

Als u gegevens bewerkt met het oog op analyse- en/of visualisatie heeft u wellicht al met dit probleem te maken gehad. U moet een verbinding maken tussen 2 databases, maar de gegevens in het referentieveld zijn niet precies hetzelfde. Verschillen in spelling, verschillende benamingen, … er zijn tal van verschillende oorzaken. Tijdens een onderzoek dat ik uitvoer om migratiestromen te visualiseren, werd ik met dit probleem geconfronteerd. Ik zocht een oplossing in ETL (Extract – Transform – Load) voor fuzzy matching. Laat met het uitleggen.
Samenvatting
- Inleiding
- Het probleem
- Oplossing 1 met Table Prep Builder (spoiler: het werkt niet)
- Oplossing 2 met Anatella (spoiler: het werkt)
- Conclusie
 Het probleem
Het probleem

Het probleem is dat een landnaam lang geen constante is. Hier enkele voorbeelden:
- “Cabo Verde” in de nationale taal van het land, “Cap Verde” in het Engels
- “Antigua en Barbuda” in het ene bestand, “Antigua & Brabuba” in het andere
- “Bahama’s” en “The Bahama’s”
- “Central-African Republic” en “Central-African Rep.”
- “Cook Islands (NZ)” en “Cook Islands”
- “Côte d’Ivoire” en “Cote d’Ivoire
Alvorens de liefhebbers van “search and replace” Excel me op die functie wijzen, moet ik eerst aangeven dat ik op zoek was naar een oplossing die minder vervangingen met zich mee zou brengen.
U begrijpt dat ik een paar uur had kunnen besteden aan het opschonen van mijn database en het laten “matchen” van gegevens, zodat de koppeling kon werken. Maar ik zocht dus een elegantere oplossing.
Het probleem
Het probleem is dat een landnaam lang geen constante is. Hier enkele voorbeelden:
- “Cabo Verde” in de nationale taal van het land, “Cap Verde” in het Engels
- “Antigua en Barbuda” in het ene bestand, “Antigua & Brabuba” in het andere
- “Bahama’s” en “The Bahama’s”
- “Central-African Republic” en “Central-African Rep.”
- “Cook Islands (NZ)” en “Cook Islands”
- “Côte d’Ivoire” en “Cote d’Ivoire
Alvorens de liefhebbers van “search and replace” Excel me op die functie wijzen, moet ik eerst aangeven dat ik op zoek was naar een oplossing die minder vervangingen met zich mee zou brengen.
U begrijpt dat ik een paar uur had kunnen besteden aan het opschonen van mijn database en het laten “matchen” van gegevens, zodat de koppeling kon werken. Maar ik zocht dus een elegantere oplossing.
Oplossing 1 (die niet werkt)

Aangezien ik als doel had mijn gegevens in Tableau te visualiseren, probeerde ik eerst Tableau Prep Builder. Het voordeel van Tableau Prep Builder is dat het ETL-proces grafisch verloopt en de problemen duidelijk worden weergegeven (Tableau Prep zet ze automatisch in het rood, zie hieronder). Ik heb problemen waar ik het hierboven over had in het geel gemarkeerd. Het is nog maar de vraag of het mogelijk is om de tabellen met elkaar te verbinden.
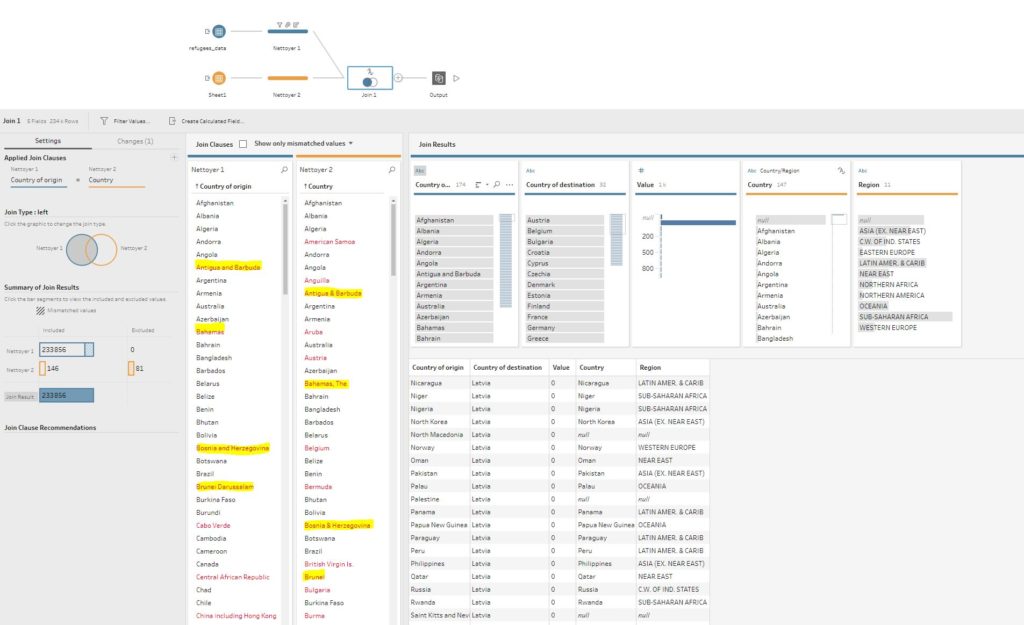
Later vond dit artikel tegen, waarin een methode van groepering door middel van fonetiek wordt beschreven. Deze optie is hier beschikbaar:
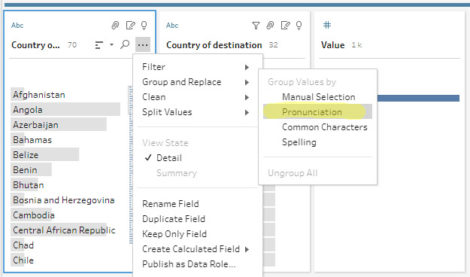
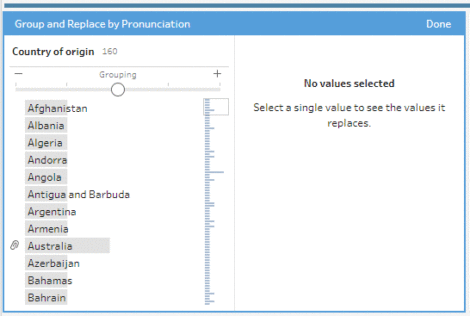
Groepen zijn nuttig binnen dezelfde tabel om variaties op te sporen. Zie hier voor de technische toelichting. Het gebruikte algoritme heet Metaphore 3 (open source, zie hier).
Het probleem is dat groeperingen alleen mogelijk zijn op één enkele tabel. Ik had dus eerst moeten koppelen, vervolgens groeperen en ten slotte handmatig ontdubbelen. Dit is mogelijk als het om enkele gegevens gaat, maar de methode zou niet schaalbaar zijn geweest.
Op naar de tweede oplossing.
Oplossing 2 (die werkt!)

Om mijn problemen van fuzzy matching op te lossen EN een oplossing te hebben die schaalbaar was, heb ik me vervolgens tot Anatella gewend.
Het voordeel van deze oplossing (naast het feit dat het gratis is voor kleine installaties) is dat het een koppelingstool heeft in combinatie met fuzzy matching. Als u weet hoe u moet werken onder Tableau Prep (of een andere ETL-tool) zult u ook hierin uw weg vinden. De look&feel is vrijwel hetzelfde (vensters, pijlen, parameters). Voor mij is het grote voordeel van Anatella de rijkdom van de voorgestelde functies (+/-300). Zo ziet het process om het probleem op te lossen er uit (klik om te vergroten).
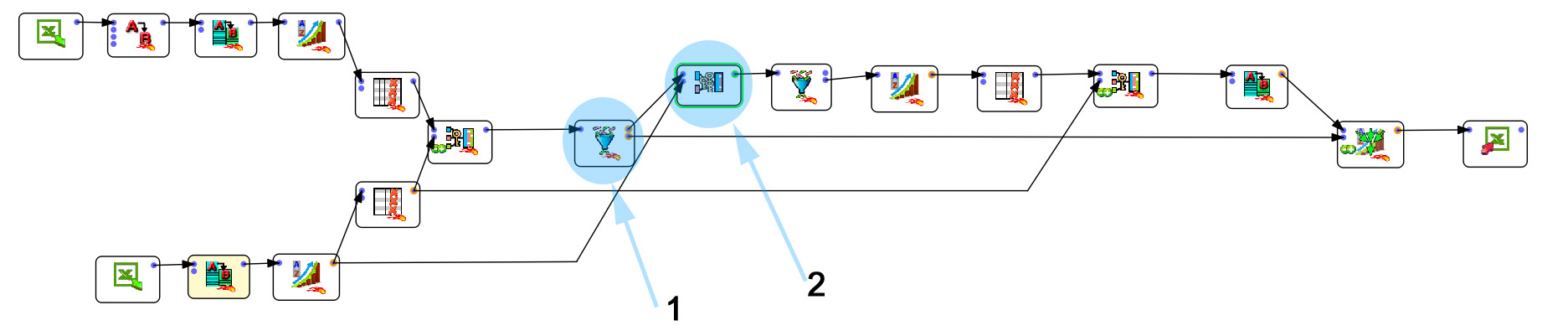
Ik ga niet het hele proces in detail bespreken, maar ik zal me richten op de belangrijkste onderdelen en natuurlijk de fuzzy matching.
- In stap 1 maak ik een scheiding tussen de entries waarvoor de koppeling goed ging (onderste tak) en de entries waarvoor geen match werd gevonden (bovenste tak).
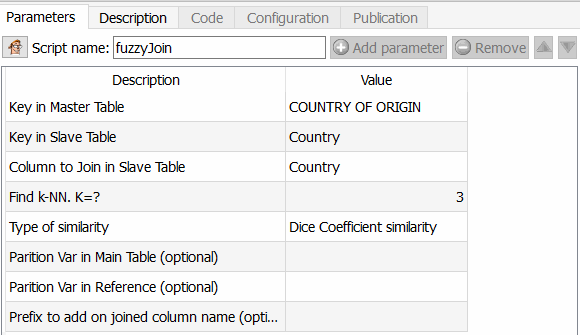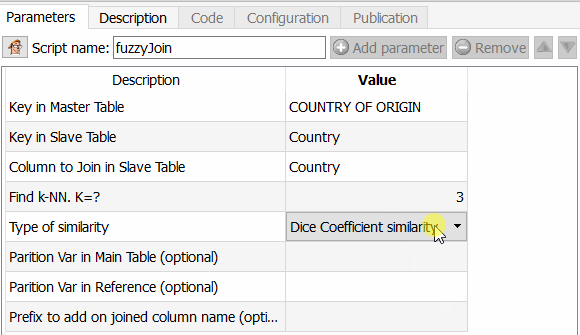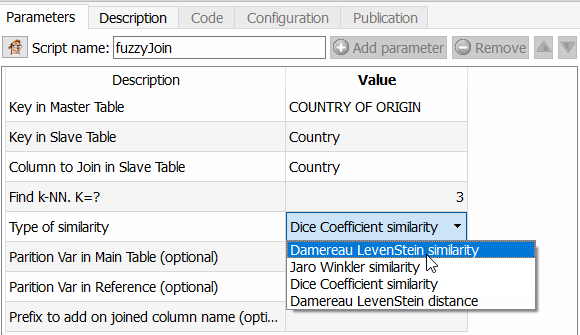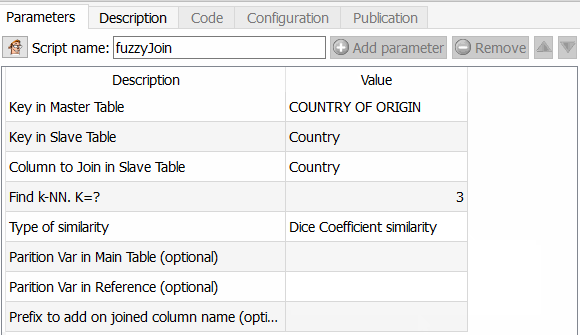
- In stap 2 pas ik de beroemde fuzzy matching tool toe.
Deze functie is interessant omdat u hiermee veel verder kunt gaan dan bijvoorbeeld Tableau Prep Builder, maar ook dan een ETL-tool zoals Talend. U kunt inderdaad het algoritme kiezen dat u moet toepassen om de overeenkomst tussen twee velden te berekenen. Aangezien Anatella de gelijkeniscoëfficiënt teruggeeft, hoeft u alleen maar een drempel te kiezen en deze toe te passen. De verschillende beschikbare algoritmen zijn de similariteitscoëfficiënt van Dice, de vergelijkingsmethode van Damereau Levenshtein, die van Jareau Winkler en de afstandsberekening van Damereau Levenshtein. Ik zal een afzonderlijk artikel wijden aan de vergelijking van deze verschillende methoden.
Een ander voordeel van Anatella is de snelheid. Het hele proces verloopt in 14,84 seconden (inclusief de fuzzy matching). Het koppelingsdeel (tot en met stap 1) loopt in 1,58 seconden daar waar de Table Prep Builder er 10 seconden voor nodig heeft.
bleau Prep Builder met 10 secondes.
 Conclusie
Conclusie

In het kort kunnen we stellen dat de vergelijking van de 2 ETL-tools bij mijn casestudy in het voordeel van Anatella uitviel (het samenvoegen van 2 tabellen met fuzzy matching). Helaas is de fonetische groepering die Table Prep Builder aanbiedt niet aangepast aan de creatie van een koppeling. Ze kan slechts op één tabel worden toegepast en vereist een handmatige filtering, die niet schaalbaar is.

