

Los acontecimientos de 2020 han acelerado el cambio hacia el teletrabajo y las relaciones digitales. Gracias a la digitalización, se ha puesto en marcha también otra transformación: la transformación analítica. Para hacer frente a esta revolución de los datos, creo que las empresas no tienen necesariamente las herramientas adecuadas para preparar y analizar los datos (preparación de datos o data wrangling).
En este artículo, he querido destacar el papel de estas herramientas en el funcionamiento de una empresa. En particular, creo que pueden ayudar a aumentar la eficiencia, y es lo que intentaré demostrar. En concreto, he identificado 11 características que determinan la solución perfecta para la gestión y preparación de los datos. Se trata de una ampliación de un borrador que ya había escrito sobre el tema.
Índice
- Transformación de datos: un reto para los recursos humanos
- Las 11 características de una herramienta ejemplar de tratamiento/preparación de datos

Transformación de datos: un reto para los recursos humanos
La generación de valor a partir de los datos siempre ha sido realizada por perfiles especializados y costosos (doctores en ciencia de datos, codificadores en R/Python). Aunque la subcontratación siempre es útil para necesidades específicas, tiene una gran desventaja: los consultores externos no entienden su negocio y necesitan tiempo para captar las sutilezas ocultas de sus datos.
Para aprovechar al máximo sus datos y extraer rápidamente todo lo que contienen y su valor, es esencial interiorizar los conocimientos sobre los datos y poner a disposición herramientas que puedan ser utilizadas por muchas personas. El uso de herramientas self-service del data wrangling por parte de todos los analistas me parece esencial. Son precisamente estas personas las que entienden el problema que hay que resolver y las que, por tanto, tienen más posibilidades de éxito si disponen de los medios técnicos.
De hecho, es fundamental interiorizar los conocimientos sobre los datos y poner a disposición del mayor número posible de personas las herramientas útiles.
Este enfoque permite que el enfoque analítico salga del departamento de “Ciencia de Datos”. También es el primer paso para inculcar una cultura analítica global y ser más “ágil”.
Hay muchos tipos de personas dentro de las empresas que manipulan los datos. En el 99% de los casos, se hace con Excel, y es aquí donde se puede ganar en eficiencia. De hecho, las buenas herramientas de “data wrangling” / “preparación de datos” ofrecen soluciones a todas las limitaciones de Excel (transformaciones complejas, múltiples formatos de datos, volumen, …). Yo prefiero utilizar Anatella, de la que ya he hablado muchas veces (por ejemplo, ver aquí).
En los siguientes párrafos, explicaré las que, en mi opinión, deberían ser las 11 características de una herramienta ideal para la preparación y el wrangling de datos.

La herramienta de data wrangling debe ser una herramienta “self-service” …
Una herramienta de preparación de datos self-service permite a sus analistas resolver los problemas de la empresa con mayor rapidez. Pueden analizar los datos y su contexto y, con la herramienta adecuada, son autónomos.

La preparación de los datos debe ser rápida.
Normalmente, los científicos de datos dedican más del 85% de su tiempo a preparar los datos. Por lo tanto, una herramienta que aumente la velocidad y la productividad de la preparación de datos es bienvenida.
En particular, los científicos de datos experimentados saben que necesitan reducir el tiempo dedicado a la “manipulación de datos” para un mejor trabajo. Por eso, al igual que los analistas de negocio, los científicos de datos más experimentados piden una herramienta “self-service” con un ratón, porque les permite tener una inmensa ganancia de productividad y tiempo durante la costosa fase de “data wrangling”.

Hay que elegir una herramienta federada.
Más bien, me parece esencial contar con una herramienta que promueva y simplifique la colaboración entre los analistas de negocio (orientados al negocio) y los científicos de datos (orientados a la técnica). Sin este aspecto unificador, será realmente difícil conseguir una cultura analítica global en su empresa.
El aspecto de federación de una herramienta de “preparación de datos” es quizá el más difícil de conseguir, porque las necesidades de los usuarios empresariales suelen estar muy alejadas de las de los científicos de datos:
- Los analistas de negocio evitan el código y quieren un acceso fácil e instantáneo a la información que desean. Suelen trabajar con pequeños volúmenes de datos y no utilizan algoritmos muy complejos.
- A los científicos de datos les gusta codificar, y escribir mil líneas de código en R/Python no los detendrá (después de todo, ¡sólo estamos hablando de un día de trabajo!). A menudo trabajan con grandes volúmenes y utilizan algoritmos complejos.

La posibilidad de un trabajo iterativo
El trabajo con datos es infinito y debe entenderse como un ciclo. El ciclo representado en el esquema a continuación muestra que el trabajo es constante. Se alimenta constantemente de nuevos datos: datos actualizados, por un lado, y datos de nuevas fuentes, por otro.
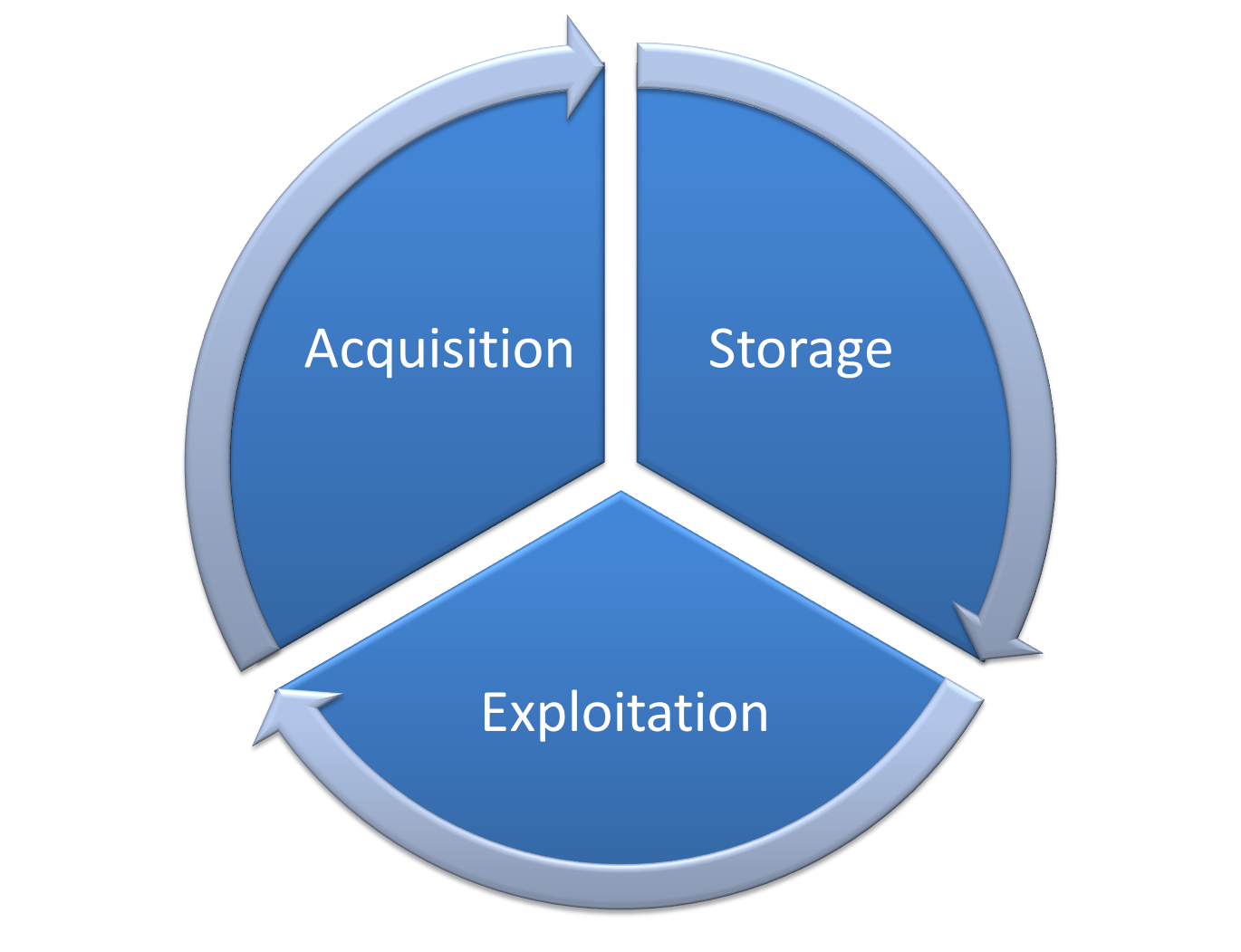
El procesamiento de datos no es un fin en sí mismo. Es un ciclo, un eterno reinicio. Por tanto, las herramientas utilizadas deben ser capaces de gestionar los ciclos de actualización.
Ejemplo de procesamiento iterativo de datos
Muchas empresas utilizan archivos de Excel para recoger (e intercambiar) datos de sus empleados. ¿Qué ocurre cuando un empleado decide cambiar ligeramente la estructura de un archivo de Excel para que se adapte mejor al problema de la empresa?
Este pequeño cambio requiere la actualización del proceso de manipulación de datos que recoge los datos de esos archivos Excel duplicados. Supongamos que este proceso de gestión de datos es opaco (porque está programado en un lenguaje incomprensible que sólo entienden los iniciados el día que escribieron el código). En este caso, todo el proceso de recogida de datos se ve comprometido. Esto conduce a la producción de datos no válidos y, en última instancia, a la toma de malas decisiones. ¿Cuántas veces ha escuchado a un colega decirle que el KPI es absurdo y debe ser ignorado? Esta falta de confianza (justificada) en los resultados analíticos suele deberse a que las herramientas de manipulación de datos no son lo suficientemente transparentes.

Adaptación a grandes volúmenes de datos
Me gusta la idea de herramientas adaptadas al tratamiento rápido de grandes volúmenes de datos (véase mi referencia aquí). El tiempo de procesamiento está relacionado con el volumen de datos a procesar. Sin embargo, con demasiada frecuencia, las herramientas de que disponen los analistas de negocio son demasiado lentas o no les permiten manejar grandes volúmenes de datos.

Una potente herramienta independiente de los recursos en la nube
La cuestión de la potencia de cálculo en la preparación de datos es, en mi opinión, muy importante. Para dar autonomía a los analistas, es necesario que respondan a todas sus preguntas independientemente de que tengan acceso (o no) a un clúster de máquinas en la nube. Si la potencia de cálculo disponible le limita en su análisis, se sentirá frustrado.
Aunque ahora es elemental crear clusters de máquinas en la nube, el precio sigue siendo elevado. Debido a su elevado precio, una empresa “normal” se limitará a construir un clúster en la nube (o incluso dos). El uso de este clúster también estará reservado a un pequeño número de científicos de datos.
Es fácil ver que, en estas condiciones, el desarrollo de una cultura analítica global se ve comprometido. Si sólo dos personas tienen acceso al grupo, ¿cómo se puede aumentar la eficiencia y evitar las dificultades?
Además del precio prohibitivo de la nube, también hay que abordar la cuestión de la soberanía de los datos cuando se almacenan en una nube estadounidense. Puede leer más sobre este tema en la decisión “Schrems II” en el caso C-311/18 aquí.

Una herramienta con costes fijos
No me gusta la idea de no saber de antemano cuánto me va a costar el análisis de los datos. Sin embargo, esta es la situación en la que se encuentran todas las empresas que utilizan AWS o Azure para el procesamiento de datos. La variabilidad de los costes hace imposible predecir cuál será la próxima factura. En otras palabras, hay un coste variable asociado a cada demanda de análisis.
Una propiedad inherente a los clusters de la nube es el “coste variable” asociado a cada demanda analítica. Este es quizás el “Key Selling Point” de las ofertas de los gigantes de la nube: “Sólo pagas por lo que usas”.
Por lo tanto, un científico de datos motivado será la fuente de mayores costes variables porque hará un uso intensivo del clúster de la nube para entender los datos de la mejor manera posible. A la inversa, un científico de datos menos motivado provocará menores costes variables.
El control de los costes de procesamiento en la “nube” sanciona a los científicos de datos más activos y motivados.
Si la evaluación de los científicos de datos se basa en los costes que generan, nos encontramos en una situación paradójica. Los que más trabajan y están más motivados son penalizados. Por lo tanto, el uso “ahorrativo” de la agrupación se convierte en la norma. Como esta situación se produce constantemente, ahora hay muchas herramientas especializadas de “supervisión de la nube” que permiten sancionar y cortar el acceso a los recursos informáticos a todos los científicos de datos desmotivados. En estas condiciones, es fácil ver que mantener a los científicos de datos motivados puede ser complicado.
Por último, una herramienta de gestión de datos que funciona con “costes variables” (como el 99% de las soluciones en la nube) penaliza, desanima e impide trabajar a los mejores.

Simplificar la industrialización
Una buena herramienta de gestión de datos debería permitirle industrializar y automatizar fácilmente las “recetas” desarrolladas por su equipo.
Aquí hay algunas características específicas que me parecen esenciales:
- fácil integración con cualquier programa de programación (por ejemplo, el programador de tareas de MS-Windows o Jenkins).
- rápida implementación dentro de su actual infraestructura de TI u otros lenguajes u otros marcos de datos. Por ejemplo, llamar a un procedimiento de gestión de datos desde un pequeño script de Python es imprescindible.
- lo suficientemente robusto como para manejar un aumento repentino del volumen de datos sin colapsar

Herramienta incorporada
Algunas soluciones ETL no son ETL porque falta la parte de “transformación” (la “T”) o está insuficientemente desarrollada. Doy prioridad a las herramientas que cubren las tres partes del ciclo de datos: adquisición, almacenamiento y explotación. Debe ser posible pasar de una parte a otra sin dificultad y sin pérdida accidental de información.

Multiplicidad de conectores
Ya he hablado muchas veces de la importancia de disponer de varios conectores. Hoy en día, los datos llegan por todas partes, en más y más formatos, y a veces son propios.

Numerosas capacidades de transformación de datos
Ya he mencionado muchas veces este punto, y lo considero esencial en un enfoque “Sin Código”. Es necesario tener un número máximo de “cajas” preprogramadas para cubrir sus tareas diarias de transformación de datos.
Por supuesto, todas las soluciones ETL dignas de ese nombre tienen una amplia gama de “cajas” disponibles. Pero algunos tienen más que otros (por ejemplo, Anatella), lo que puede ser muy conveniente.
Este último punto parece obvio, pero, sorprendentemente, hay pocas soluciones de software que satisfagan esta necesidad. De hecho, muchos proveedores de software se contentan con ofrecer una amplia conectividad y se olvidan por completo del aspecto de “transformación de datos”, que es un componente igualmente necesario, si no más. ¿Quiere algunos ejemplos? Aquí hay dos.
Coincidencia difusa
Extremadamente útil para conciliar 2 bases de datos cuando se tiene una calidad menos que excelente. Sin embargo, sólo conozco una solución que ofrece esto (ver aquí para más información).
La función central
Si está haciendo una visualización de datos, es importante que pueda rotar sus datos. Sin embargo, de nuevo, el 99% de las soluciones de gestión de datos no proponen esto (en Anatella, las cajas se llaman “flatten” y “unflatten”).




