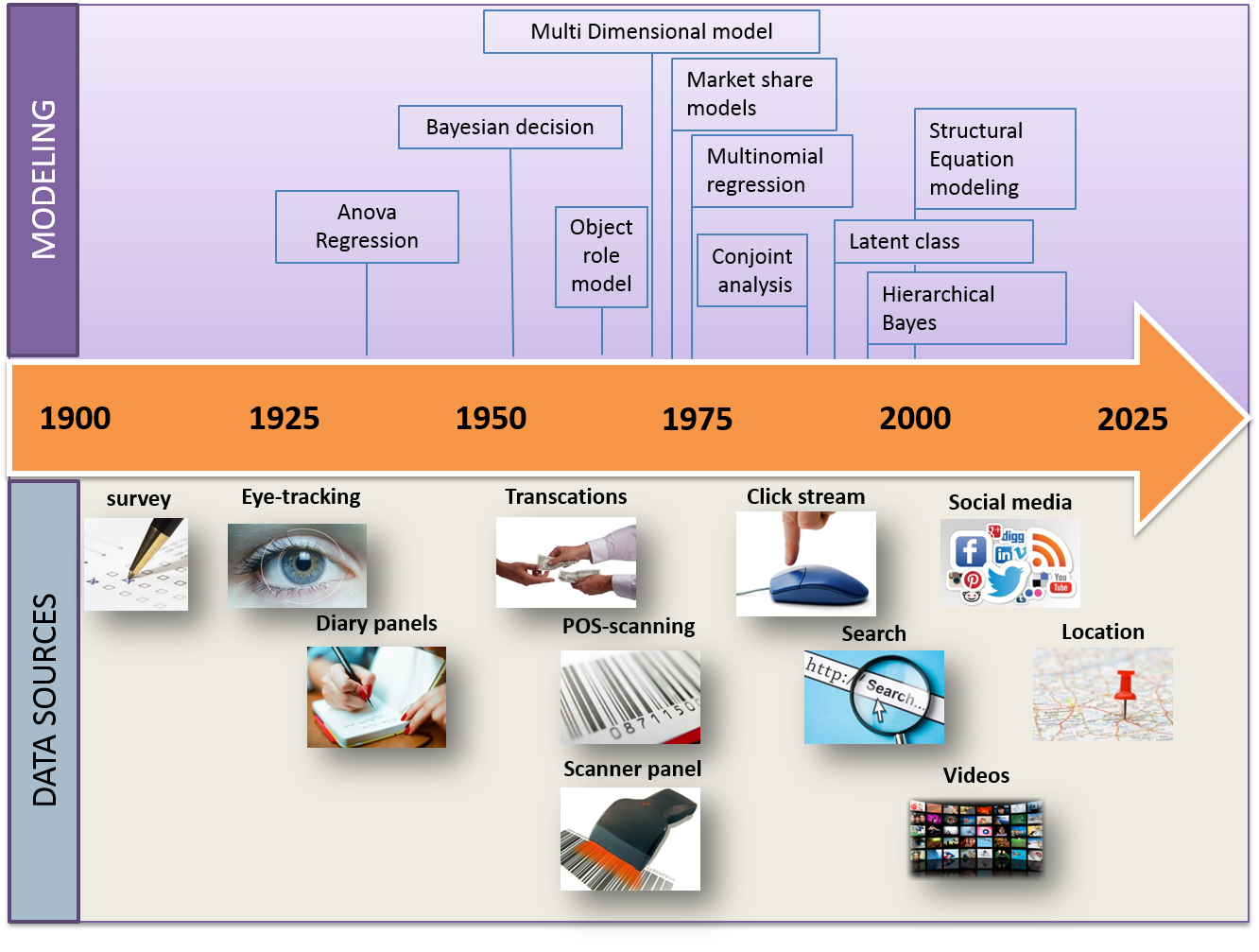
Lors de la dernière conférence EMAC 2016, Michel Wedel a donné une brillante démonstration de la façon dont les méthodes de collecte de données ont évolué au cours des 100 dernières années et comment les méthodes de modélisation ont changé. Sa représentation graphique de l’histoire du (Big) Data était en fait si synthétique et intéressante que j’ai pensé utile de la reproduire ici.
Tout a commencé dans les années 1920 avec des enquêtes (formulaires quantitatifs) et des méthodes simples de régression. En 100 ans les volumes n’ont fait qu’augmenter et les méthodes de modélisation ont suivi cette évolution.
Les chercheurs de Microsoft montrant que le pouvoir prédictif augmente avec le volume de données, on peut toutefois se demander si un besoin existe toujours pour des modèles plus complexes. En général d’ailleurs, ces modèles sont le produit du travail d’universitaires ayant seulement accès à de petits échantillons (par rapport à ceux de l’industrie). Quel est dès lors leur pertinence et leur utilité dans le contexte actuel d’inflation des volumes (l’infobésité) ?
Je n’ai pas de réponse à cette question. Je ne peux que répéter qu’en matière de Big Data l’écart se creuse entre les universitaires et les praticiens. Et malheureusement ce n’est pas dans le bon sens.