

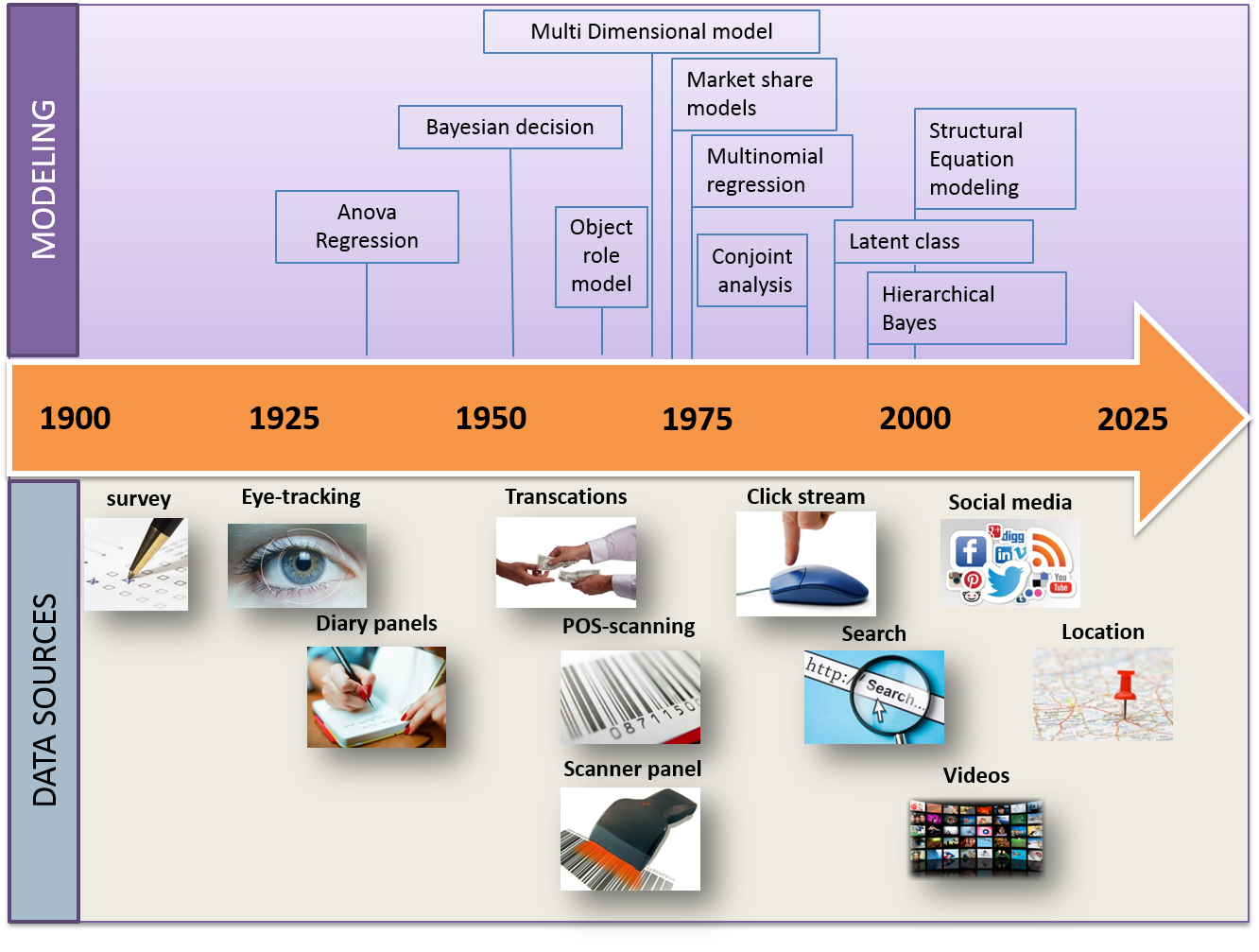
Tijdens de EMAC 2016-conferentie gaf Michel Wedel een briljante demonstratie over de wijze waarop gegevensverzameling in de laatste eeuw is geëvolueerd en hoe methodes van modellering zijn gewijzigd. Zijn grafische voorstelling van de geschiedenis van (Big) Data was zo beknopt en interessant dat ik het nuttig vond ze hier weer te geven.
Alles begon in de jaren ’20 met enquêtes (kwantitatieve formulieren) en eenvoudige regressiemethodes. In 100 jaar tijd bleef het volume aan gegevens maar stijgen en de modelleringsmethodes volgden die trend.
Onderzoekers van Microsoft toonden aan dat het voorspellend karakter beter wordt naarmate het aantal gegevens stijgt; men kan zich dus afvragen of er altijd nood is aan almaar complexere modellen. Bovendien zijn deze modellen over het algemeen het resultaat van universitairen die slechts toegang hebben tot kleine monsters (in vergelijking met die van de bedrijfswereld). Wat is dus de relevantie en zin ervan in de huidige context van sterk toenemende aantallen gegeven (infobesitas)?
Dat is een vraag die ik niet kan beantwoorden. Ik kan alleen maar herhalen dat betreffende de Big Data er een steeds grotere kloof ontstaat tussen universitairen en mensen op het werkveld. En dat gaat helaas niet de goede richting uit.





![Illustratie van onze post "Digitalisering: voedingsbedrijven lopen achter [Studie]"](/blog/app/uploads/marche-alimentation-bio-long-120x90.jpg)