
Le fuzzy matching est une technique bien utile dans nombre de situations courantes. Alteryx propose une fonctionnalité de Fuzzy Matching que j’ai comparée à celle d’Anatella. J’avais d’ailleurs déjà parlé de Fuzzy Matching dans ce billet. Les fonctionnalités de Fuzzy Matching dans Tableau Prep builder n’en étant pas vraiment, j’ai voulu voir ce que Alteryx avait dans le ventre. Au final Anatella donne de meilleurs résultats et la programmation du processus d’ETL est beaucoup plus efficace.
Sommaire
- Introduction sur le Fuzzy Matching avec Alteryx
- Les 3 étapes du Fuzzy Matching sous Alteryx
- Résultats : Alteryx vs. Anatella
- Conclusion

Introduction pour se familiariser avec le fuzzy matching
Pour apprendre les bases du Fuzzy Matching sous Alteryx j’ai suivi cette vidéo. Faites-le aussi si vous voulez vous lancer.
Le principe expliqué repose sur le fuzzy matching dans une seule table. Le processus dans Alteryx requiert donc de faire une union entre 2 tables de même format avant de pouvoir appliquer le process de fuzzy matching. Je suis tout à fait conscient que c’est une importante limitation mais je reviendrai sur ce point un peu plus bas dans l’article.
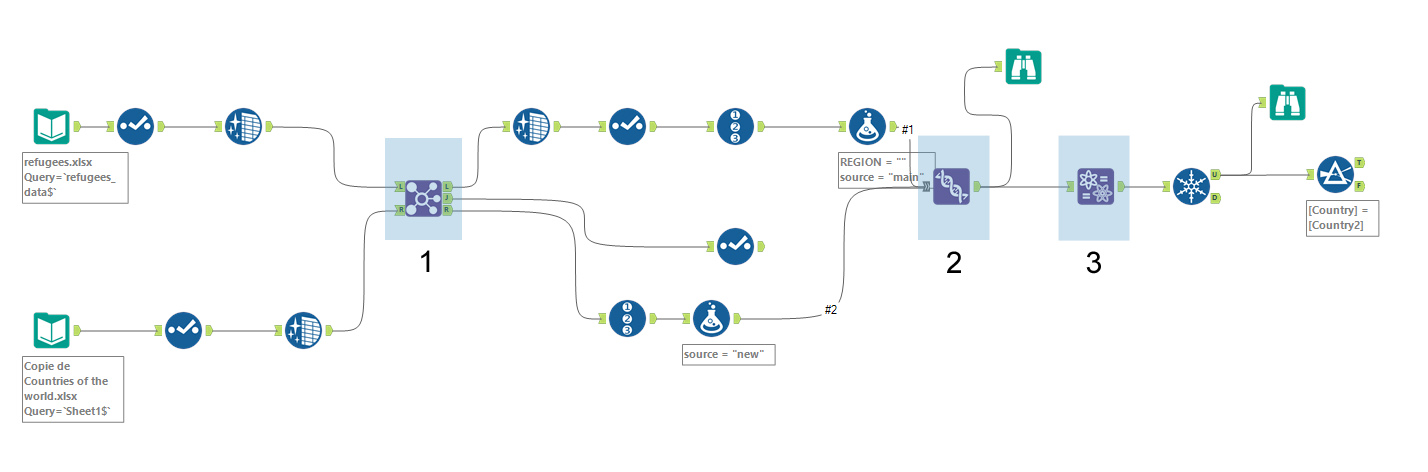
Les 3 étapes du fuzzy matching sous Alteryx
 Pour cet exercice j’ai repris le même cas de figure que dans mon article précédent. La table 1 (en haut) contient les données d’immigration vers l’Union Européenne des personnes en provenance d’un pays extérieur à l’UE. La table 2 (en bas) contient des informations sur les +/- 200 pays du monde. Le pays est notamment classifié sous une grande région » (Asie, Moyen-Orient, …) et c’est cette information que je vais essayer d’ajouter. Le problème c’est que les pays entre l’une et l’autre table ne sont pas tous orthographié de la même manière. D’où l’intérêt du fuzzy matching.
Pour cet exercice j’ai repris le même cas de figure que dans mon article précédent. La table 1 (en haut) contient les données d’immigration vers l’Union Européenne des personnes en provenance d’un pays extérieur à l’UE. La table 2 (en bas) contient des informations sur les +/- 200 pays du monde. Le pays est notamment classifié sous une grande région » (Asie, Moyen-Orient, …) et c’est cette information que je vais essayer d’ajouter. Le problème c’est que les pays entre l’une et l’autre table ne sont pas tous orthographié de la même manière. D’où l’intérêt du fuzzy matching.
Etape 1
La 1ère étape consiste à à réaliser une jointure entre les 2 tables. Sur la sortie J je récupère toutes les entrées concordantes avec le champ région qui a été ajouté. Je réserve cette table pour plus tard.
Sur la sortie L je récupère les entrées pour lesquelles aucune concordance n’a été trouvée. C’est cette table sur laquelle je vais travailler dans la seconde étape.
Etape 2
Dans la 2ème étape je vais réaliser l’union entre la table sans correspondance (sortie L) et la table de référence (sortie R). Je me débarrasse d’abord de toutes les colonnes superflues car l’union ne peut être réalisée que sur des tables identiques.
Etape 3
La 3ème étape est le fuzzy matching à proprement parler. Le fuzzy matching est exécuté en utilisant la fonction « Name » sous Alteryx L’algorithme qui est derrière est de type double métaphone (plus d’infos ici). Il s’agit donc, comme sous Tableau Prep Builder, d’un algorithme qui se base sur la similarité phonétique.

Résultats : Alteryx vs. Anatella
En fin de processus j’ai extrait la liste des entrées pour lesquelles une correspondance avait été trouvée. Sur la base de cette liste (à télécharger ici) on peut effectuer une comparaison avec les résultats fournis sous Anatella avec la méthode de Dice.
Avec un seuil de matching à 75% sous Alteryx, le fuzzy matching permet de réconcilier 11 entrées sur 20 (voir tableau ci-dessous). Très logiquement, l’algorithme de type double métaphone produit un faux positif en confondant le Congo (Congo Brazzaville) et la République Démocratique du Congo. La même erreur est faite par la méthode de Dice.
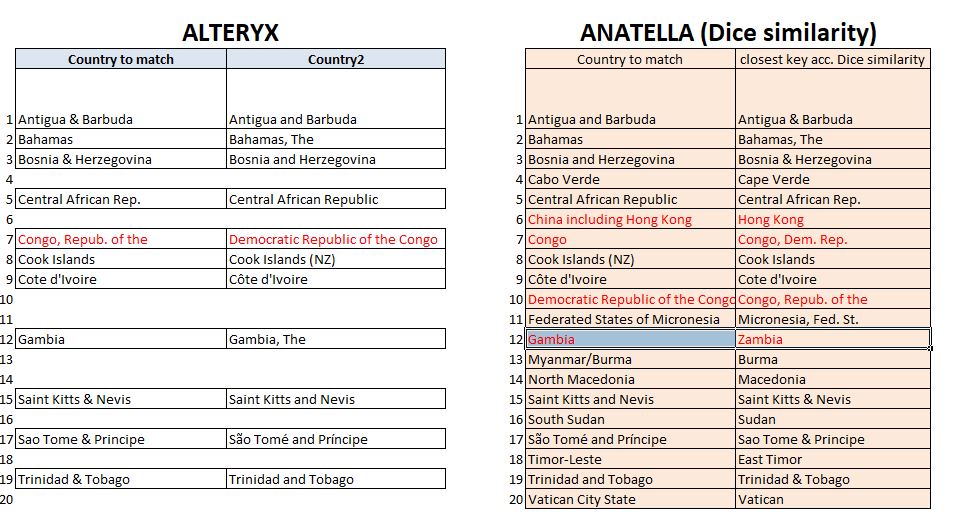
Sans spécifier de seuil, nous obtenions 16 réconciliations correctes sur 20 avec la méthode de Dice sous Anatella.

Conclusion

L’algorithme de fuzzy matching d’Alteryx produit des résultats moyens dans le cas étudié. L’algorithme de Dice, disponible dans l’ETL Anatella, donne de bien meilleurs résultats.
En outre le processus de fuzzy matching sous Alteryx oblige à des manipulations (union) qui sont inutiles. Le processus sous Anatella est beaucoup plus simple et efficace.




