
![ChatGPT: de antwoorden zijn erg vergelijkbaar [exclusief onderzoek]](/blog/app/uploads/chatGPT-brain-cerveau.jpg)
ChatGPT beschikt over een verbazingwekkend responsvermogen. Als u op de knop “regenerate response” drukt, geeft ChatGPT u een gloednieuw antwoord. Alleszins, zo lijkt het toch. Want in werkelijkheid blijkt uit de resultaten die we in dit artikel met u delen dat ChatGPT zichzelf veel herhaalt. Zozeer zelfs dat antwoorden op verschillende vragen er hetzelfde uitzien! Dit blijkt uit een eerste studie die we over dit onderwerp publiceerden. Vandaag tonen we verder aan dat hoe minder precies uw vraag aan ChatGPT is, hoe meer de antwoorden op elkaar lijken. De gelijkenis bereikt gemiddeld 77,91%.
Voor dit project werden de gegevens voorbereid en verrijkt met Anatella, de ETL-oplossing van Timi. De visualisatie van de gegevens werd uitgevoerd met Tableau.
Wat leren we uit dit onderzoek naar de werking van ChatGPT?
- 505,1 woorden: de gemiddelde lengte van de 1000 door ChatGPT geproduceerde teksten op basis van een streeflengte van 500 woorden.
- 1%: naleving door ChatGPT van de gegeven instructie wat betreft tekstlengte .
De door ChatGPT geproduceerde teksten met minimale instructies lijken aanzienlijk meer op elkaar (77,91%) dan wanneer er meer gedetailleerde instructies worden gegeven (73,17%). - Wanneer de instructies voor ChatGPT niet erg gedetailleerd zijn, komen de antwoorden op verschillende vragen meer overeen (65,44%) dan wanneer gedetailleerde instructies worden gegeven (60,93%).
- Wat de vraag ook is, ChatGPT toont een verbazingwekkend vermogen om vergelijkbare antwoorden te produceren wanneer u vraagt om een antwoord te regenereren (tussen 76,02% en 80,04% gemiddelde overeenkomst, afhankelijk van de vraag). Verwacht dus geen compleet verschillende antwoorden van de ene regeneratie tot de andere.
Methode
Ik stelde ChatGPT 20 vragen. Voor elke vraag vroeg ik het antwoord 50 keer te regenereren, wat overeenkomt met 50 iteraties. Ik heb dus 1000 antwoorden geanalyseerd.
Hier volgt een voorbeeld:

Om een antwoord te regenereren, drukt u gewoon op de knop hieronder:
De vragen waren allemaal identiek van vorm:
Write me a SEO-optimized article of 500 words on “KEYWORD”
Het enige verschil was het “trefwoord” van de ene reeks naar de andere. De lijst van trefwoorden vindt u onderaan dit artikel.
Uiteindelijk werden 20 vragen x 50 iteraties = 1000 teksten geanalyseerd.
Zodra de gegevens uit ChatGPT waren gehaald, werden ze voorbereid met gespecialiseerde software, ETL genaamd. Voor de data preparation gebruik ik uitsluitend Anatella, wat ik beschouw als het beste in zijn categorie (zie hier mijn advies voor het kiezen van een ETL). De visualisatie van de gegevens gebeurde in Tableau.
ChatGPT respecteert de instructies over tekstlengte
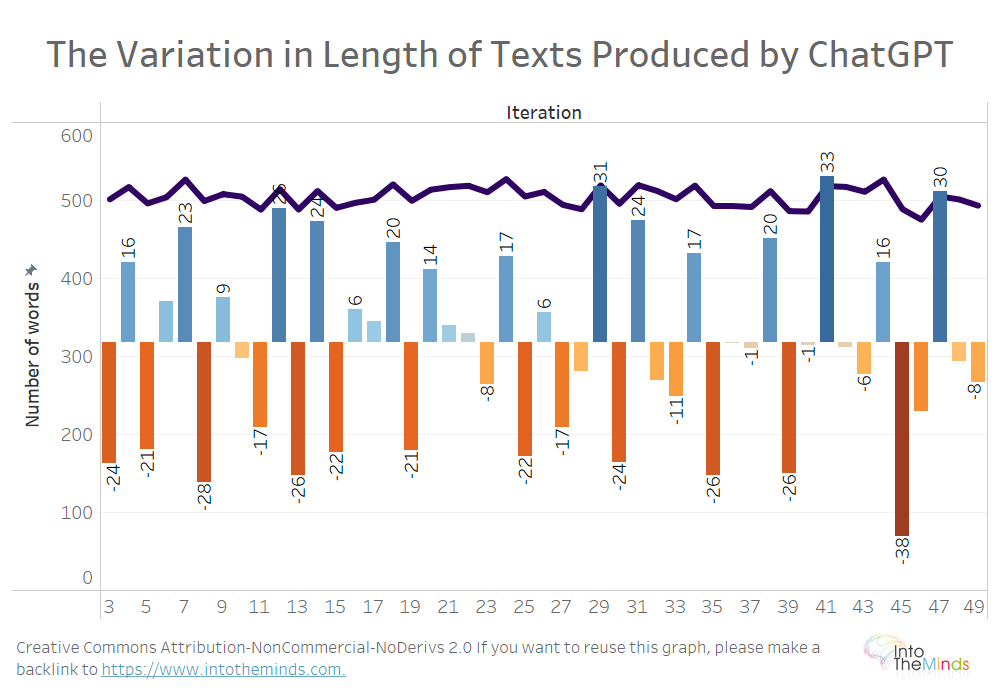
De eerste les van dit onderzoek is dat ChatGPT de instructies die het krijgt op het vlak van woordaantal relatief goed respecteert. Dat zal content creators verheugen, want zij vinden het een uiterst eenvoudige manier om generieke inhoud voor hun website te produceren. Van de 1000 geproduceerde teksten bedroeg het gemiddelde aantal woorden per tekst 505,1. Dit is een absoluut ongelooflijke prestatie, want het betekent dat de instructies die aan ChatGPT zijn gegeven, worden nageleefd met een tolerantie van slechts 1%.
Dat zien we met de paarse lijn in de grafiek hieronder. De balken geven de gemiddelde afwijking van de ene iteratie naar de volgende aan. Er zijn bijvoorbeeld gemiddeld 24 woorden minder tussen de eerste en de tweede iteratie.
In ons vorige experiment gaven we ChatGPT geen instructies over de tekstlengte. Het gemiddelde bedroeg 253,7 woorden met toleranties van +8,3%/-7,6%. Daarom kan worden aangenomen dat de materialisatie van het doel in de instructies aan ChatGPT tot een veel nauwkeuriger resultaat leidt.
77,9% overeenkomst: de antwoorden van ChatGPT op dezelfde vraag lijken sterk op elkaar
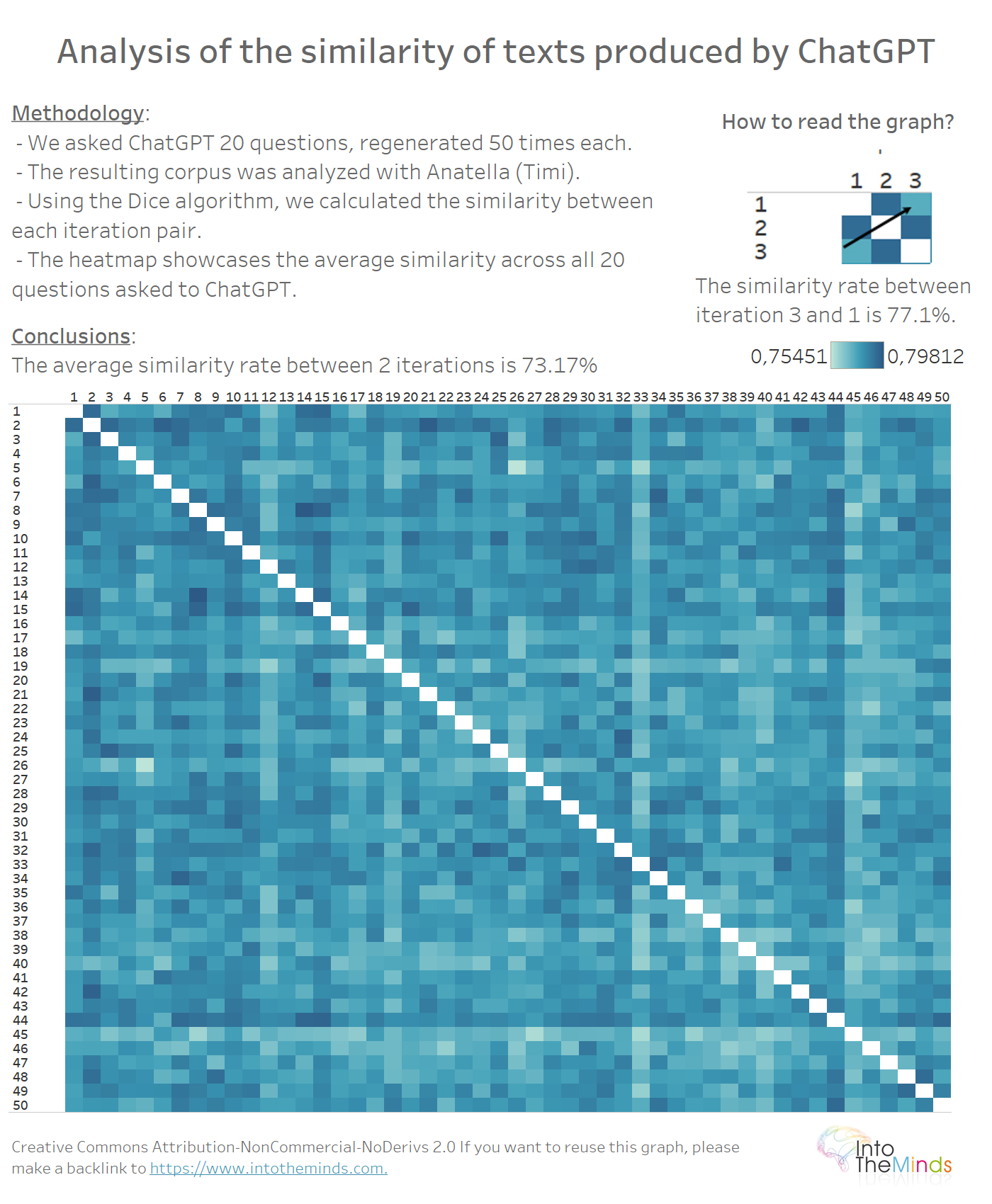
In onze eerste studie hebben wij een similariteitspercentage van 72% gemeten. Wij hadden ChatGPT nauwkeurige instructies gegeven over de structuur van de te produceren tekst. Door vagere instructies te geven, blijkt het gemiddelde similariteitspercentage te stijgen tot 77,9%.
De heatmap hieronder toont de gemiddelde gelijkenis tussen 2 iteraties. Anders gezegd, elk gekleurd vierkantje laat toe te evalueren hoe gelijkaardig het resultaat van ChatGPT is tussen 2 iteraties. Het vergelijkbaarheidspercentage werd berekend met Anatella (mijn favoriete ETL ?) volgens de Sorensen-Dice methode. Er zijn tal van andere methoden, maar deze geeft uitstekende resultaten (zie hier een benchmark van 4 fuzzy matching-algoritmen die beschikbaar zijn in Anatella).
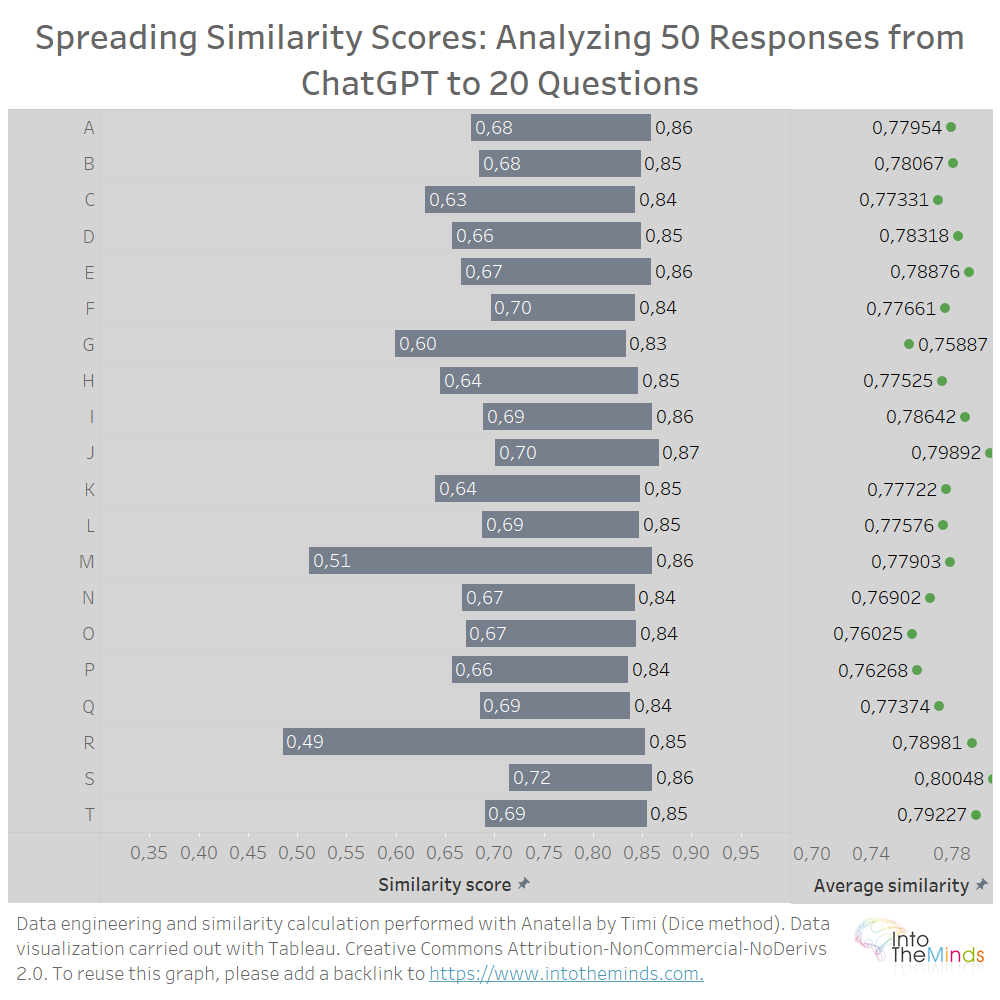
Natuurlijk is het ook mogelijk de resultaten voor elk van de 20 gestelde vragen weer te geven. Dat heb ik hieronder gedaan. U zult zien dat de gemiddelden voor elke set zeer dicht bij elkaar liggen. Dit betekent dat wanneer u ChatGPT vraagt zijn tekst te regenereren, het resultaat gemiddeld zeer dicht bij het vorige zal liggen, ongeacht de vraag. Dit neemt niet weg dat er enkele ongelukjesgebeuren (M- en R-reeksen bijvoorbeeld). In deze twee gevallen blijkt uit een meer gedetailleerde analyse dat ChatGPT tussen twee opeenvolgende iteraties twee teksten van zeer verschillende lengte heeft geproduceerd (200 woorden verschil). Het gelijkenispercentage wordt hierdoor noodzakelijkerwijs beïnvloed.
Wat leren uit deze grafieken? Dat ChatGPT verrassend stabiel is wanneer u vraagt een antwoord te regenereren. Ook al lijkt de tekst die het aanbiedt anders, uiteindelijk zijn het gewoon dezelfde woorden in een andere volgorde. Ik maak een beetje een karikatuur, maar dat is de strekking van de resultaten.
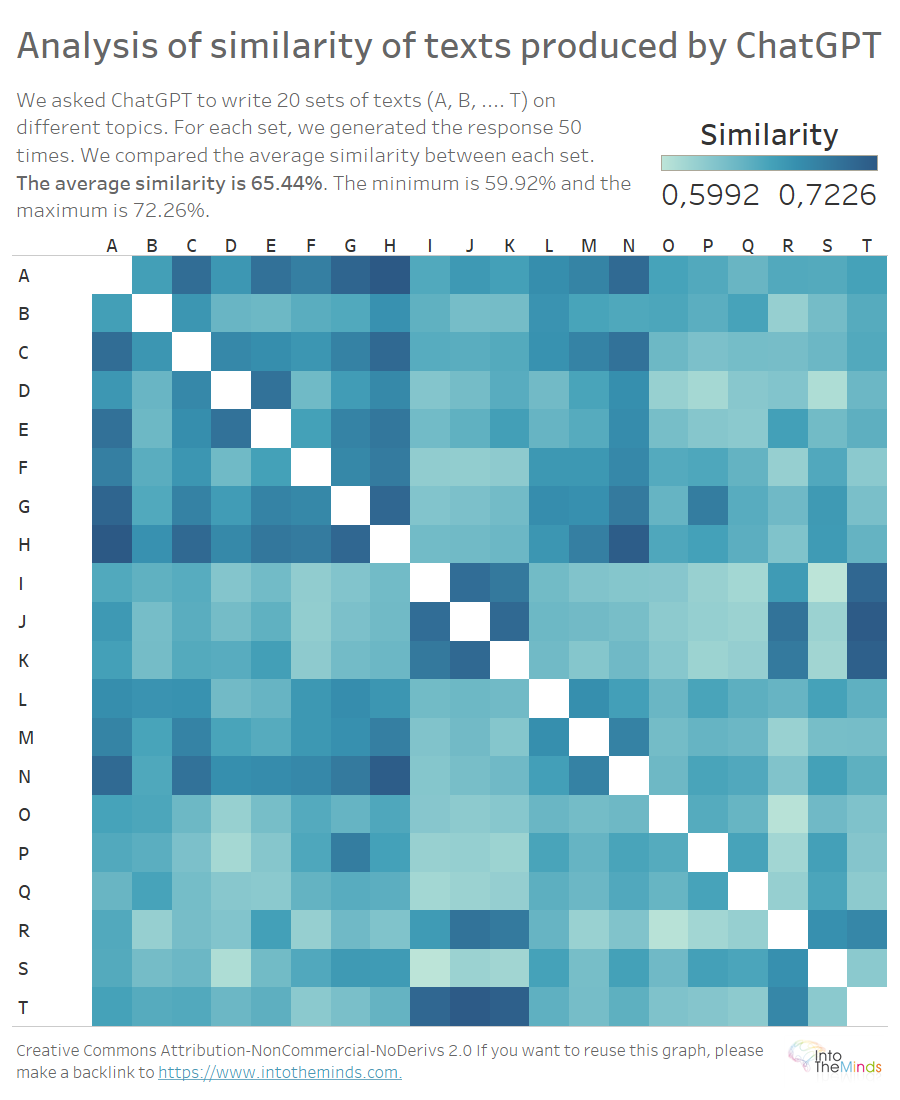
65,44% overeenkomst tussen antwoorden op verschillende vragen
De laatste analyse die wij uitvoerden was het bekijken van de gelijkenis van de antwoorden op verschillende vragen. Met andere woorden, wij berekenden de gemiddelde overeenkomst tussen alle antwoorden op vraag A en alle antwoorden op vraag B. En we herhaalden deze kruisanalyse voor elke vraag.
Het resultaat wordt opnieuw gepresenteerd als een heatmap (zie hieronder). De oefening lijkt op het eerste gezicht eenvoudig, maar leverde enkele technische uitdagingen op door de beperkingen van de visualisatiesoftware (Tableau). Anatella hielp de problemen te omzeilen door de data preparation buiten Tableau te doen (en dat gaat heel snel, zoals ik hier al liet zien).
De resultaten spreken voor zich. De gemiddelde overeenkomst tussen de vragen is 65,44%. Met andere woorden, de antwoorden van ChatGPT op verschillende vragen komen voor 2/3 overeen. Natuurlijk was de formulering van de verschillende vragen hetzelfde, maar dit resultaat is niettemin intrigerend. De gestelde vraag is vrij beknopt, zonder andere instructies dan het aantal in acht te nemen woorden. Hoewel de onderwerpen verschillend zijn, zien we dat de antwoorden van ChatGPT als het ware uit dezelfde mal komen.
Dit zou u moeten aanmoedigen om zeer gedetailleerd te zijn in uw verzoeken aan ChatGPT. Hoe specifieker u bent, hoe groter de kans dat u unieke en niet-repetitieve antwoorden krijgt.
Data preparation
De data preparation werd uitgevoerd met Anatella, een ETL-softwareoplossing (Extract – Transform – Load). Met een ETL kun je gegevens extraheren, transformeren (correcties, verrijking, …) en als output weer in een andere software injecteren.
Er zijn drie redenen waarom voor dit project voor Anatella koos:
- Snelheid (zie een benchmark hier):
- Beschikbare tools voor het berekenen van de similariteit
- Reactiviteit van de uitgever (Timi) die mij een ontwikkeling op maat aanbood om te voorzien in een behoefte die niet was opgenomen
In Anatella werden drie afzonderlijke data preparation-workflows gecreëerd. Met elke flow kon ik een andere analyse uitvoeren en de ChatGPT-reacties vanuit een andere invalshoek verkennen.
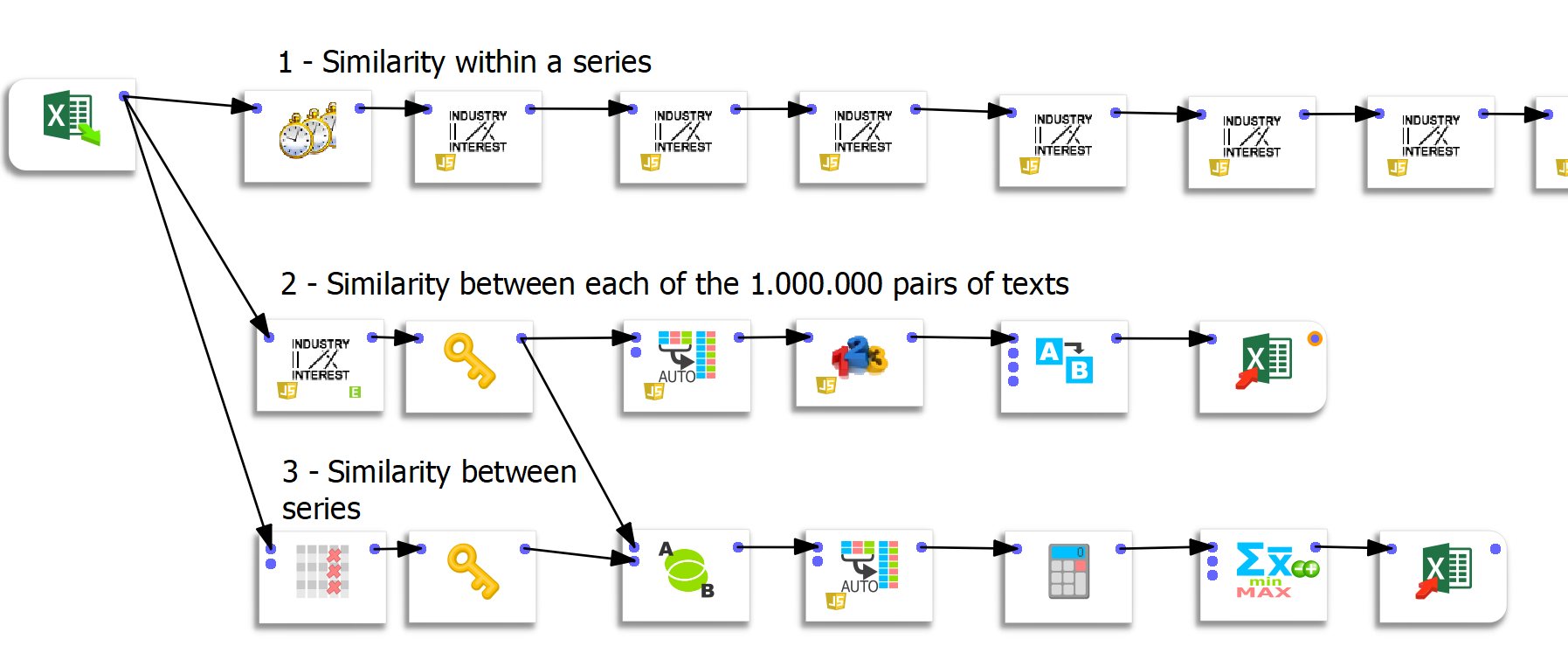
Flow 1: berekenen van overeenkomsten binnen een reeks
In deze eerste flow bereken ik achtereenvolgens de overeenkomsten tussen elke iteratie. Anatella heeft hiervoor een kant-en-klare functie. Het is erg handig en u hoeft alleen maar de vakjes samen te voegen om het gewenste resultaat te krijgen.
Flow 2: berekening van de overeenkomsten tussen elk tekstpaar
Om deze operatie uit te voeren heeft de firma Timi mij een aangepaste functie ter beschikking gesteld. Het gaat om een “box” waarmee in één keer de overeenkomsten tussen elke tekst kunnen worden berekend. De box maakt het dus mogelijk om gemakkelijk 1.000.000 overeenkomsten (1000 kolommen x 1000 rijen) in één keer te berekenen.
Een uiterst belangrijk technisch punt betreft de invoer van gegevens in Tableau. Tableau kan slechts 700 kolommen aan. Het is dus onmogelijk om deze gegevens rechtstreeks in Tableau uit te voeren. Het gebruik van Anatella is daarom een zeer waardevolle tool gebleken, die onmisbaar was voor het welslagen van het project.
Flow 3: berekening van de gelijkenis tussen reeksen
De laatste flow berekent de overeenkomst tussen de antwoorden op de verschillende vragen.
Lijst van onderwerpen
Hier de lijst met onderwerpen die werden ingediend bij ChatGPT:
| Référence | Sujet |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |





![Illustratie van onze post "Turnover: welke strategieën implementeren bedrijven? [Studie]"](/blog/app/uploads/banner-millenial-employee-120x90.jpg)