
Der Skandal ist potenziell riesig. Kate Crawford postete auf Twitter (siehe Screenshot unten) eine Antwort von Bard, Googles konversationellem Agenten, der generative KI nutzt, auf die scheinbar harmlose Frage “Woher kommen die Daten von Bard?”
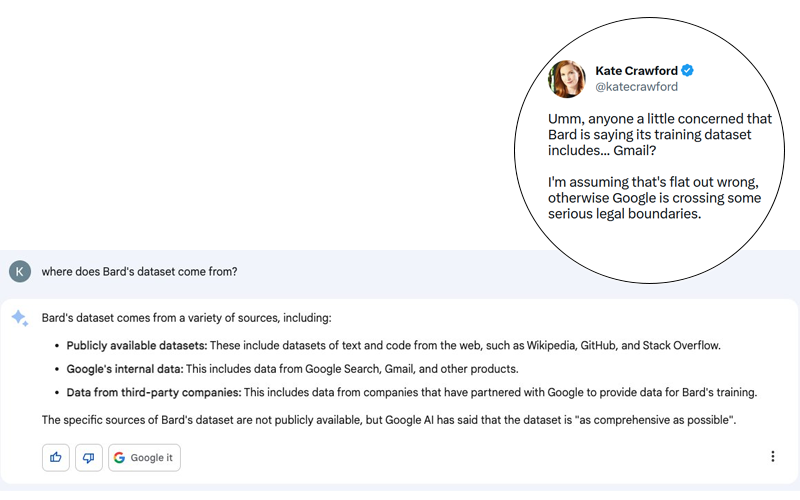
Auch wenn es sich bei der Antwort von Bard um eine Täuschung handeln könnte, darf man nicht vergessen, dass Google in der Vergangenheit bewiesen hat, dass das Unternehmen dazu in der Lage ist, die grundlegendsten Regeln der Privatsphäre und des Schutzes persönlicher Daten zu missachten. Es würde mich nicht überraschen, wenn an dieser Geschichte etwas Wahres dran wäre, auch wenn sie von Google relativ schnell dementiert wurde (siehe Tweet unten).
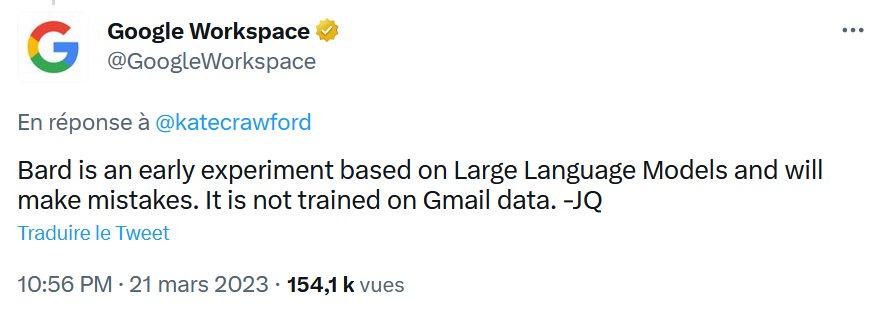
Erinnern Sie sich, dass Google bis 2017 die E-Mails seiner Nutzer scannte, um kontextbezogene Anzeigen vorzuschlagen. Google stoppte diese äußerst aufdringliche Praxis, um die zahlenden Kunden nicht zu verschrecken, da es zu Klagen kam, u.a. im Fall Matera gegen Google. Dennoch hält Google an der Analyse von E-Mails fest. Auch heute noch werden in Google Mail Funktionen eingesetzt, die unstrukturierte Daten aus den über Google Mail empfangenen E-Mails nutzen:
- Hinzufügen von Ereignissen zu Ihrem Kalender
- Prädiktives Tippen
- Vorschlagen von Erinnerungen
Klar ist, dass diese Antwort in Bezug auf Bard uns vor den möglichen Gefahren eines solchen technologischen Fortschritts warnen sollte. Was mir Angst macht, ist nicht der Fortschritt selbst, sondern die Menschen, die hinter diesem Fortschritt stehen, und ihre Entscheidungen. Im Falle der generativen KI und der LLMs, die deren Grundlage bilden, machen mir die Trainingsdaten die größten Sorgen. Zumal die Erklärungen, die OpenAI bei der Veröffentlichung von GPT-4 abgegeben hat, alles andere als transparent sind, was die zum Training dieses neuen Modells verwendeten Daten angeht.

Risiken bei der Verwendung von konversationellen Agenten
Die Risiken stehen hauptsächlich im Zusammenhang mit Verstößen gegen die Gesetze zur Wahrung des Briefgeheimnisses. Dies stand bereits im Mittelpunkt des Falles Matera vs. Google. Außergewöhnlicherweise wurde die gütliche Einigung zwischen den Parteien von den Richtern abgelehnt, weil die von Google vorgeschlagenen Maßnahmen nicht ausreichten, um zu gewährleisten, dass die Ursachen des Problems beseitigt werden.
Dieser Verstoß gegen das Briefgeheimnis birgt für Unternehmen ein noch größeres Risiko: die Wahrung des Geschäftsgeheimnisses. Können Sie sich auch nur eine Sekunde lang vorstellen, dass Ihre vertraulichen Gespräche (die möglicherweise durch ein NDA geschützt sind) als Trainingskorpus für künstliche Intelligenz verwendet werden könnten? Etwas weiter in diesem Artikel spreche ich über ein bekanntes Beispiel.
Stellen Sie sich für einen Moment folgendes Szenario vor. Eine Investmentbank arbeitet an einem Projekt zum Kauf von Unternehmen A von Unternehmen B. Die Börsen dienen als Trainingsgelände für Bard. 10.000 km entfernt bittet ein Analyst Bard um eine Zusammenfassung der Situation von Unternehmen A. Bard antwortet, dass A von B übernommen werden könnte. Ist dieses Szenario so utopisch?
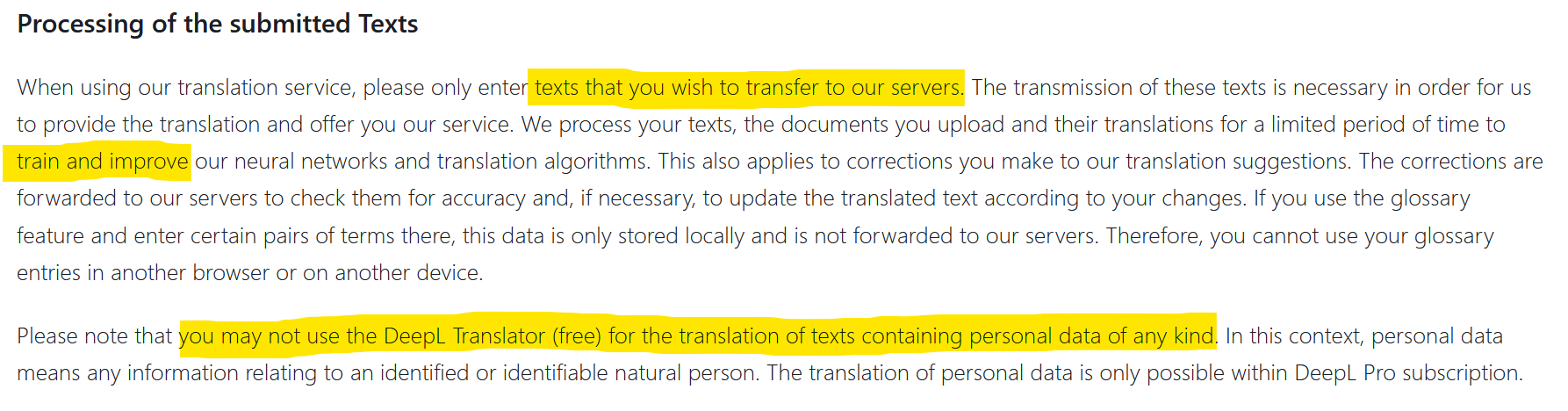
Was mich an dieser Meldung am meisten erschreckt, ist, dass vertrauliche Daten in die Antworten eines Algorithmus integriert werden, dessen Funktionsweise den Entwicklern noch immer nicht klar ist. Wie ich hier erklärt habe, basiert der Mehrwert meines Marktforschungsunternehmens auf der Generierung von sogenannten “primären” Daten. Diese Daten werden ad hoc für die Bedürfnisse der Kunden erhoben und für die die Kunden bezahlen. Es wäre unverständlich, dass die Daten, die wir täglich per E-Mail austauschen, gestohlen und an Dritte weitergegeben werden könnten.
Bisher waren die Daten der Unternehmen, die an die Außenwelt gelangten, das Ergebnis von Hackerangriffen. Aber manchmal war auch Fahrlässigkeit im Spiel, wodurch Daten an die Außenwelt gelangten. Die Nutzung von DeepL beispielsweise unterliegt der Genehmigung der Übertragung und Verbreitung der von Ihnen übermittelten Informationen (siehe Screenshot oben). Vertrauliche Daten können dann im Internet landen. Dies geschah 2017 bei Statoil, nachdem die Mitarbeiter des Unternehmens translate.com benutzt hatten. Eine Untersuchung der norwegischen Medien NRK ergab, dass private und höchst vertrauliche Daten in Hülle und Fülle auf dieser Übersetzungswebsite zu finden waren. Was wird passieren, wenn Tausende von Unternehmen chatGPT-Plugins verwenden? Wie wird es um den Datenschutz bestellt sein? Wohin wird der Datenaustausch gehen, und werden die Daten in die Trainingsdatensätze integriert werden?

Fazit

Abschließend möchte ich den Leser daran erinnern, dass die ersten Nutzer neuer technologischer Werkzeuge potenziell die Versuchskaninchen sind. Im Fall von chatGPT war die massive Anzahl von Nutzern, die in den ersten Tagen gewonnen wurde, ein starker Hebel für OpenAI. Aber die Undurchsichtigkeit dieses kostenlosen Produkts lässt mich glauben, dass wir in den kommenden Monaten einige Überraschungen erleben könnten. Dies ist besonders realistisch, da die Entwickler von GPT nicht verstehen, wie ihre Entwicklung funktioniert und (zu Recht) von den Ergebnissen beeindruckt sind.

![Illustration unseres Beitrags "Kostenlose generative KI-Detektoren: Welche soll man wählen? [Vollständiger Test 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)



