
La fuzzy matching (la comparación parcial) es una técnica muy útil en muchas situaciones cotidianas. Alteryx ofrece una función de Fuzzy Matching que he comparado con la función de Anatella. Ya hablé de Fuzzy Matching en este post. Las características de Fuzzy Matching en Tableau Prep Builder no me convencían, así que decidí echar un vistazo para ver qué ofrecía Alteryx. Al final, Anatella ofrece mejores resultados y la programación del proceso ETL es mucho más eficiente.
Resumen
- Introducción al Fuzzy Matching con Alteryx
- Los 3 pasos de Fuzzy Matching con Alteryx
- Resultados: Alteryx vs. Anatella
- Conclusión

Introducción al Fuzzy Matching
Para aprender los fundamentos del Fuzzy Matching en Alteryx, seguí este video. Hágalo también si quiere empezar.
El principio explicado se basa en el fuzzy matching utilizando una sola tabla. El proceso en Alteryx, por lo tanto, requiere hacer una unión entre 2 tablas del mismo formato antes de poder aplicar el proceso de fuzzy matching. Soy plenamente consciente de que se trata de una limitación crítica, pero volveré a hablar de este punto un poco más adelante en el artículo.
Los 3 pasos del fuzzy matching con Alteryx
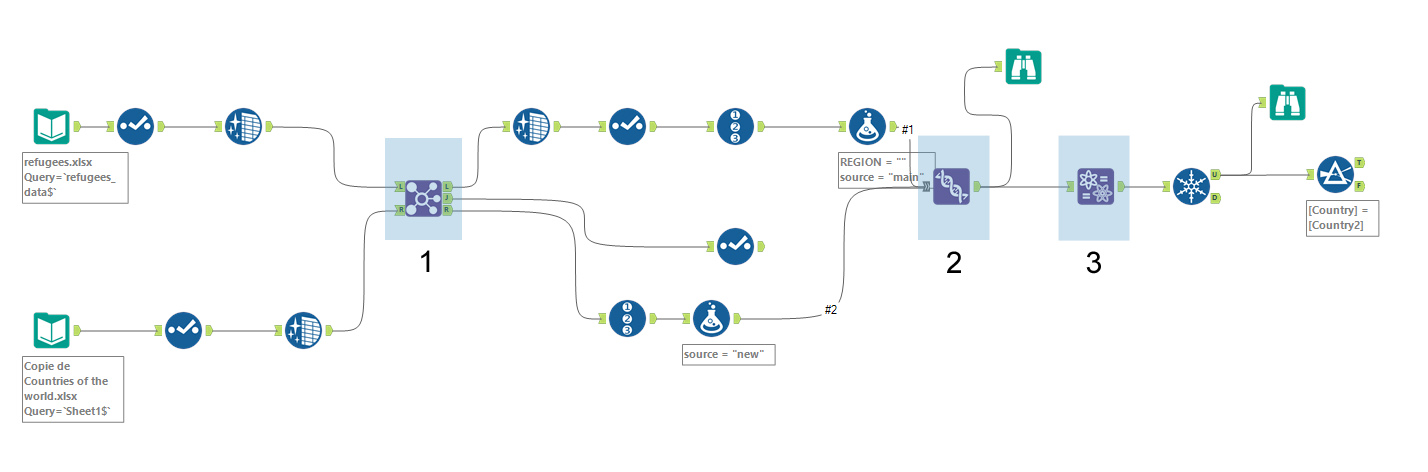
Para desarrollar este ejercicio, he tomado el mismo caso que en mi artículo anterior. La tabla (arriba) contiene los datos de inmigración a la Unión Europea, de personas procedentes de países que no pertenecen a la UE. La tabla 2 (abajo) ofrece información sobre los +/- 200 países del mundo. En particular, el país se clasifica en una vasta región (Asia, Oriente Medio, …) y esta información es la que intentaré añadir. El problema es que los países entre una tabla y la otra no se escriben todos de la misma manera. De ahí nace el interés por el Fuzzy Matching.
Primer paso
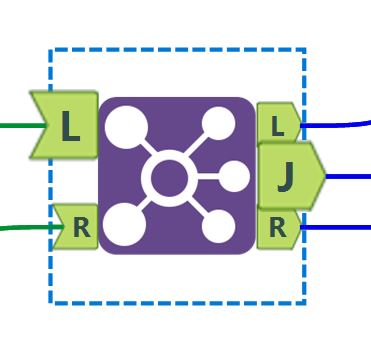
El primer paso es hacer un join entre las 2 tablas. En la casilla J, obtengo todas las entradas que coinciden con el campo región que se ha añadido. Dejo a un lado esta tabla para más adelante. En la casilla L, obtengo las entradas para las que no se ha encontrado ninguna coincidencia. Esta es la tabla en la que trabajaré en el segundo paso.
Segundo paso
En el 2º paso, realizaré la unión entre la tabla sin correspondencia (casilla L) y la tabla de referencia (casilla R). En primer lugar, eliminaré todas las columnas adicionales porque la unión sólo se puede realizar en tablas idénticas.
Tercer paso
El tercer paso se basa en el verdadero fuzzy matching. Este método se ejecuta utilizando la función “Name” de Alteryx. El algoritmo en el que se basa es del tipo Metáfono doble (más información aquí). Por tanto, así como en Tableau Prep Builder, es un algoritmo basado en la similitud fonética..

Resultados: Alteryx vs. Anatella

Al final del proceso, extraje la lista de entradas para las que se encontró una coincidencia. A partir de esta lista (que se puede descargar aquí) podemos hacer una comparación con los resultados proporcionados en Anatella con el método de Dice.
Con un umbral de concordancia del 75% en Alteryx, el fuzzy matching permite encontrar 11 entradas de 20 (véase la siguiente tabla). Muy lógicamente, el doble algoritmo de tipo Metaphone produce un falso positivo al confundir Congo (Congo Brazzaville) y la República Democrática del Congo. El mismo error se produce con el método de Dice.
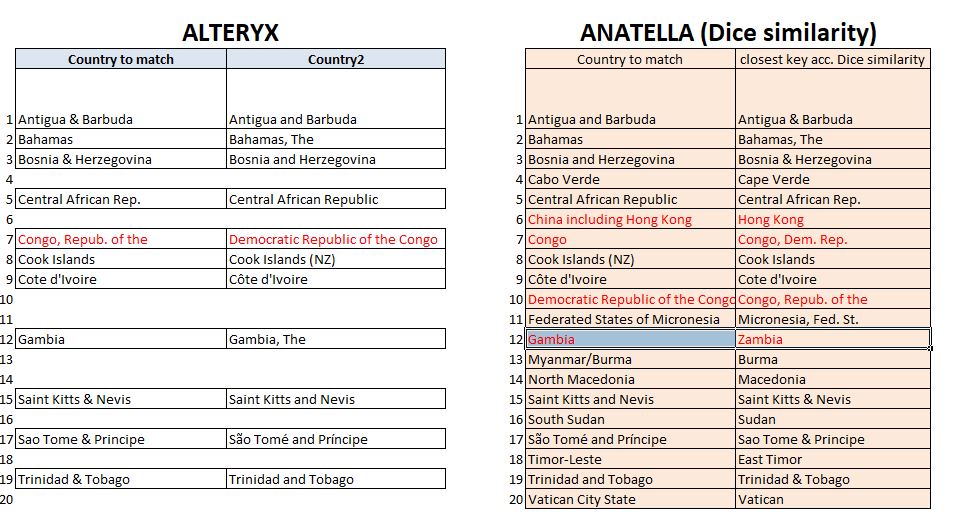
Sin especificar un umbral, obtuvimos 16 de 20 coincidencias correctas con el método de Dice utilizando Anatella.

Conclusión

El algoritmo del fuzzy matching de Alteryx, en este caso, ha producido resultados medios. El algoritmo de Dice, disponible en el ETL de Anatella, ofrece resultados mucho mejores.
Además, el proceso de fuzzy matching en Alteryx requiere manipulaciones (unión) innecesarias. El proceso en Anatella es mucho más sencillo y eficiente.





