

Dans l’article d’aujourd’hui, je voudrais présenter une nouvelle perspective sur l’évolution de la modélisation des comportements de consommation au cours des 30-40 dernières années. En particulier je traiterai des algorithmes de prédiction qui sont légion dans notre société tournée vers le Big Data.
Introduction
Comprendre le comportement des consommateurs n’est pas une préoccupation récente. La modélisation des comportements a longtemps été une priorité pour ceux qui étudiaient les marchés, aussi bien du côté des universitaires que des praticiens.
Dans les années 70 (et avant) les sciences sociales avaient la mainmise sur la définition de profils standard de consommateurs. Cela permettait de comprendre les évolutions de la société. Les progrès de l’informatique (et en particulier la démocratisation du calcul distribué) ont permis de se débarrasser lentement de l’analyse sociologique pour ne plus utiliser que les traces et les signaux laissés derrière eux par les consommateurs. Ces traces et signaux sont devenus autant d’indices nous permettant de modéliser plus finement les comportements. Le nombre de modèles distincts s’est multiplié grâce à la puissance de calcul jusqu’au point où un chaque consommateur peut désormais être modélisé individuellement. En d’autres termes, plutôt que de vous forcer à rentrer dans une case prédéfinie, nous pouvons désormais créer une boîte sur-mesure.
Feedbacks explicites et implicites
Sans les ordinateurs et les capacités de traitement avancées, la seule possibilité d’obtenir un instantané des comportements était de recueillir des évaluations explicites des utilisateurs : enquêtes, sondages, le but était de demander explicitement aux utilisateurs leur feedback sur tel ou tel aspect. Aujourd’hui le feedback explicite est encore largement utilisé mais il faut l’objet d’un traitement massif des données récoltées : notation d’un film, évaluation d’un hôtel ou un restaurant, note attribuée à un conducteur Uber, etc …
Alors, certes les feedbacks explicites sont toujours d’actualité. Mais en termes de volume de données traitées ce sont les traces implicites qui constituent le gros du volume.
Aujourd’hui, la plus grande partie des données analysées sont des traces implicites : la chanson que vous écoutez, le film vous regardez, les endroits où vous avez mis ce film en pause, lorsque vous avez fait un « fast forward ». Le système ne vous demande pas de vous exprimer explicitement ; vos actions sont assez d’éléments implicites qui permettent de modéliser votre comportement et de déduire des choses sur votre personne. C’est ce qu’on appelle l’inférence.
Explicite ou implicite: quoi choisir ?
Il n’y a pas de réponse à cette question. Les deux types variables sont nécessaires. Pourtant, en jetant un coup d’œil aux 30-40 dernières années, on peut voir une évolution nette entre ces deux types de données que tout oppose.
Avant l’émergence d’Internet les seules données qui étaient disponibles était de nature explicite. Mais avec le développement d’habitudes liées à l’utilisation d’internet, tout cela a changé. Aujourd’hui la priorité est accordée aux données implicites. Il y a plusieurs raisons à cela.
3 raisons pour lesquelles les données implicites domine le Big Data aujourd’hui
Raison n ° 1: le volume
Le volume de données implicites pouvant être collectées dépasse largement celui des données explicites et en plus il concerne tout le monde. Dans le monde de l’explicite, chacun est libre de répondre ou pas ce qui réduit le nombre de données collectées.
Raison 2: observation des comportements réels
Les données implicites ont ceci de remarquable qu’elles permettent d’observer la réalité des comportements et non une projection ou une intention de l’individu.
Raison n ° 3: les coûts
Collecter les données implicites est une tâche automatisée. Le seul coût qui y est lié est celui du stockage. Pour les données explicites il faut parfois en passer par le développement d’outils de collecte ad hoc pour sonder, demander une opinion, et cela a un coût.
Les données explicites sont-elles encore nécessaires ?
Une étude de marché minutieuse montre que les entreprises utilisant le Big Data à des fins de prédiction sont désormais toutes plus ou moins au même niveau en termes de modélisation. La prise en compte de variables explicites permet d’améliorer les modèles et de redonner un avantage concurrentiel. Un exemple marquant récent concerne les recommandations de YouTube. La possibilité est enfin donnée à l’utilisateur de donner un feedback négatif (« pas intéressé ») et ainsi d’éviter une recommandation du même type dans le futur.
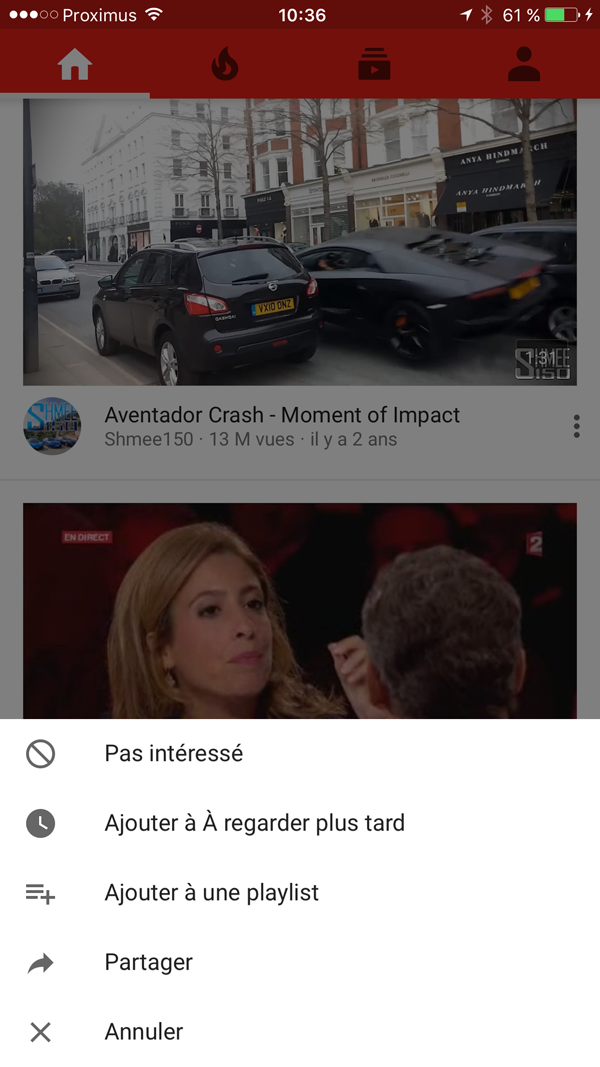
Les exemples de ce type sont légion comme l’a montré la récente conférence RecSys 2016 qui s’est tenue à Boston. J’ai particulièrement aimé l’exemple de Quora (voir photo ci-dessous). Comme vous pouvez voir l’utilisateur a plusieurs possibilité d’interagir explicitement avvec le contenu: upvote, downvote, commenter, partager.

Certaines formes de feedback explicite sont plus subtiles.
Quand un site Web affiche uniquement les premières lignes d’un article et vous demande de cliquer sur « lire la suite » / « lire l’article complet », il s’agit aussi d’une forme de feedback explicite qui donne à l’entreprise un signal que vous avez un intérêt prononcé pour le contenu qui vient de vous être proposé.

Pourquoi les variables explicites sont plus importantes que jamais
Les habitudes d’abord évoluent et, comme nous l’avons expliqué dans un autre article, les chercheurs en marketing ont montré que les utilisateurs ont tendance à se conformer aux attentes des algorithmes. Par conséquent, les signaux implicites perdent une partie de leur pouvoir de prédiction.
Plus important encore, dans les secteurs qui font un usage intensif des modèles prédictifs on se bat désormais pour des améliorations marginales. Tout le monde dispose des mêmes données, les data scientists passent d’une entreprise à l’autre, utilisent des modèles similaires. Les résultats ont tendance à se ressembler et il faut aller chercher ailleurs les critères de différenciation.
Cette dernière peut donc peut-être se cacher derrière la variété des données collectées. D’où l’accent mis actuellement sur les variables explicites comme un moyen d’améliorer les modèles.





