
Lo scandalo è potenzialmente enorme. Kate Crawford ha pubblicato su Twitter (vedi screenshot sotto) una risposta di Bard, l’agente conversazionale di Google che utilizza l’IA generativa, a una domanda apparentemente innocua: “Da dove vengono i dati di Bard?”.
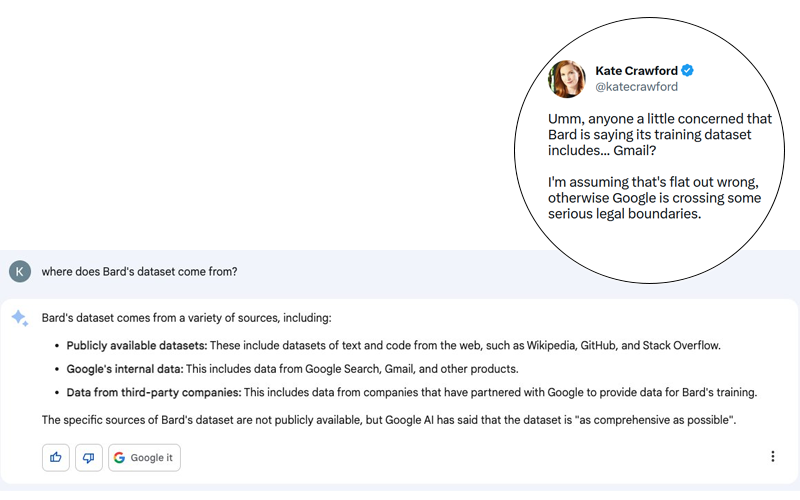
Anche se la risposta di Bard potrebbe essere un’allucinazione, è importante ricordare che Google ha dimostrato in passato la sua capacità di non rispettare le regole più elementari della privacy e della protezione dei dati personali. Non mi stupirei se ci fosse del vero in questa storia, anche se è stata smentita da Google in tempi relativamente brevi (vedi tweet sotto).
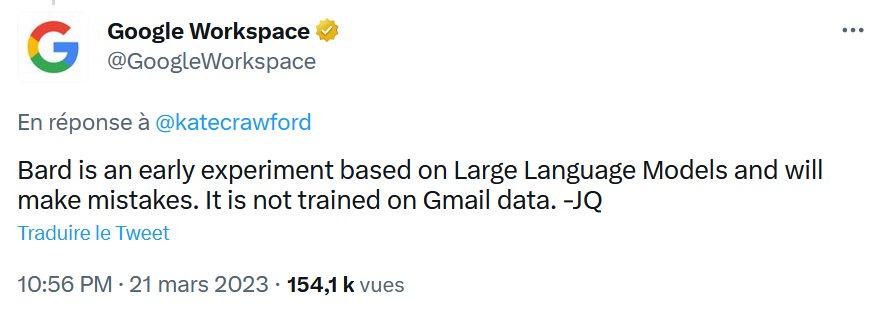
Ricordiamo che fino al 2017 Google scansionava le email dei suoi utenti per proporre annunci contestuali. Google ha interrotto questa pratica altamente intrusiva per non spaventare i suoi clienti paganti a causa di azioni legali, tra cui il caso Matera V Google. Tuttavia, Google non ha smesso di analizzare le e-mail degli utenti. Ancora oggi in Gmail sono presenti funzioni che utilizzano i dati non strutturati contenuti nelle e-mail ricevute tramite Gmail:
- aggiungere eventi al calendario
- digitazione predittiva
- proporre promemoria
Ciò che è chiaro è che questa allucinazione di Bard dovrebbe metterci in guardia dai possibili pericoli di questi progressi tecnologici. Ciò che mi spaventa non è il progresso in sé, ma gli esseri umani che vi stanno dietro e le loro scelte. Nel caso dell’IA generativa e dei LLM che ne costituiscono le fondamenta, sono i dati di training a preoccuparmi di più. Soprattutto perché le spiegazioni fornite da OpenAI in occasione del rilascio di GPT-4 sono tutt’altro che trasparenti sui dati utilizzati per fare training su questo nuovo modello.

Risks of using conversational agents
I rischi sono principalmente legati alla violazione delle leggi che regolano la segretezza della corrispondenza. Questo aspetto è già stato al centro del caso Matera vs. Google. In via del tutto straordinaria, l’accordo amichevole tra le parti è stato respinto dai giudici perché le misure proposte da Google non erano sufficienti a garantire la correzione delle cause del problema.
Questa intrusione nella segretezza della corrispondenza comporta un rischio ancora maggiore per le aziende: il rispetto del segreto aziendale. Riuscite a immaginare per un attimo che le vostre conversazioni riservate (potenzialmente protette da un NDA) possano essere utilizzate come corpus di training per l’intelligenza artificiale? Poco più avanti in questo articolo, parlo di un esempio ben noto.
Immaginiamo per un attimo questo scenario. Una banca d’investimento sta lavorando a un progetto di acquisizione dell’azienda A da parte dell’azienda B. Gli scambi servono a Bard come terreno di formazione. A 10.000 km di distanza, un analista chiede a Bard un riassunto della situazione dell’azienda A. Bard risponde che A potrebbe essere rilevata da B. Questo scenario è così utopico?
Ciò che mi spaventa di più in questa storia è che i dati riservati sono integrati nelle risposte di un algoritmo il cui funzionamento sfugge ancora ai suoi progettisti. Come ho spiegato qui, il valore aggiunto della mia società di ricerche di mercato si basa sulla generazione di dati cosiddetti “primari”. Si tratta di dati raccolti ad hoc per le esigenze dei clienti e per i quali i clienti pagano. Sarebbe incomprensibile che i dati che ci scambiamo quotidianamente via e-mail possano essere rubati e ceduti a terzi.
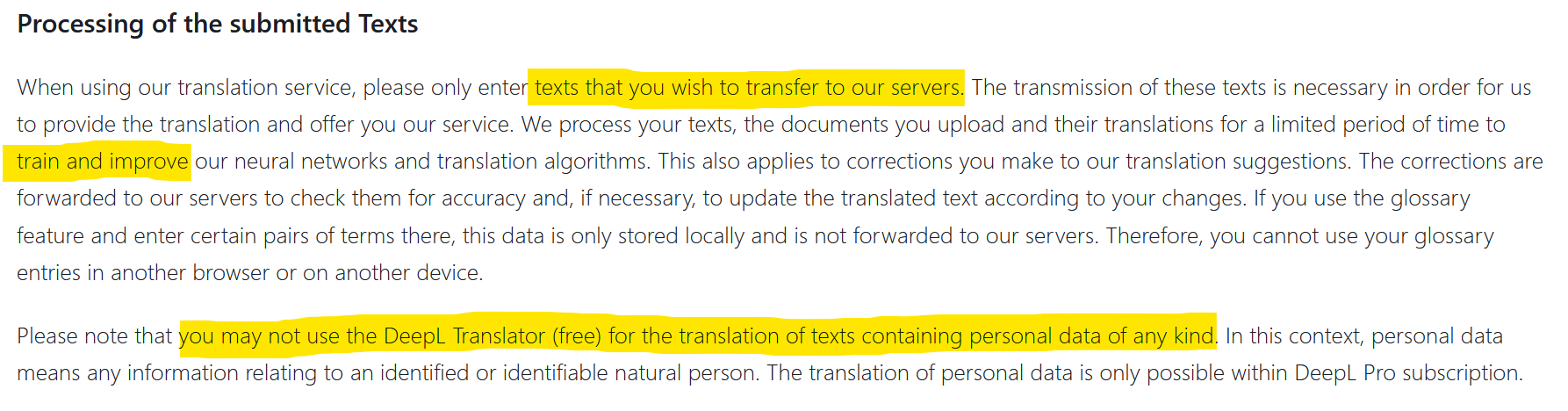
Finora, i dati delle aziende che trapelavano all’esterno provenivano da hacking. Ma a volte è stata anche la negligenza a esporre i dati al mondo esterno. L’utilizzo di DeepL, ad esempio, è soggetto all’autorizzazione di trasferimento e diffusione delle informazioni trasmesse (vedi schermata sopra). I dati riservati possono quindi finire su Internet. Questo è ciò che è successo a Statoil nel 2017 dopo aver utilizzato translate.com. Un’indagine condotta dal media norvegese NRK ha rivelato che dati privati e altamente confidenziali erano presenti in abbondanza su questo sito di traduzione. Cosa succederà quando migliaia di aziende utilizzeranno i plugin di chatGPT? Quale sarà il livello di privacy? Dove andranno a finire i dati scambiati e saranno integrati nei dataset di formazione?

In conclusione

In conclusione, vorrei che il lettore ricordasse che i primi utenti di nuovi strumenti tecnologici sono potenzialmente le cavie. Nel caso di chatGPT, l’enorme numero di utenti acquisiti nei primi giorni è stata una potente leva per OpenAI. Ma l’opacità di questo prodotto gratuito mi fa pensare che nei prossimi mesi potremmo avere delle sorprese. Ciò è particolarmente realistico dal momento che i progettisti di GPT non capiscono come funziona la loro creazione e sono (giustamente) impressionati dai risultati.
![Illustrazione del nostro articolo "Rilevatori di IA generativa gratuiti: quali scegliere? [Test completo 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)



