

Si vous manipulez des données à des fins d’analyses et/ou de visualisations, vous avez sans doute déjà rencontré ce problème. Vous devez faire une jointure entre 2 bases de données mais les entrées dans le champ de référence ne sont pas exactement les mêmes. Différences d’orthographe, nomenclatures différentes, … les raisons sont multiples et variées. Dans le cadre d’une recherche que je fais pour visualiser les flux migratoires, j’ai été confronté à ce problème. J’ai dû le résoudre en utilisant une solution d’ETL (Extract – Transform – Load) gérant le fuzzy matching. Je vous explique comme j’ai fait.
Sommaire
- Introduction
- Le problème
- Solution 1 avec Tableau Prep Builder (spoiler : ça marche pas)
- Solution 2 avec Anatella (spoiler : ça marche)
- Conclusion
 Introduction
Introduction

Dans le cadre d’un projet personnel sur la visualisation des flux migratoires en Europe, j’ai obtenu des chiffres de l’Union Européenne (la base de données a 242500 lignes). La base de données détaille le nombre de migrants en fonction de leur pays d’origine et de leur pays de destination. D’un côté vous avez donc pas loin de 200 pays d’origine, et de l’autre une trentaine de pays de destination. Il m’a donc semblé opportun de visualiser ces flux à un niveau supérieur de granularité : la région d’origine.
J’aurais pu faire des groupes de pays directement dans Tableau mais quand vous avez 200 entrées c’est fastidieux (et pas forcément exempt d’erreurs). J’ai donc préféré chercher une base de données des différents pays du globe et de la région « officielle » à laquelle ils sont rattachés. J’ai trouvé ce référentiel sur le site de l’organisation mondiale du commerce.
Le problème
Le problème c’est qu’un nom de pays est loin d’être une constante. Voici quelques exemples :
- « Cabo Verde » dans la langue nationale du pays, « Cap Verde » en anglais
- « Antigua et Barbuda » dans un fichier, « Antigua & Brabuba » dans l’autre
- « Bahamas » et « The Bahamas »
- « Central African Republic » et « Central African Rep. »
- « Cook Islands (NZ) » et « Cook Islands »
- « Côte d’Ivoire » et « Cote d’Ivoire »
Avant de me faire alpaguer par les aficionados du « search and replace » dans Excel, précisons tout de suite que je cherchais une solution qui soit plus économe en termes de transformations.
Bref, vous l’aurez compris, j’aurais pu passer quelques heures à nettoyer ma base de données et à faire « matcher » les entrées pour que la jointure puisse fonctionner. Mais j’avais besoin d’une solution plus élégante.
Solution n°1 (celle qui n’a pas marché)

Comme mon intention était de visualiser mes données dans Tableau, la première solution que j’ai tentée consistait à utiliser Tableau Prep Builder. L’avantage de Tableau Prep Builder c’est que le process d’ETL est graphique et que les problèmes vous sautent aux yeux (voir ci-dessous, Tableau Prep vous les met automatiquement en rouge). J’ai surligné en jaune ceux dont je parlais plus haut. Restez à savoir si un fuzzy join entre tables était possible.
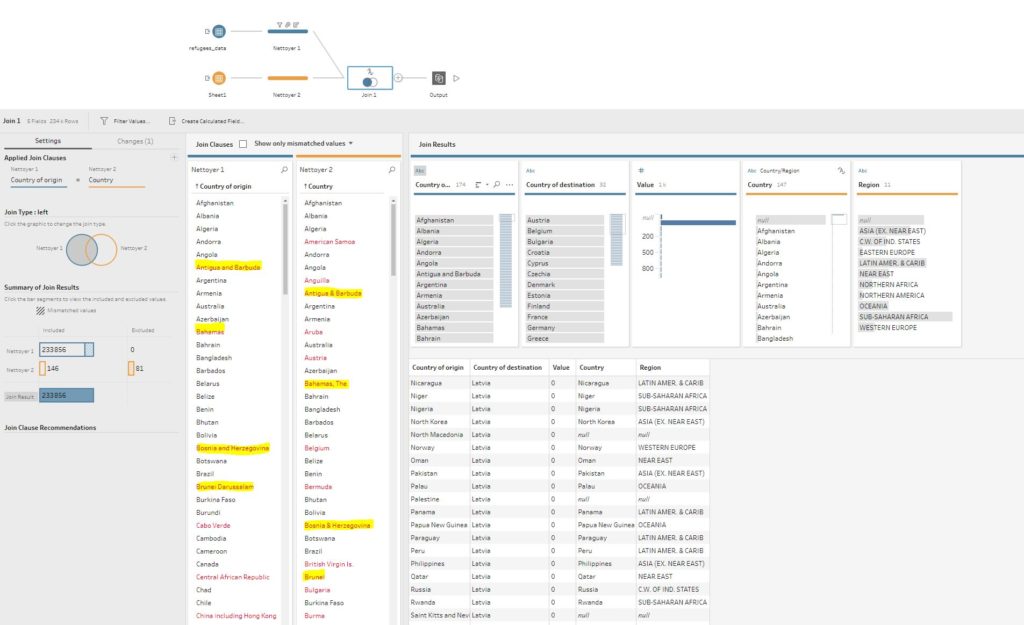
Quelques recherches plus tard, je suis tombé sur cet article qui décrit une méthode de regroupement par prononciation. Cette option est accessible ici :
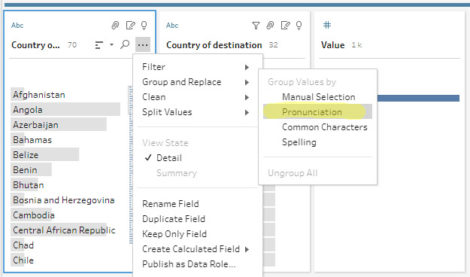
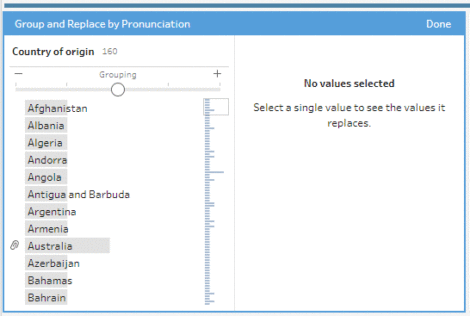
Les regroupements sont utiles à l’intérieur d’une même table pour détecter les variations. Les explications techniques sont ici. L’algorithme utilisé s’appelle Metaphore 3 (open source, voir ici).
Le souci c’est que les groupements ne sont possibles que sur une seule table. J’aurais donc dû faire une jointure, ensuite un regroupement, pour finir par une déduplication manuelle. C’est possible quand vous avez quelques entrées mais la méthode n’aurait pas été scalable.
Il est temps de vous parler de la 2ème solution.
Solution n°2 (celle-là elle a marché !)

Pour résoudre mes problèmes de fuzzy matching ET avoir une solution qui soit « scalable », je me suis tourné ensuite vers Anatella.
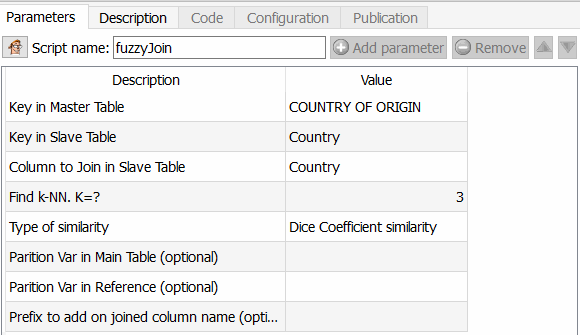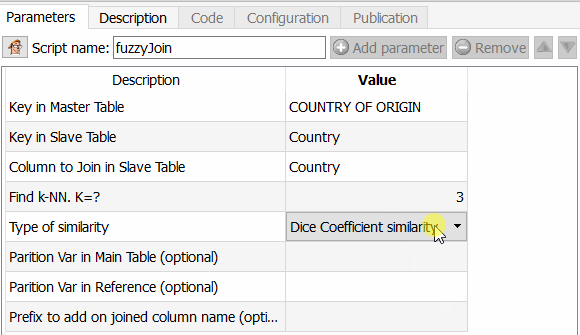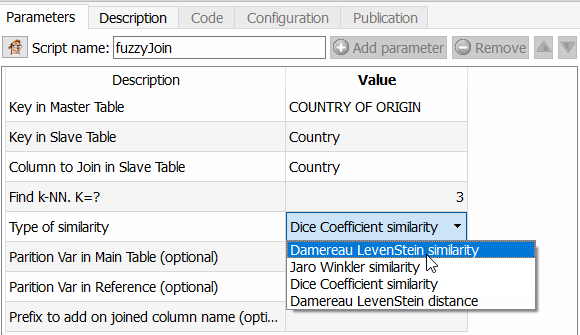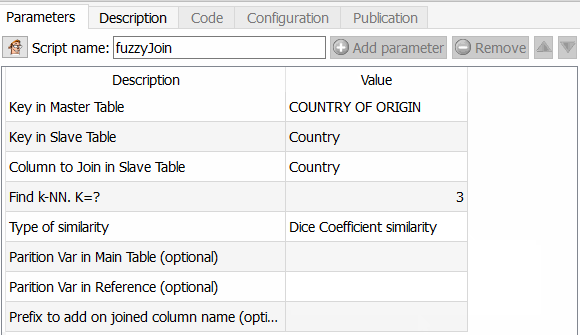
L’avantage de cette solution (outre qu’elle est gratuite pour les petites installations) c’est qu’elle dispose d’un outil de jointure couplé avec du fuzzy matching. Si vous savez travailler sous Tableau Prep (ou n’importe quel autre ETL) vous ne devriez pas être dépaysé. Le look&feel est à peu près le même (des boîtes, des flèches, des paramètres). Pour moi le gros avantage d’Anatella c’est la richesse des fonctionnalités proposées (+/-300). Voilà à quoi ressemble le flux mis en place pour résoudre le problème (cliquez dessus pour l’agrandir).
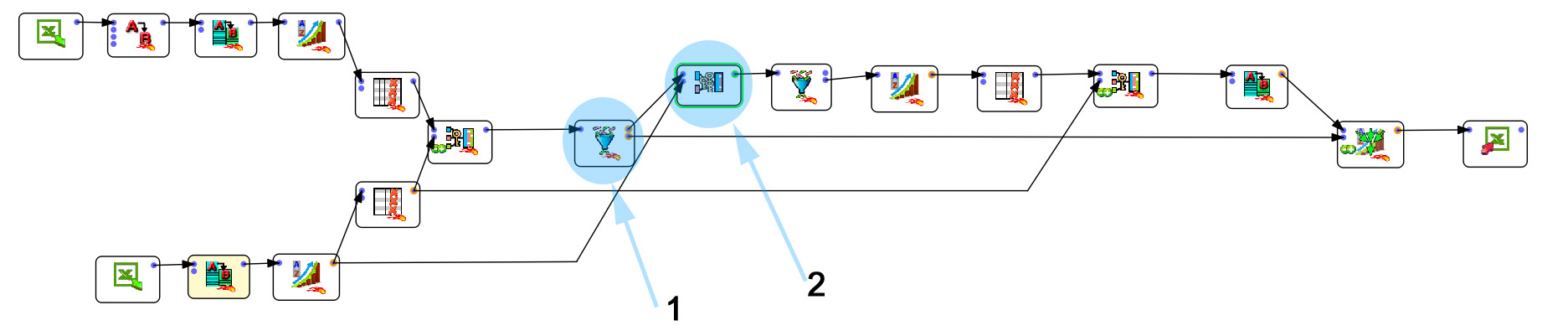
Je ne vais pas vous détailler l’entièreté du process mais je vais juste me concentrer sur les parties les plus importantes et bien entendu sur le fuzzy matching.
- Dans l’étape 1 je sépare les entrées pour laquelle la jointure s’est bien passée (bras inférieur) des entrées pour lesquelles aucune correspondance n’a été trouvée (bras supérieur).
- Dans l’étape 2 j’applique le fameux outil de jointure par fuzzy matching.
Cette fonctionnalité est intéressante car elle vous permet d’aller beaucoup plus loin que Tableau Prep par exemple, mais aussi qu’un ETL comme Talend. Vous pouvez en effet choisir l’algorithme à appliquer pour calculer la similarité entre deux champs. Comme Anatella vous retourne le coefficient de similarité obtenu, il ne reste plus alors qu’à choisir un seuil et à l’appliquer. Les différents algorithmes disponibles sont le coefficient de similarité de Dice, la méthode par similarité de Damereau LevenStein, celle de Jareau Winkler et le calcul de distance de Damereau Levenstein. Une comparaison de ces différentes méthodes fera l’objet d’un article spécifique.
Autre avantage d’Anatella c’est la rapidité. L’entièreté du process tourne en 14,84 secondes (y compris le fuzzy matching). La partie jointure (jusqu’à l’étape 1) tourne en 1,58 secondes là ou Tableau Prep Builder met 10 secondes.
 Conclusion
Conclusion

Pour conclure brièvement, disons que la comparaison des 2 ETL a tourné à l’avantage d’Anatella pour mon cas d’étude (jointure de 2 tables avec Fuzzy Matching). La fonctionnalité de regroupement phonétique proposée par Tableau Prep Builder n’est hélas pas adaptée à la création d’une jointure. Elle ne peut en effet s’appliquer que sur une seule table et nécessite ensuite des opérations manuelles de filtrage, ce qui n’est pas « scalable ».
Images d’illustration : shutterstock
![Illustration de notre publication "Détecteurs d’IA générative gratuits : lesquels choisir ? [Test complet 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)




