
![ChatGPT : ses réponses se ressemblent tellement [étude exclusive]](/blog/app/uploads/chatGPT-brain-cerveau.jpg)
ChatGPT a une capacité étonnante. Si vous appuyez sur le bouton « regenerate response », ChatGPT vous proposera une toute nouvelle réponse. Du moins en apparence. Car dans les faits, les résultats publiés dans cet article montrent que ChatGPT se répète beaucoup. Tellement que même les réponses à des questions différentes se ressemblent ! Ceci confirme une première étude que nous avions publiée sur le sujet. Aujourd’hui nous montrons en plus que moins votre requête à ChatGPT est précise, plus les réponses se ressembleront. Le taux de similarité atteint 77,91% en moyenne.
Pour ce projet, les données ont été préparées et enrichies avec la solution ETL de Timi : Anatella. La visualisation des données a été réalisée avec Tableau.
Que retenir de cette étude sur le fonctionnement de ChatGPT
- 505,1 mots : la longueur moyenne des 1000 textes produits par ChatGPT sur la base d’une longueur cible de 500 mots.
- 1% : le respect par ChatGPT de l’instruction donnée en matière de longueur de texte
Les textes produits par ChatGPT avec des instructions minimales sont significativement plus similaires (77,91%) que lorsque des instructions plus détaillées sont données (73,17%) - Lorsque les instructions données à ChatGPT sont peu détaillées, les réponses à des questions différentes se ressemblent plus (65,44%) que lorsque des instructions détaillées sont données (60,93%)
- Quelle que soit la question, ChatGPT montre une étonnante capacité à produire des réponses similaires lorsque vous lui demandez de regénérer sa réponse (entre 76,02% et 80,04% de similarité moyenne en fonction de la question). Ne vous attendez donc pas à recevoir des réponses complètement différentes d’une régénération à l’autre.
Méthodologie
J’ai posé 20 questions à ChatGPT. Pour chaque question, je lui ai demandé de régénérer 50 fois sa réponse, ce qui correspond à 50 itérations. J’ai donc analysé 1000 réponses.
Voici un exemple.

Pour régénérer une réponse, il suffit d’appuyer sur le bouton ci-dessous :
Les questions étaient toutes identiques dans la forme :
Write me a SEO-optimized article of 500 words on « KEYWORD »
Seul différait donc le « mot-clé » d’une série à l’autre. La liste des mots-clés est disponible à la fin de cet article.
Ce sont donc au final 20 questions x 50 itérations = 1000 textes qui ont été analysés.
Une fois les données extraites de ChatGPT, elles ont été préparées avec un logiciel spécialisé appelé ETL. Pour la préparation des données, j’utilise exclusivement Anatella, que je considère comme le meilleur de sa catégorie (voir ici mes conseils pour le choix d’un ETL). La visualisation des données a été réalisée sous Tableau.
ChatGPT respecte les instructions sur la longueur du texte
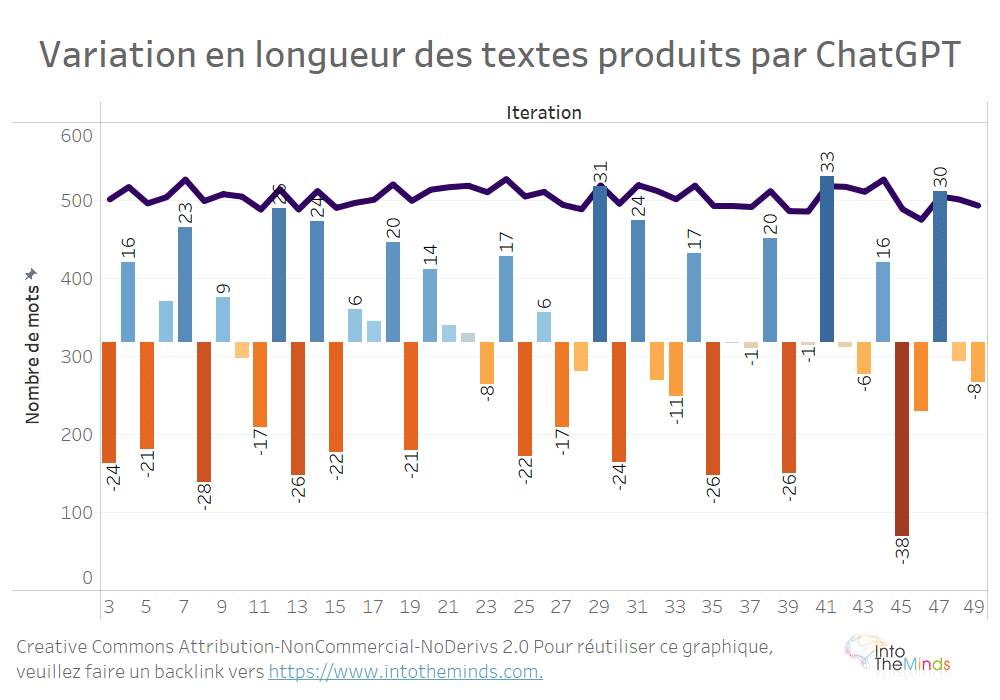
Le premier enseignement de cette étude c’est que ChatGPT respecte relativement bien les instructions qui lui sont données en termes de nombre de mots. Les créateurs de contenus vont être ravis puisqu’ils trouveront là une manière ultra simple de produire du contenu générique pour leur site web. Sur l’ensemble des 1000 textes produits, la moyenne de mots par texte était de 505,1. C’est une performance absolument incroyable car cela signifie que l’instruction donnée à ChatGPT est respectée avec une tolérance d’à peine 1%.
C’est ce que vous voyez sur le graphique ci-dessous avec la ligne violette. Les barres indiquent quant à elles la déviation moyenne d’une itération à l’autre. A titre d’exemple, il y a en moyenne 24 mots en moins entre la première et la deuxième itération.
Dans notre expérience précédente, nous n’avions pas donné d’instructions à ChatGPT en ce qui concernait la longueur du texte. La moyenne s’établissait à 253,7 mots avec des tolérances de +8,3%/-7,6%. On peut donc faire l’hypothèse que la matérialisation de la cible dans les instructions à ChatGPT permet d’obtenir un résultat beaucoup plus précis.
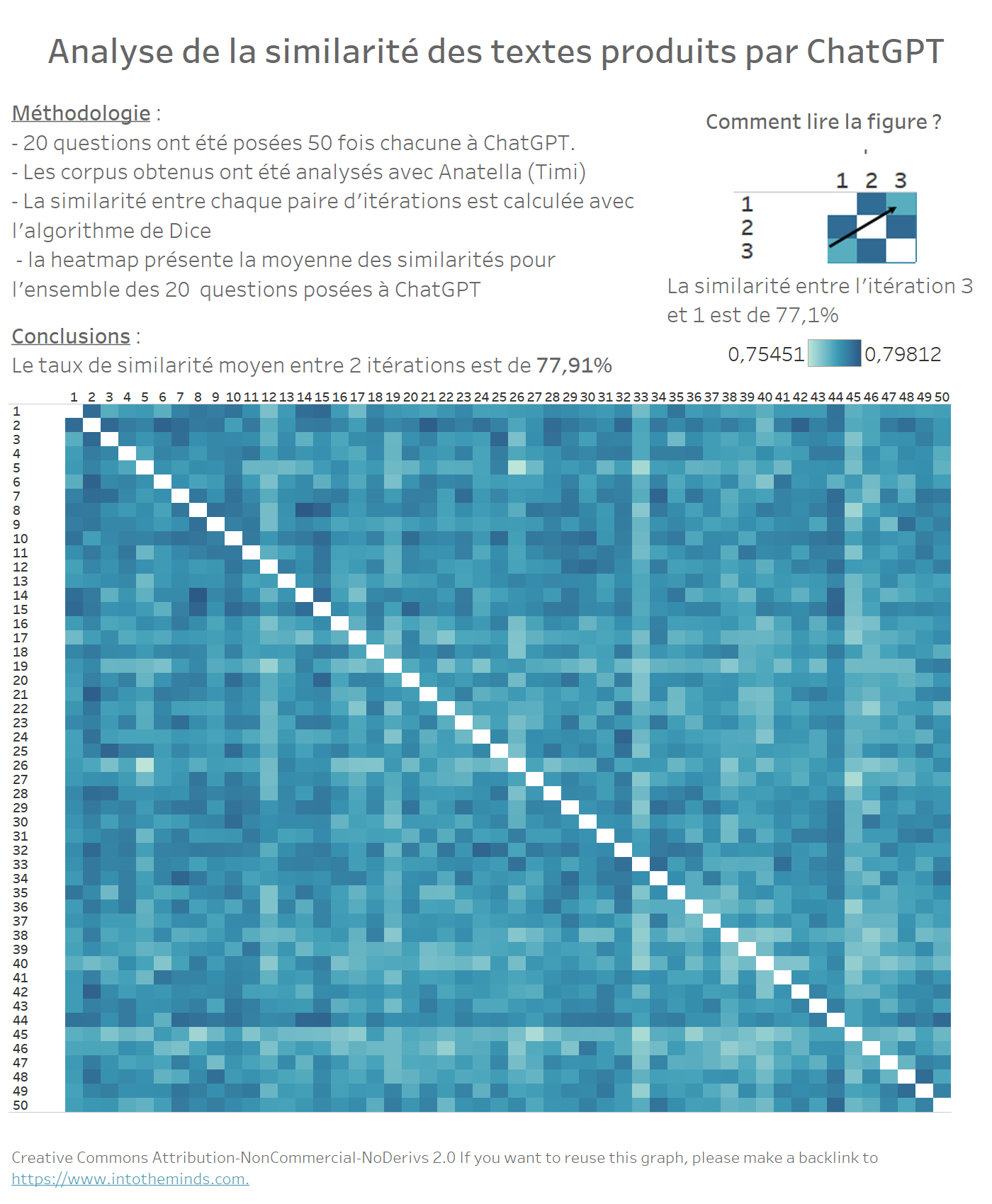
77,9% de similarité : les réponses de ChatGPT à une même question se ressemblent fort
Lors de notre première étude, nous avions mesuré un taux de similarité de 72%. Nous avions alors donné des instructions précises à ChatGPT en termes de structure du texte à produire. En donnant des instructions plus lacunaires, nous constatons que le taux de similarité moyen augmente à 77,9%.
La heatmap ci-dessous représente le taux de similarité moyen entre 2 itérations. Dit autrement, chaque carré de couleur permet d’évaluer à quel point le résultat produit par ChatGPT entre 2 itérations se ressemble. Le taux de similarité a été calculé grâce à Anatella (mon ETL préféré ?) en utilisant la méthode de Sorensen-Dice. Il y a bien d’autres méthodes, mais celle-ci donne d’excellents résultats (voir ici un benchmark de 4 algorithmes de fuzzy matching disponibles nativement dans Anatella).
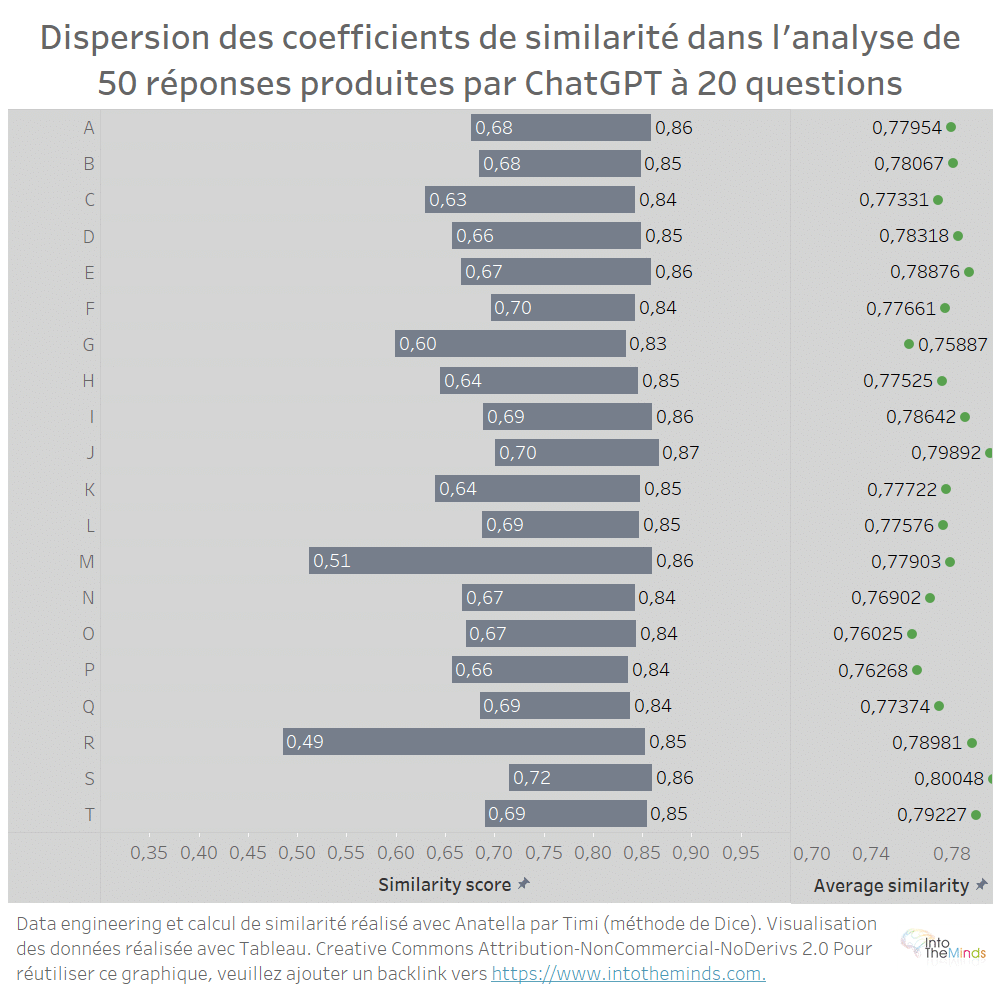
Bien entendu, il est également possible de représenter les résultats pour chacune des 20 questions posées. C’est ce que j’ai fait ci-dessous. Vous constaterez que les moyennes pour chaque série sont très proches les unes des autres. Cela signifie que lorsque vous demandez à ChatGPT de régénérer son texte, le résultat sera en moyenne très proche du précédent, quelle que soit la question. Cela n’empêche pas quelques accidents (séries M et R par exemple). Dans ces 2 cas précis, une analyse plus approfondie nous montre que ChatGPT a produit 2 textes de longueurs très différentes (200 mots de différence) entre 2 itérations successives. Le taux de similarité s’en ressent forcément.
Que retenir de ces graphiques ? Que ChatGPT est étonnement stable lorsque vous lui demandez de régénérer une réponse. Même si le texte qu’il vous propose semble a priori différent, au final ce sont juste les mêmes mots mis dans un ordre différent. Je caricature un peu mais c’est bien l’esprit des résultats.
65,44% de similarité entre les réponses à des questions différentes
La dernière analyse que nous avons réalisée consistait à étudier la similarité des réponses à des questions différentes. En d’autres termes nous avons calculé la similarité moyenne entre toutes les réponses à la question A et toutes les réponses à la question B. Et nous avons répété cette analyse croisée pour chaque question.
Le résultat est à nouveau présenté sous forme de « heatmap » (voir ci-dessous). L’exercice est apparemment simple mais il présentait quelques challenges techniques dus aux limitations du logiciel de visualisation (Tableau). Anatella a permis de contourner les problèmes en préparant les données en dehors de Tableau (et très rapidement comme je l’ai déjà montré ici).
Les résultats parlent d’eux-mêmes. La similarité moyenne entre questions est de 65,44%. En d’autres termes, les réponses de ChatGPT à des questions différentes se ressemblent aux 2/3. Bien entendu la formulation des différentes questions était la même, mais il n’en reste pas moins que ce résultat est interpellant. La question posée est relativement lapidaire, aucune instruction n’étant donnée à part le nombre de mots à respecter. Bien que les sujets soient différents, nous constatons donc que les réponses fournies par ChatGPT sortent pour ainsi dire du même moule.
Cela devrait vous inciter à bien détailler vos demandes à ChatGPT. Plus vous serez précis, plus vous aurez de chance d’obtenir des réponses uniques et non répétitives.

Processus de transformation des données
Toute la préparation des données a été réalisée avec Anatella. Il s’agit d’une solution logicielle de type ETL (Extract – Transform – Load). Avec un ETL vous pouvez extraire des données, les transformer (corrections, enrichissement, …) et les réinjecter dans un autre logiciel en sortie.
Les raisons qui m’ont poussé à choisir Anatella pour ce projet sont au nombre de 3 :
- rapidité (voir un benchmark ici) :
- outils disponibles pour le calcul de la similarité
- réactivité de la société éditrice (Timi) qui m’a proposé un développement custom pour répondre à un besoin qui n’était pas couvert
Trois flux distincts de préparation des données ont été créés sous Anatella. Chaque flux m’a permis de réaliser une analyse différente et d’explorer les réponses de ChatGPT sous un angle différent.
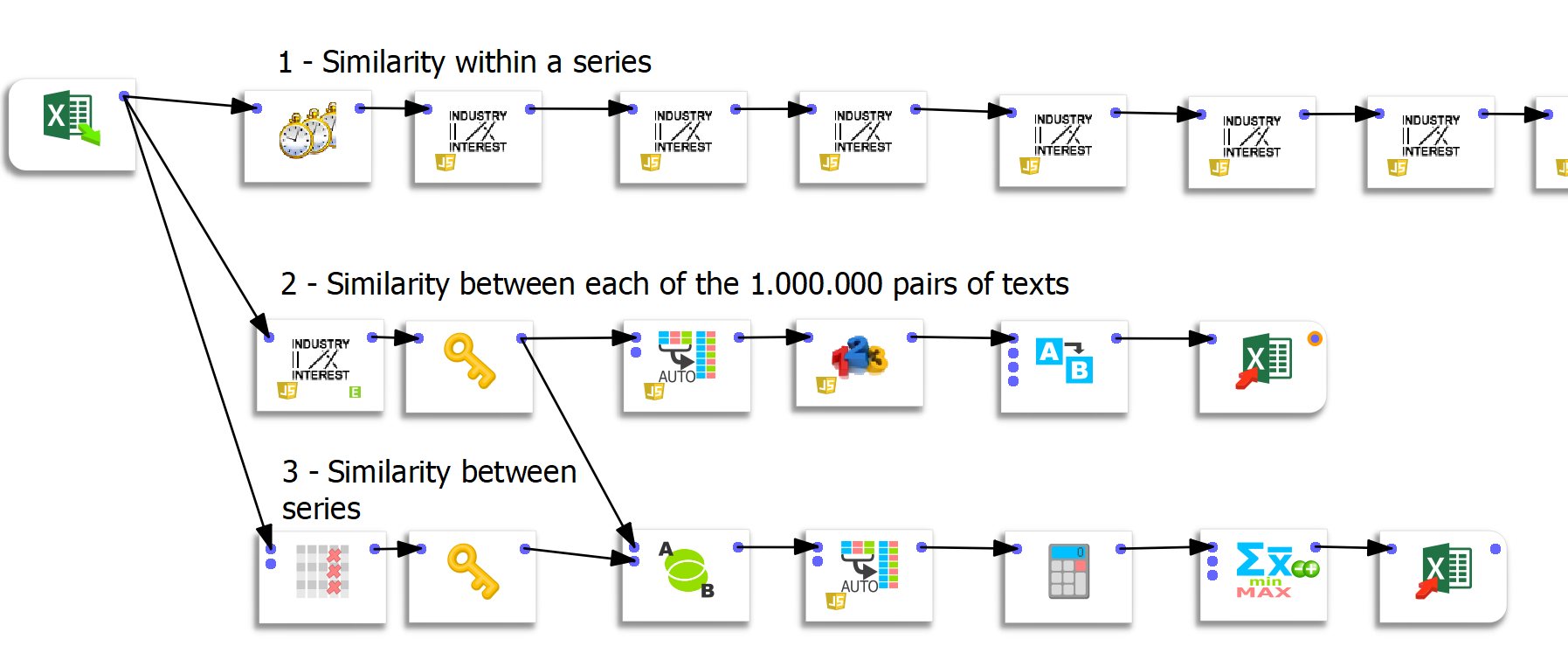
Flux 1 : calcul des similarités à l’intérieur d’une série
Dans ce premier flux, je calcule de manière séquentielle les similarités entre chaque itération. Anatella dispose d’une fonctionnalité prête à l’emploi pour cela. C’est très pratique et vous avez juste à assembler les boîtes entre elles pour parvenir au résultat voulu.
Flux 2 : calcul des similarités entre chaque paire de texte
Pour réaliser cette opération, la société Timi a mis à ma disposition une fonctionnalité sur-mesure. Il s’agit d’une « boîte » qui permet de calculer en une seule fois les similarités entre chaque texte. La boîte permet donc de calculer facilement 1.000.000 de similarités (1000 colonnes x 1000 lignes) en une seule fois.
Un point technique extrêmement important concerne l’ingestion des données dans Tableau. Tableau ne peut gérer que 700 colonnes. Il est donc impossible de pivoter ces données dans Tableau directement. L’utilisation d’Anatella s’est donc révélé d’une aide très précieuse, indispensable pour faire aboutir le projet.
Flux 3 : calcul de la similarité entre séries
Le dernier flux permet de calculer la similarité entre les réponses aux différentes questions.
Liste des sujets
Voici la liste des sujets qui ont été soumis à ChatGPT.
| Référence | Sujet |
| A | Activation marketing |
| B | Astroturfing |
| C | Gender marketing |
| D | Marketing as a service |
| E | Marketing automation |
| F | Emoji marketing |
| G | Reactive marketing |
| H | Street marketing |
| I | Net Promoter Score |
| J | Customer experience |
| K | Customer Lifetime Value |
| L | Brand safety |
| M | Celebrity marketing |
| N | Buzz marketing |
| O | call to action |
| P | Newsjacking |
| Q | Microblogging |
| R | Social CRM |
| S | Social media planning |
| T | churn rate |


![Illustration de notre publication "Industrie automobile allemande : bilan 2024 et perspectives [Etude]"](/blog/app/uploads/volkswagen-wolfsburg-120x120.jpg)
![Illustration de notre publication "Turnover : quelles stratégies les entreprises mettent-elles en place ? [Etude]"](/blog/app/uploads/banner-millenial-employee-120x90.jpg)
