
![ChatGPT: its answers are very similar [exclusive research]](/blog/app/uploads/chatGPT-brain-cerveau.jpg)
ChatGPT has a surprising ability. If you press the “regenerate response” button, ChatGPT will propose a brand-new response. At least on the surface. Because, in reality, the results published in this article show that ChatGPT repeats itself a lot. So much so that even answers to different questions look the same! This confirms the first research we published on the subject. Today we further show that the less precise your query to ChatGPT is, the more similar the answers will be. The similarity rate reaches 77.91% on average.
The data was prepared and enriched for this project with Timi’s ETL solution: Anatella. The visualization of the data was carried out with Tableau.
What can be learned from this research on the functioning of ChatGPT
- 1words: the average length of the 1000 texts produced by ChatGPT based on a target length of 500 words.
- 1%: the respect by ChatGPT of the data given in terms of text length
- Texts produced by ChatGPT with minimal instructions are significantly more similar (77.91%) than when more detailed instructions are given (73.17%)
- When the instructions given to ChatGPT are little detailed, answers to different questions are more similar (65.44%) than when detailed instructions are given (60.93%)
- Regardless of the question, ChatGPT shows a surprising ability to produce similar answers when you ask it to regenerate its answer (between 76.02% and 80.04% average similarity depending on the question). So, expect to receive only partially different answers from one regeneration to the next.
Methodology
I asked ChatGPT 20 questions. For each question, I asked it to regenerate its answer 50 times, corresponding to 50 iterations. I thus analyzed 1000 answers.
Here is an example.

To regenerate an answer, press the button below:
The questions were all identical in the form:
Write me an SEO-optimized article of 500 words on “KEYWORD”
Only the “keyword” differed from one series to another. The list of keywords is available at the end of this article.
Ultimately, 20 questions x 50 iterations = 1000 texts were analyzed.
Once the data was extracted from ChatGPT, it was prepared with ETL software. For the data preparation, I exclusively use Anatella, the best in its category (see here my advice for choosing an ETL). The data visualization was carried out using Tableau.
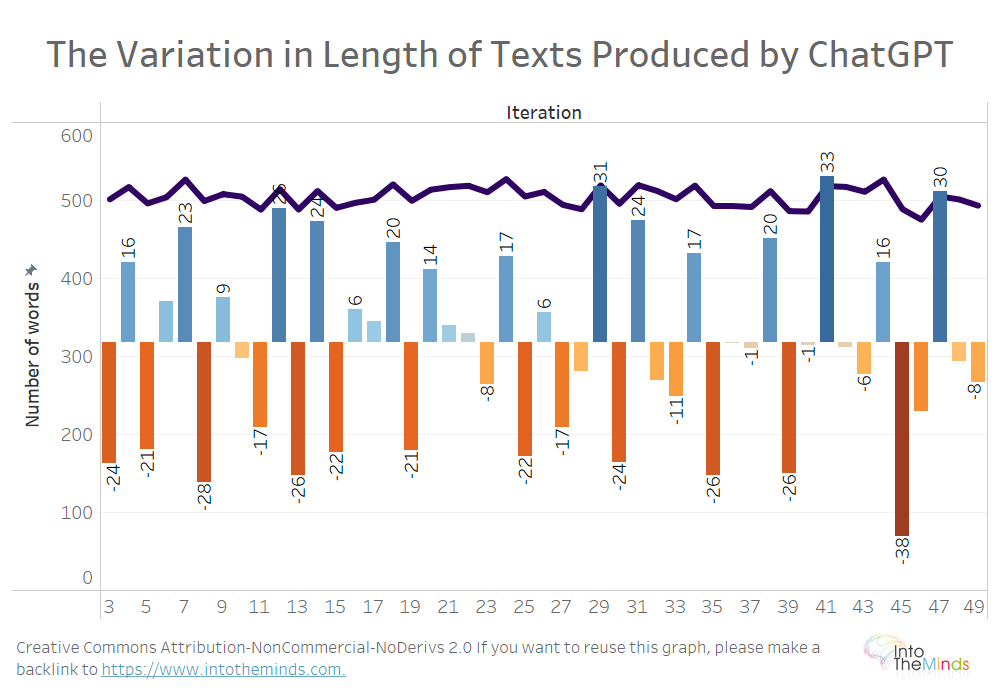
ChatGPT respects the instructions on the length of the text
The first lesson of this research is that ChatGPT respects the instructions regarding word count relatively well. Out of the 1000 texts produced, the average number of words per text was 505.1. This is an incredible performance because it means that the data given to ChatGPT is respected with a tolerance of barely 1%. Content creators will be delighted since they find it an ultra-simple way to produce generic content for their websites.
This is what you see in the graph below with the purple line. The bars indicate the average deviation from one iteration to the next. For example, there are 24 fewer words between the first and the second iteration.
In our previous experiment, we did not give ChatGPT any instructions regarding the length of the text. The average was 253.7 words with tolerances of +8.3%/-7.6%. We can therefore hypothesize that materializing the target in the instructions to ChatGPT allows us to obtain a much more accurate result.
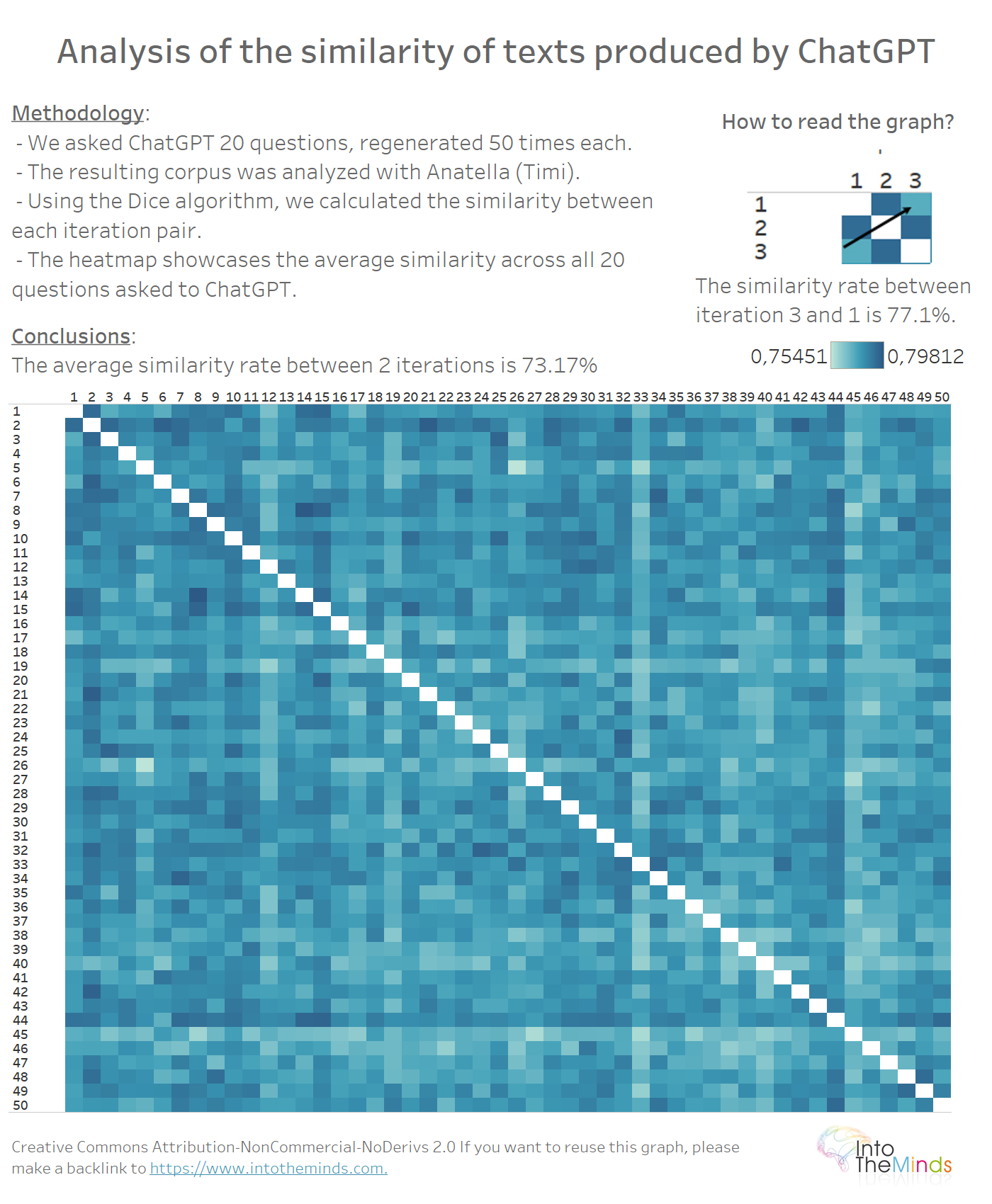
77.9% similarity: ChatGPT answers to the same question are very similar
In our first research, we measured a similarity rate of 72%. We then gave precise instructions to ChatGPT regarding the text structure to produce. By giving more vague instructions, we see that the average similarity rate increases to 77.9%.
The heatmap below represents the average similarity rate between the 2 iterations. In other words, each colored square is used to assess how similar the result produced by ChatGPT between 2 iterations is. The similarity rate was computed thanks to Anatella (my favorite ETL 😀) using the Sorensen-Dice method. There are many other methods, but this one gives excellent results (see here a benchmark of 4 fuzzy matching algorithms available natively in Anatella).
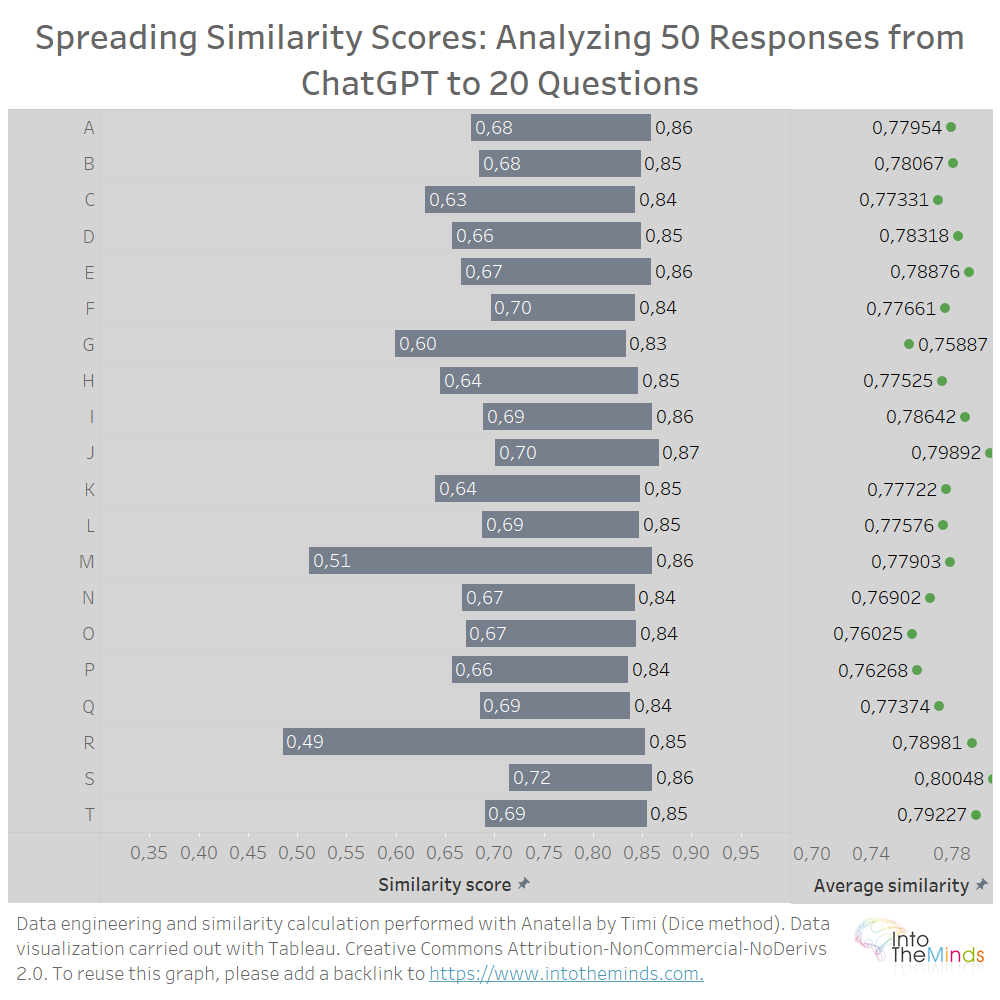
Of course, it is also possible to represent the results for each of the 20 questions asked. This is what I did below. You will notice that the averages for each set are very close. This means that when you ask ChatGPT to regenerate its text, the result will be, on average, very close to the previous one, whatever the question. This does not prevent some accidents (series M and R, for example). In these 2 cases, a more detailed analysis shows that ChatGPT produced 2 texts of very different lengths (200 words difference) between 2 successive iterations. The similarity rate is necessarily affected by this.
What can we learn from these graphs? That ChatGPT is surprisingly stable when you ask it to regenerate an answer. Even if the text it proposes seems to be different, in the end, it’s just the same words put in a different order. I’m caricaturing a little, but that’s the spirit of the results.
65.44% similarity between answers to different questions
The last analysis we carried out was to research the similarity of answers to different questions. In other words, we calculated the average similarity between all answers to question A and all answers to question B. And we repeated this cross-analysis for each question.
The exercise was simple, but it presented some technical challenges due to the limitations of the visualization software (Tableau). Anatella allowed me to get around the problems by preparing the data outside of Tableau (and very quickly, as I already showed here). The result is again presented as a heatmap (see below).
The results speak for themselves. The average similarity between questions is 65.44%. In other words, ChatGPT answers to different questions are 2/3 similar. Of course, the wording of the different questions was the same, but this result is nonetheless intriguing. The question asked is relatively terse, with no instructions other than the word count. Although the topics are different, the answers provided by ChatGPT are from the same mold.
This should encourage you to be very detailed in your requests to ChatGPT. The more specific you are, the more likely you will get unique, non-repetitive responses.

Data transformation process
Toute la préparation des données a été réalisée avec Anatella. Il s’agit d’une solution logicielle de type ETL (Extract – Transform – Load). Avec un ETL vous pouvez extraire des données, les transformer (corrections, enrichissement, …) et les réinjecter dans un autre logiciel en sortie.
All data preparation was carried out with Anatella. It is an ETL (Extract – Transform – Load) software solution. With an ETL, you can extract data, transform them (corrections, enrichment, …) and reinject them in another software.
The reasons that pushed me to choose Anatella for this project are 3:
- speed (see a benchmark here):
- available tools for the calculation of the similarity
- reactivity of the editor (Timi) who proposed me a custom development to answer a need that was not covered
Three different flows of data preparation were created under Anatella. Each flow allowed me to conduct further analysis and explore the ChatGPT responses differently.
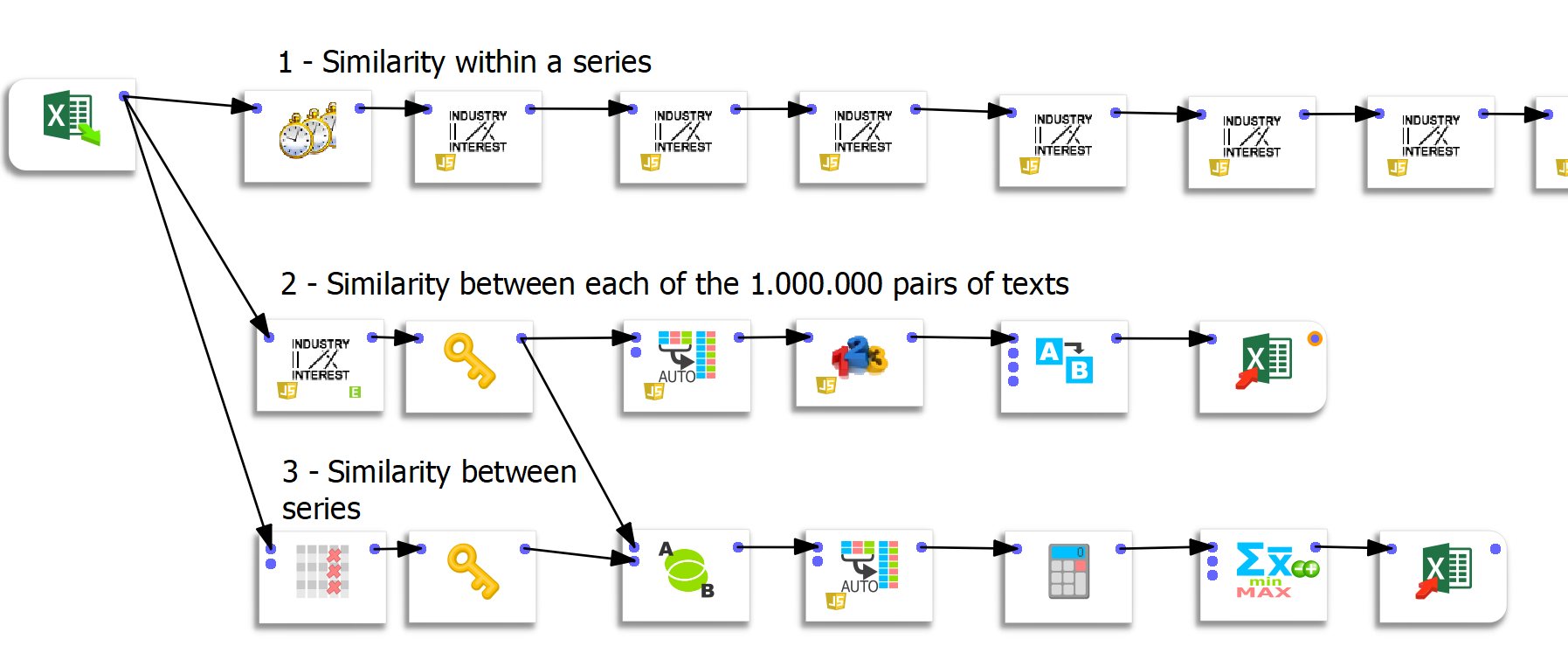
Flow 1: Computing similarities within a series
In this first flow, I compute the similarities between each iteration sequentially. Anatella has a ready-to-use feature for this. It’s very convenient, and you must assemble the boxes for the desired result.
Flow 2: Calculating the similarities between each pair of texts
To carry out this operation, the company Timi provided me with a custom feature. It is a “box” that allows one to calculate the similarities between each text at once. Thus, the box makes it possible to easily calculate 1.000.000 similarities (1000 columns x 1000 lines) in only one time.
An extremely important technical point concerns the ingestion of data in Tableau. Tableau can only handle 700 columns. It is, therefore, impossible to rotate this data in Tableau directly. Therefore, the use of Anatella was a very precious help, essential to the project’s success.
Flow 3: calculation of the similarity between series
The last flow allows us to calculate the similarity between the answers to the different questions.
Liste des sujets
Here is the list of topics that have been submitted to ChatGPT.
| Référence | Sujet |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |
![Illustration of our post "Human resources: state of process digitalisation [Study]"](/blog/app/uploads/concept-shapes-120x90.jpg)




