

Dans un précédent article j’ai partagé avec vous une solution pour réaliser un fuzzy matching entre 2 tables différentes. J’avais alors comparé 2 solutions d’ETL (Extract Transform Load). Tableau Prep Builder n’avait pas permis d’aboutir au résultat désiré. Je m’étais donc tourné vers Anatella. Dans l’article d’aujourd’hui j’explore les différents algorithmes de Fuzzy Matching disponibles dans cet outil et leurs résultats. Comme vous le verrez, un algorithme ressort grand gagnant de la confrontation.
 Introduction
Introduction
 Introduction
IntroductionQuand vous souhaitez faire une jointure entre plusieurs tables, vous avez 2 solutions. Soit votre clé de jointure suit exactement la même nomenclature dans l’une et l’autre table; soit ce n’est pas le cas. Si vous êtes dans le cas béni de la 1ère situation, passez votre chemin. Cet article ne vous apprendra rien. Si par contre vous êtes dans le 2ème cas (ou simplement curieux), je vous souhaite une bonne lecture.
Algorithmes de fuzzy matching
 Algorithmes de fuzzy matching
Algorithmes de fuzzy matchingDans le cas d’étude que je vous propose, le fuzzy matching est réalisé sur une clé de jointure qui contient des noms de pays.
Il existe de nombreuses méthodes de calcul de similarité entre 2 entités. Ce que j’aime bien dans Anatella, c’est que contrairement à d’autres ETL, il vous propose de choisir entre 4 méthodes :
- distance de Damereau Levenshtein
- similarité de Damereau Levenshtein (la même chose que la distance même bornée entre 0 et 1)
- similarité de Jaro Winkler
- similarité de Dice
Il existe bien entendu d’autres méthodes de calcul de similarité. Raffael Vogler donne un bon aperçu des différentes techniques disponibles dans le package « stringdist » pour R.
Similarité de Jaro-Winkler
La méthode date de 1999 et est une évolution de la méthode de Jaro (1989). Le score obtenu varie entre 0 et 1. Il est calculé en comparant les caractères correspondants dans une chaîne de caractères puis dans l’autre, et en tenant compte des transpositions de caractères.
Distance de Damereau Levenshtein
La méthode est ancienne (1964) et permet de calculer le nombre d’étapes nécessaires pour transformer une chaîne de caractères a en une chaîne b. Les opérations permises sont la suppression, l’insertion, la substitution d’un seul caractère, la transposition de 2 caractères adjacents. La distance calculée est donc un nombre entier qui correspond aux nombres d’étapes nécessaires à la transformation (0 quand les chaînes a et b sont identiques).
Similarité de DICE
La méthode est également ancienne (1948) et consiste en une simple comparaison des digrammes. Le coefficient est proche de l’indice de Jaccard. Je vous renvoie à Wikipédia pour quelques exemples parlants.
Les résultats
 Les résultats
Les résultatsVoici les résultats. Je rappelle que ces derniers ne sont pas transposables à n’importe quel cas de figure. Chaque cas doit être étudié préalablement pour trouver la méthode qui convient le mieux. Dans le cas présent nous parlons de fuzzy matching entre des noms de pays répondant à différentes nomenclatures. Je vous renvoie à mon article de la semaine dernière pour la liste des cas de figure.
Pour comparer les résultats produits par les différents algorithmes, j’ai simplement modifié un petit peu le flux dans l’ETL (Anatella) pour mettre en parallèle les 4 types de « fuzzy joints » proposés. Le process est en bleu sur le diagramme ci-dessous (cliquez dessus pour l’agrandir).
Pour faciliter la lecture j’ai exporté les résultats dans un fichier Excel (à télécharger ici).
Les résultats sont parfois étonnants.
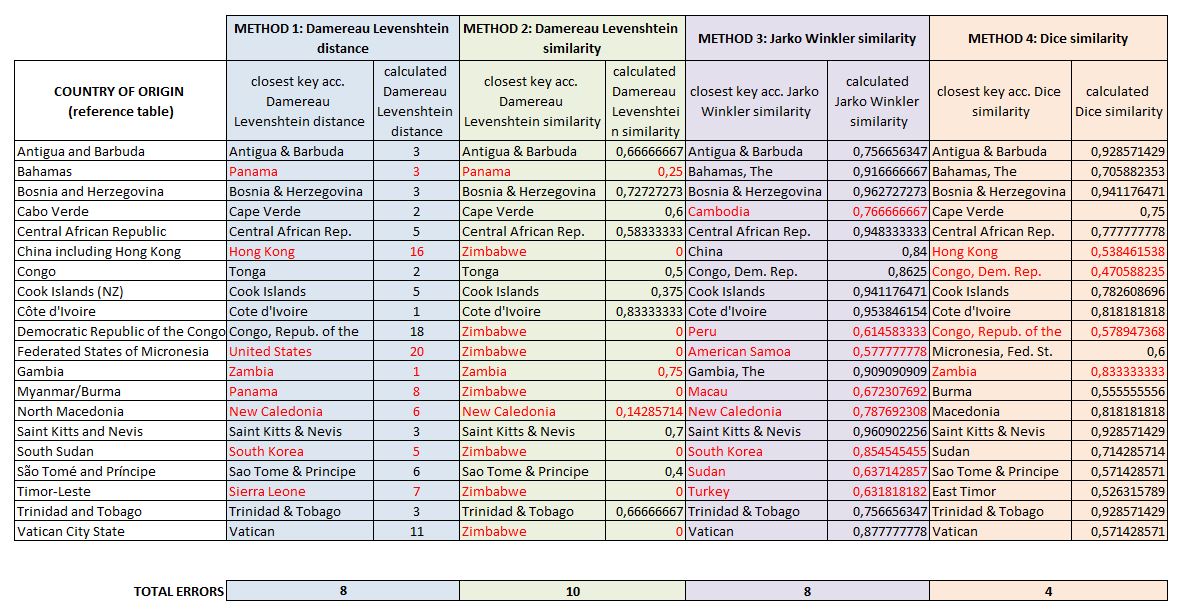
La méthode 2 semble avoir une prédilection pour le Zimbabwe et diffère d’ailleurs de la méthode 1 (à priori proche). On voit que les erreurs de classification sont parfois grossières (South Sudan / South Korea).
La méthode 3 (Jaro Winkler) est légèrement meilleure, mais les erreurs de classification sont au final encore trop nombreuses.Toutefois elle présente un gros avantage (voir prochain paragraphe).
La méthode 4 (similarité de Dice) donne les meilleurs résultats. La mauvaise classification de Hong-Kong peut être attribuée à des raisons évidentes (voir l’entrée dans la table de référence). L’erreur sur « Gambia » s’explique facilement par l’approche par diagrammes propre à la méthode de Dice-Sorensen.
Définition d’un coefficient de seuil
Afin d’éviter de se retrouver avec des faux positifs ou des faux négatifs, il est utile de définir un coefficient de seuil pour rejeter les résultats qui nécessitent un traitement manuel.
Pour la méthode de Damereau Levenshtein (méthodes 1 et 2) on voit que cette approche n’est pas très efficace car l’algorithme donne des faux positifs avec des distances calculées peu élevées (voir Bahamas, Gambia, North Macedonia, South Sudan).
Pour Dice, la définition d’un seuil aux alentours de 0,5 n’aurait pas permis de détecter les 2 faux positifs et aurait livré également un faux négatif (Congo).
Pour la méthode 3, la définition d’un seuil à 0,8 aurait permis d’éliminer tous les concordances ratées mais aurait également généré un faux négatif (Trinidad et Tobago).
 Conclusion
Conclusion
 Conclusion
ConclusionLa méthode de Dice (également appelée méthode de Sorensen) livre dans cet exercice les meilleurs résultats pour réaliser une jointure par fuzzy matching entre des noms de pays. La méthode de Jaro-Winkler permet quant à elle de définir un seuil à 0,8 qui évacue avec précisément les résultats non concordants.





