
Fuzzy matching is a handy technique in many everyday situations. Alteryx offers a Fuzzy Matching feature that I have compared to Anatella’s function. I had already talked about Fuzzy Matching in this post. The features of Fuzzy Matching in Tableau Prep builder not being convincing, I wanted to see what Alteryx had to offer. In the end, Anatella gives better results, and the programming of the ETL process is much more efficient.
Summary
- Introduction to Fuzzy Matching with Alteryx
- The 3 steps of Fuzzy Matching with Alteryx
- Results: Alteryx vs. Anatella
- Conclusion

Introduction to fuzzy matching
To learn the basics of Fuzzy Matching under Alteryx, I followed this video. Do it too if you want to get started.
The principle explained is based on fuzzy matching in a single table. The process in Alteryx, therefore, requires to make a union between 2 tables of the same format before you can apply the fuzzy matching process. I’m fully aware that this is a critical limitation, but I will come back to this point a little later in the article.
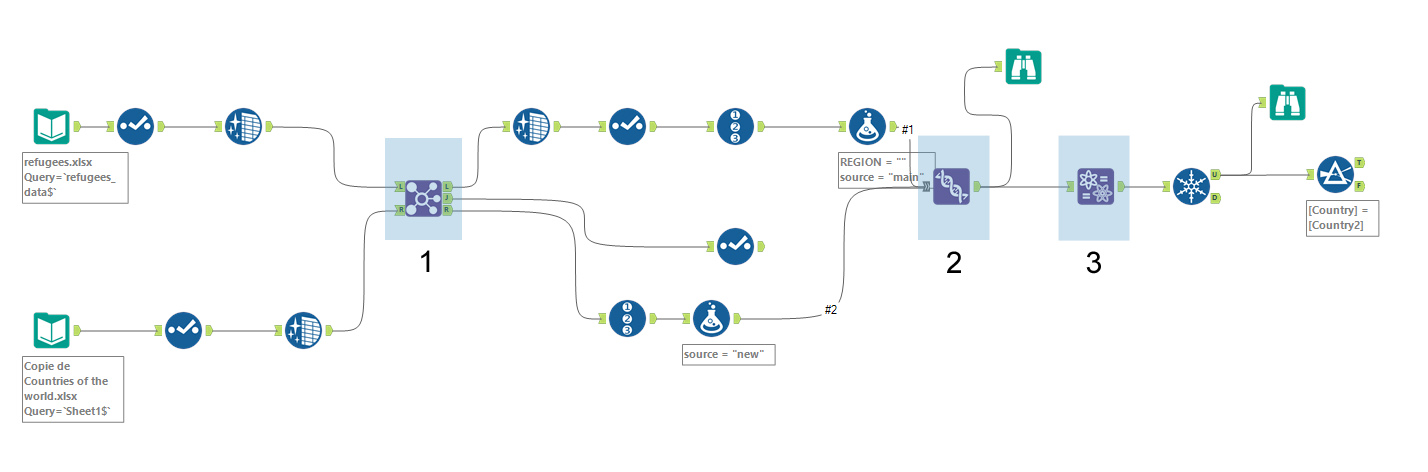
The 3 steps of fuzzy matching with Alteryx
 For this exercise, I have taken the same case as in my previous article. Table 1 (top) contains the immigration data to the European Union, of people coming from outside the EU. Table 2 (bottom) provides information on the +/- 200 countries in the world. The country is notably classified under a vast region” (Asia, Middle East, …) and it is this information that I will try to add. The problem is that the countries between one table and the others are not all spelt the same way. Hence the interest of fuzzy matching.
For this exercise, I have taken the same case as in my previous article. Table 1 (top) contains the immigration data to the European Union, of people coming from outside the EU. Table 2 (bottom) provides information on the +/- 200 countries in the world. The country is notably classified under a vast region” (Asia, Middle East, …) and it is this information that I will try to add. The problem is that the countries between one table and the others are not all spelt the same way. Hence the interest of fuzzy matching.
Step 1
The first step is to make a join between the 2 tables. On the J output, I get all the entries matching the region field that has been added. I reserve this table for later. On the L output, I get the entries for which no match was found. This is the table I will work on in the second step.
Step 2
In the 2nd step, I will realise the union between the table without correspondence (output L) and the reference table (output R). First, I get rid of all extra columns because the union can be achieved only on identical tables.
Step 3
The third step is the actual fuzzy matching. The fuzzy matching is executed using the “Name” function under Alteryx. The algorithm behind it is of the double Metaphone type (more info here). It is, therefore, as under Tableau Prep Builder, an algorithm based on phonetic similarity.

Results: Alteryx vs. Anatella
At the end of the process, I extracted the list of entries for which a match had been found. Based on this list (to download here) we can make a comparison with the results provided in Anatella with Dice’s method.
With a matching threshold at 75% under Alteryx, the fuzzy matching allows to match 11 entries out of 20 (see table below). Very logically, the double Metaphone-type algorithm produces a false positive by confusing Congo (Congo Brazzaville) and the Democratic Republic of Congo. The same error is made by Dice’s method.
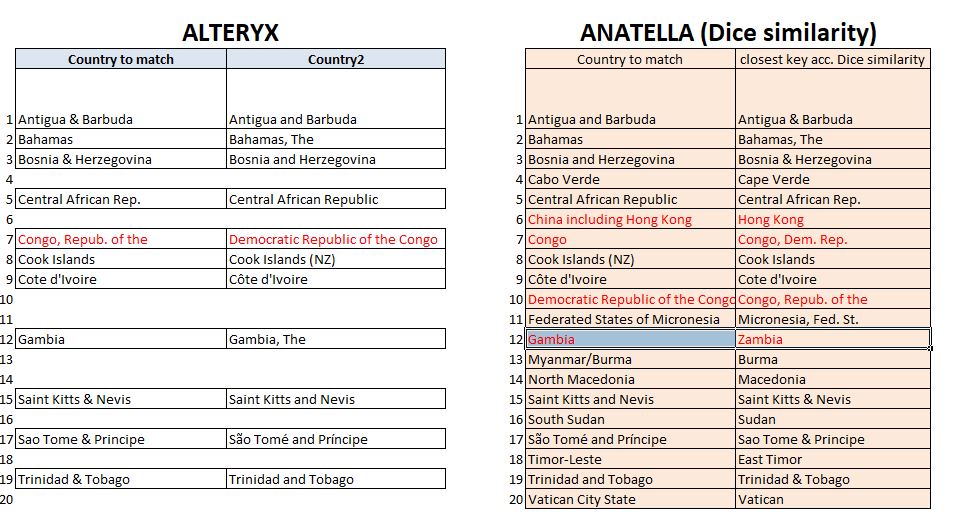
Without specifying a threshold, we obtained 16 out of 20 correct matches with Dice’s method using Anatella.

Conclusion

Alteryx’s fuzzy matching algorithm produces average results in this case. Dice’s algorithm, available in the Anatella ETL, gives much better results.
Furthermore, the fuzzy matching process in Alteryx requires manipulations (union) that are unnecessary. The process under Anatella is much more straightforward and efficient.

