

Algoritmen zijn ons leven binnengedrongen. Desondanks lokken ze soms hatelijke reacties van gebruikers uit. Een in september 2022 gepubliceerd artikel (Engelse site) biedt een zeer interessant analysekader voor wie in dit verschijnsel geïnteresseerd is. In dat artikel analyseer ik de vier redenen voor haatreacties tegen algoritmen en illustreer ze met vele voorbeelden.
Als u maar 30 seconden heeft
- Algoritmen genereren soms gewelddadige haatreacties van gebruikers
- Er zijn 4 redenen waarom de frustratie van gebruikers omslaat in verbaal geweld:
- gebrek aan inzicht over de werking van het algoritme en verkeerd begrip van de resultaten
- algoritmische fouten
- de belangen van de gebruiker versus die van het algoritme
- gebrek aan controle over het algoritme
- Er bestaan oplossingen
- heroverweging van het ontwerp van algoritmen om de tevredenheid van de gebruiker te maximaliseren
- algoritmen transparanter maken en uitleggen hoe ze werken
- mogelijkheden bieden om de werking van het algoritme aan te passen
De haat tegen algoritmen komt op verschillende manieren tot uiting. De auteurs van de studie halen de boost van de hashtag #RIPtwitter aan toen het platform besloot een aanbevelingsalgoritme te gebruiken in plaats van berichten in antechronologische volgorde weer te geven. Gebruikers reageerden toen heftig, zoals te zien is in onderstaande grafiek (bron: Trendsmap, Engelse site). We zien ook dat de hashtag #RIPtwitter van tijd tot tijd weer opduikt, tijdens pieken van haat tegen het platform.

Het fenomeen manifesteerde zich in 2017 om dezelfde reden (Engelse site) ook op Instagram met de hashtag #RIPinstagram. Het mechanisme van algoritmische aanbevelingen lijkt dus negatieve gevoelens te kristalliseren.
Aanbevelingsalgoritmen liggen echter aan de basis van het succes van veel bedrijven (Netflix, Google, Tik Tok) en dragen ook bij aan de klanttevredenheid. Het is daarom zeer interessant om de redenen die gebruikers tot deze hatelijke reacties aanzetten in twijfel te trekken.

Verklaring 1: gebrek aan inzicht

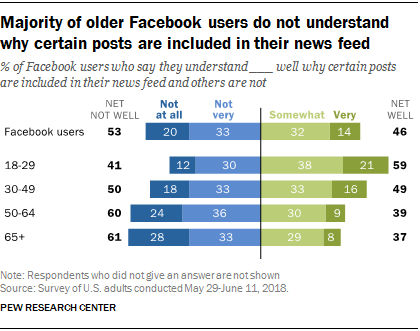
Het gebrek aan inzicht in de werking van algoritmen is een feit. In een in 2018 gepubliceerd onderzoek wees het Pew Research Center er al op dat 53% van de Facebook-gebruikers niet begreep hoe het algoritme dat hun “feed” voedt, werkte. Dit percentage bedroeg zelfs 60% bij de 50-64-jarigen en 61% bij de 65-plussers.
Begrijpen hoe een aanbevelingsalgoritme werkt is nog altijd een complex onderwerp, voorbehouden aan enkele ingewijden. Het vergroten van het inzicht van gebruikers in de werking van een algoritme heeft echter reële voordelen. Zoals dit experiment (Engelse site) bewijst, verhoogt inzicht in de werking van het algoritme het vertrouwen en de tevredenheid van de gebruiker aanzienlijk.

Verklaring 2: algoritmische fouten en vertekeningen
Algoritmen creëren soms situaties van extreem geweld tegen gebruikers. Algoritmefouten kunnen ernstige gevolgen hebben, zoals in het geval van de man (Engelse site) die in Michigan werd gearresteerd na een foutieve algoritmische identificatie. Andere voorbeelden zijn de afwijzing van kandidaat-huurders (Engelse site) na een algoritmische controle van hun profiel of de hee financiële verlies van Nederlandse burgers (Franse site) nadat de belastingdienst een algoritme foutief gebruikte.
Ook de algoritmen die in de onderwijssector worden gebruikt, worden vaak bekritiseerd. In Frankrijk werd het selectiealgoritme voor universiteitskeuze gemanipuleerd, waardoor ongelijkheden tussen kandidaten ontstonden op het moment van hun academische oriëntatie.
Ten slotte kunnen sommige gemeenschappen algoritmische discriminatie ervaren wanneer zij het gevoel hebben dat hun identiteit een oneerlijk doelwit is. Dit was het geval op Tik Tok waar LGBTQIA+ makers het gevoel hadden dat het algoritme hun inhoud onzichtbaar (Engelse site) maakte. Een controle (Engelse site) wees uit dat deze kritiek terecht was. Omgekeerd kan een algoritme inhoud ook overbelichten en toegankelijk maken voor een te groot publiek. Daarbij kunnen makers van inhoud door sommige gebruikers onder druk worden gezet.
Zoals u ziet, zijn er tal van risico’s verbonden aan het gebruik van aanbevelingsalgoritmen. Het evenwicht tussen toegevoegde waarde voor de gebruiker en risico’s is moeilijk te vinden.

Verklaring 3: de belangen van de gebruiker versus de belangen van het algoritme
Voorbeeld van Twitter
Gebruikers van een platform voelen zich soms “gemanipuleerd” door het algoritme. Een reeks Tweets van Elon Musk toont de omvang hiervan aan. In deze 3 tweets, gepubliceerd op 15 mei 2022, beschuldigt hij het algoritme van “het manipuleren van [gebruikers] op manieren die [zij] zich niet realiseren”. In zijn tweede tweet noemt hij de door Eli Pariser getheoretiseerde filterbubbel. Het algoritme van Twitter zou overtuigingen versterken en meningen de facto polariseren.
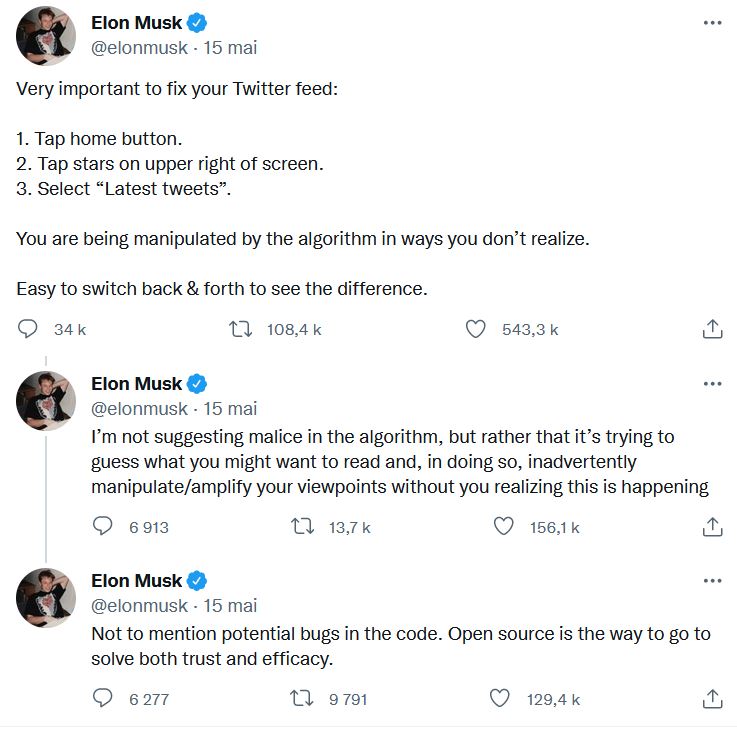
In dat geval zouden de belangen van het algoritme en de gebruikers niet op één lijn liggen. Deze stelling is twijfelachtig omdat, zoals we al hebben gezien, filterbubbels nog altijd een theoretische mogelijkheid zijn.
Voorbeeld van Spotify
Spotify is een ander voorbeeld van deze tegenstelling tussen de belangen van de gebruiker en het algoritme. Laten we allereerst niet vergeten dat Spotify een platform is dat audio-inhoud aanbiedt aan gebruikers en makers vergoedt op basis van het aantal luisterbeurten. Er moet dus een subtiel evenwicht worden gevonden tussen de tevredenheid van de gebruiker en die van de maker. De eersten willen luisteren naar inhoud die ze leuk vinden. Deze laatste willen zoveel mogelijk beluisterd (en dus aanbevolen) worden.
Het algoritme van Spotify staat dus voor een dilemma. Moet het de inhoud aanbevelen die de meeste kans op aantrekkingskracht heeft (meestal geproduceerd door de grote labels) ten koste van meer vertrouwelijke inhoud geproduceerd door onafhankelijke labels? Helaas bestaat er geen perfecte oplossing voor dit probleem. Omdat gebruikers bevoorrecht zijn (zij zijn degenen die betalen), kunnen onafhankelijke makers zich gefrustreerd voelen door het algoritme van Spotify.

Verklaring 4: gebrek aan controle
Het probleem van de controle over het algoritme is een terugkerende klacht van gebruikers, en een belangrijke bron van ontevredenheid. Sommige van de voorbeelden die wij hierboven hebben gegeven, kunnen daarmee in verband worden gebracht.
Elke verandering in het “algoritmische recept” leidt onvermijdelijk tot ontevredenheid. Dat hebben we gezien met de tweets van Elon Musk. Meer recentelijk is Instagram zwaar bekritiseerd vanwege de neiging om op TikTok te (Engelse site) lijken. Dit omvatte een buitensporige aanbeveling van “echte” inhoud. Door influencers werd een informele campagne (Engelse site) gestart om te eisen dat de wijzigingen werden teruggedraaid.
Het gebrek aan controle is ook voelbaar in het vermogen van het algoritme om uw geheimen te doorgronden zonder dat u bezwaar kunt maken. Dit is het geval op TikTok, waar de precisie van het algoritme gebruikers het gevoel geeft dat ze worden bespied (Engelse site).

Hoe kan het vertrouwen in algoritmen worden hersteld?
Algoritmen blijven door hun aard objecten die voor de gemiddelde persoon moeilijk te begrijpen zijn. Sommige zijn zo complex dat ze voor hun ontwerpers echte begripsproblemen opleveren. Hoe kunnen we in deze omstandigheden de epidermale reacties vermijden die bij sommige gebruikers kunnen optreden?
Er zijn drie aandachtsgebieden:
1/ Mensen centraal stellen bij het ontwerp van aanbevelingssystemen
De GDPR introduceerde het idee van “privacy-by-design”. Ontwerpers van algoritmen zouden van het hunne “satisfaction-by-design” moeten maken.
De meeste algoritmen zijn inderdaad ontworpen met het bedrijfsbelang voor ogen. Dit leidt tot gedrag dat schadelijk kan zijn voor de gebruiker (zie hier deze beschouwing over het einde van aanbevelingsalgoritmen).
2/ Algoritmen transparanter maken
De aanvaarding van de resultaten van het algoritme hangt af van een beter begrip van de manier waarop ze tot stand komen. Algoritmische fouten worden beter geaccepteerd als gebruikers weten waarom ze optreden. De tevredenheid zal groter zijn.
3/ Meer controle van de gebruiker over de algoritmen
De laatste gedachtegang bestaat erin gebruikers een beetje controle terug te geven om hun feeds te personaliseren. Er zijn steeds meer initiatieven, zoals het initiatief van LinkedIn om bepaalde inhoud of auteurs uit de feed te verwijderen. Hoe dan ook, als u hen geen controle geeft, zullen gebruikers proberen het algoritme te manipuleren. Er bestaan bijvoorbeeld studies over hoe het algoritme van LinkedIn werkt.





