marché repose sur la génération de données dites « primaires ». Ce sont des données qui sont collectée ad hoc pour les besoins d’un client et pour lesquelles les clients payent. Il serait incompréhensible que ces données, sur lesquelles nous échangeons quotidiennement par email, soient volées et puissent être communiquées à des tiers.
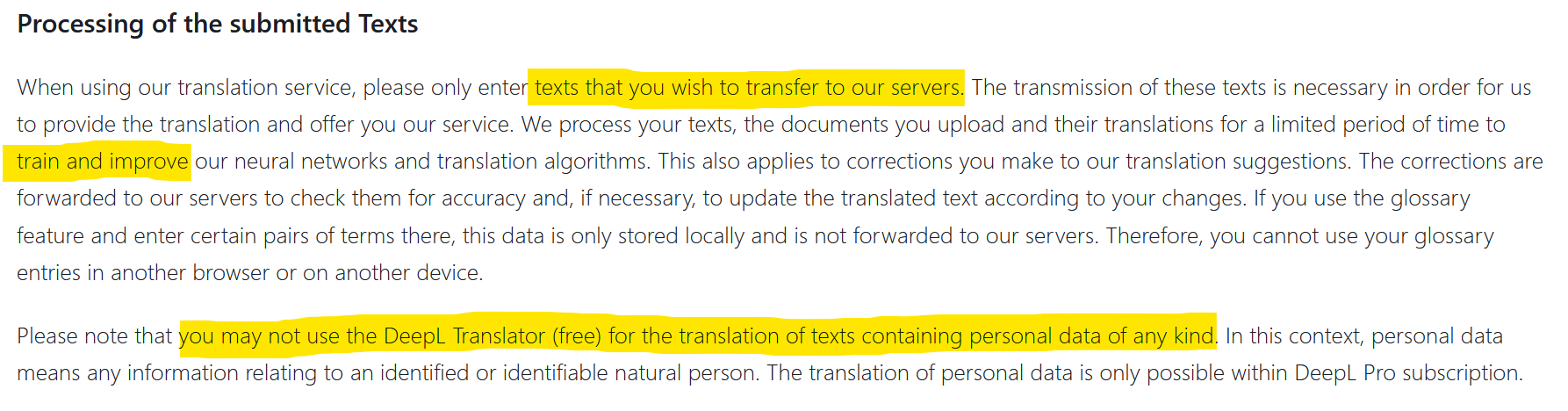
Jusqu’à maintenant, les données des entreprises qui fuitaient vers l’extérieur venaient d’un hacking. Mais parfois c’est aussi la négligence qui exposait des données vers l’extérieur. L’utilisation de deepl par exemple est soumise à l’autorisation de transfert et de diffusion des informations que vous transmettez (voir capture d’écran ci-dessus). Des données confidentielles peuvent alors se retrouver sur internet. C’est ce qui est arrivé à Statoil en 2017 après l’utilisation de translate.com. Une enquête du média norvégien NRK avait d’ailleurs révélé que les données privées et ultra confidentielles étaient légion sur ce site de traduction. Que se passera-t-il lorsque des milliers d’entreprises utiliseront les plugins de ChatGPT ? Quel sera le niveau de confidentialité ? Où les données échangées s’en iront-elles et seront-elles intégrées aux datasets d’entraînement ?

En conclusion

En guise de conclusion j’aimerais que le lecteur se souvienne que les premiers utilisateurs des nouveaux outils technologiques servent potentiellement de cobayes. Dans le cas de ChatGPT, le nombre massif d’utilisateurs acquis dès les premiers jours a été un levier puissant pour OpenAI. Mais l’opacité de ce produit gratuit me laisse à penser que nous pourrions bien avoir quelques surprises dans les mois qui viennent. Ceci est d’autant plus réaliste que les concepteurs de GPT ne comprennent pas vraiment comment leur création fonctionne et sont (à juste titre) impressionnés par les résultats obtenus.





