Artikelen ingedeeld onderData science
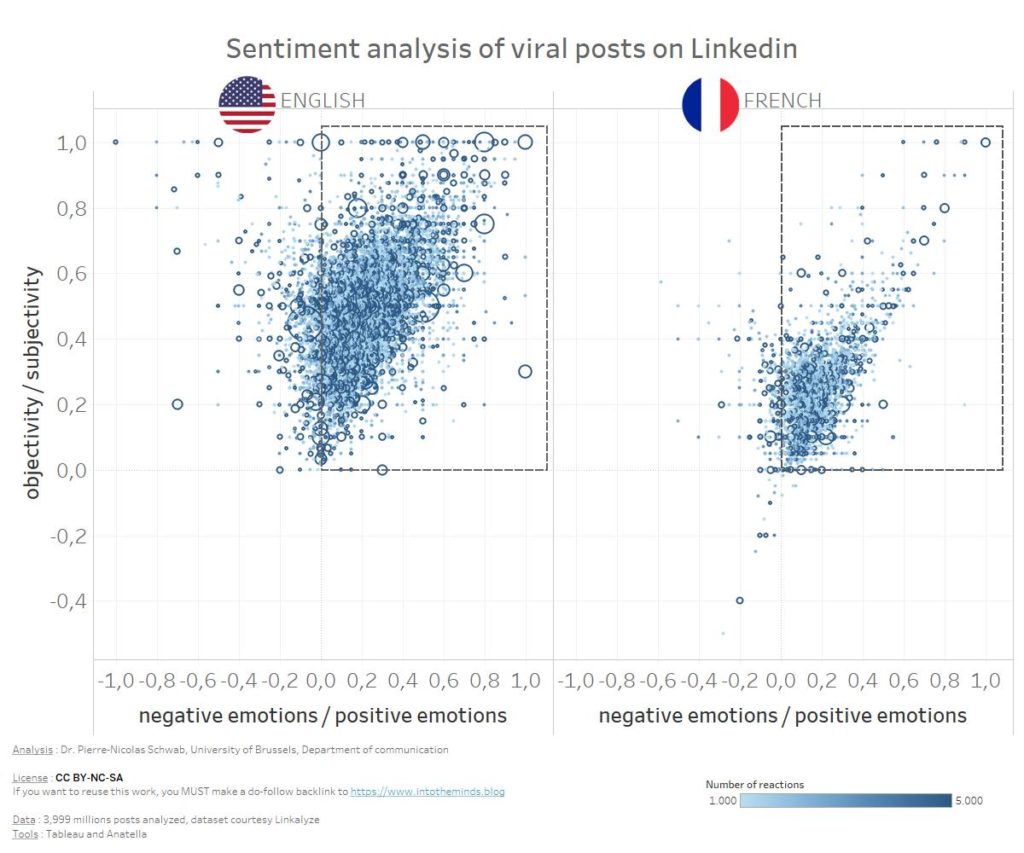
LinkedIn: geuite gevoelens en hun effect op viraliteit
Door Pierre-Nicolas Schwab •
Iedereen is het erover eens dat de inhoud van LinkedIn-berichten cruciaal is om viraal te kunnen gaan. Vandaag geef ik geen antwoord de vraag "Waar moet u het over hebben op LinkedIn?" maar eerder op "Hoe moet u het erover…

De 11 uitdagingen van datavoorbereiding en data wrangling
De gebeurtenissen van 2020 hebben de verschuiving naar telewerken en digitale relaties versneld. Maar digitalisering leidt ook tot een andere transformatie, die van de analytische transformatie. Om deze datarevolutie het hoofd te bieden, stel ik vast dat bedrijven niet altijd…
Data preparation: hoe 85% besparen op verwerkingstijd
In een eerder artikel vergeleek ik 4 ETL-oplossingen voor het verwerken van een bestand van een miljard rijen. Vandaag test ik het effect van SSD en proprietary-bestandsformaten op de verwerkingssnelheid in Alteryx, Tableau Prep, Talend en Anatella. De resultaten zijn…
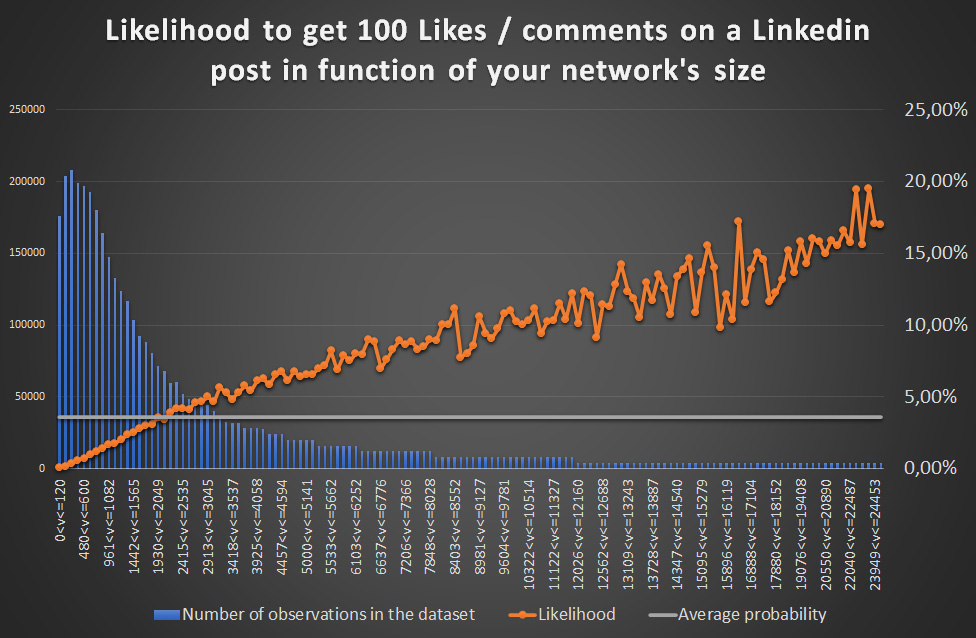
3 factoren die 55% van het succes van uw LinkedIn-berichten bepalen
Door Pierre-Nicolas Schwab •
Begrijpen hoe het algoritme van LinkedIn werkt is een noodzaak om zichtbaar te blijven op dit sociale netwerk. In dit artikel onthul ik de resultaten van een analyse die ik maakte van 4.599 miljoen LinkedIn-berichten in 193 landen. De resultaten…
De belangrijkste factor voor de viraliteit van uw LinkedIn-berichten
Door Pierre-Nicolas Schwab •
Na het effect van emoji's en het aantal woorden op de viraliteit van LinkedIn-berichten te hebben bekeken, is het tijd om de allerbelangrijkste factor te onthullen die alle anderen verplettert. Deze factor is goed voor 1/3 van het succes van…
LinkedIn: het verrassende effect van emoji’s op het viraal gaan van berichten
Door Pierre-Nicolas Schwab •
Is het nodig om emoji's in je LinkedIn-berichten te plaatsen en zo ja, hoeveel? In het artikel van vandaag geef ik u de resultaten van een onderzoek dat ik uitvoerde op 4,599 miljoen LinkedIn-berichten. Deze studie volgt op een eerdere…
Benchmark: welke ETL kiezen om grote bestanden te verwerken
Door Pierre-Nicolas Schwab •
Als we het over data preparation hebben, zien we dat een groot deel van de processen nog altijd offline verloopt, met archieven die uit relationele gegevensbanken worden getrokken. En wat de data engineers betreft die deze archieven behandelen, is het…