Aanbevelingsalgoritmes beloven marketeers om hun Heilige Graal te vinden: gepersonaliseerde relaties met al hun klanten tegen een redelijke prijs. Aangezien de kwaliteit van de klantrelaties een doorslaggevende factor is voor klanttevredenheid en loyaliteit, vormen algoritmische aanbevelingen daarom de belofte van hoogwaardige interacties met de klant en nuttige marketingacties.
Personalisatie op grote schaal kan echter alleen maar door gebruik te maken van gegevens van de klant en digitale sporen die deze achterlaten. Maar hoe kunnen we in een wereld waarin privacy-bewustzijn groeit (GDPR) en het wettelijk kader sterker wordt (e-privacy) we klanten die op zoek zijn naar redelijkheid verzoenen met bedrijven die op zoek zijn naar schaalvoordelen?
Dit is de vraag waarop ik in het artikel van vandaag een antwoord wil zoeken. Dit artikel zal als basis dienen voor mijn presentatie op het BAM-congres op (Engels) 5 en 6 december 2019 in Brussel (zie presentatie hieronder).
Samenvatting
- Personalisatie op grote schaal is een essentiële factor voor het succes van een bedrijf
- De ontwikkeling van de sensibilisering inzake de bescherming van persoonsgegevens
- Personalisatie van de klantrelaties: de droom van elke marketeer
- 4 actiepunten om het vertrouwen van uw klanten te winnen
- Conclusies
Enkele cijfers over de effecten van personalisatie
Algoritmische aanbevelingen worden vandaag de dag op grote schaal gebruikt om de personalisatie van grootschalige klantinteracties mogelijk te maken. Zij is in alle sectoren in B2C ingeburgerd en de doeltreffendheid ervan hoeft niet meer te worden aangetoond. Hieronder enkele cijfers:
- Netflix heeft bijna 160 miljoen abonnees in 190 landen. 80% van het verbruik op het platform is het resultaat van algoritmische aanbevelingen.
- Netflix maakt jaarlijks 1 miljard euro winst dankzij algoritmische personalisatie. Personalisatie gaat leegloop tegen (bron: Techjury)[Engelse site]).
- 35% van de aankopen op Amazon zijn het gevolg van algoritmische aanbevelingen: “klanten die dit gekocht hebben, hebben dat ook gekocht” (bron: McKinsey[Engelse site]).
- De verkoop van Alibaba is met 20% toegenomen door de landingspagina’s van zijn site aan te passen (bron: Alizila[Engelse site]).
- Elke minuut wordt 500 uur content geüpload naar YouTube en het online videogebruik bij kinderen is in 4 jaar tijd verdubbeld. Tegelijkertijd is 70% van het verbruik op YouTube het gevolg van aanbevelingsalgoritme (bronnen: CNet, Tubefilter, Washington Post[Engelse sites]).
- 100% van de resultaten die Google aanbiedt zijn gepersonaliseerd. Het is het meest gebruikte personalisatiealgoritme ter wereld.

Respect van de privacy
Al in 2017 toonde onderzoek (Engelse site) aan dat slechts 10% van de Amerikaanse burgers het gevoel had volledige controle te hebben over hun persoonlijke gegevens. Bovendien vertrouwde slechts 25% van hen erop dat bedrijven hun persoonlijke gegevens beschermden. De herhaalde schandalen (Cambridge Analytica) hebben niet geholpen, vooral sinds de inwerkingtreding van de GDPR heeft geleid tot meer bewustzijn bij het publiek over de noodzaak om de bescherming van persoonsgegevens te respecteren.
We zien ook een vermenigvuldiging van wetgeving of pogingen tot regulering op aanverwante gebieden: filterbubbels, transparantie van algoritmen, digitale verslavingen, enz. We kunnen niet zeggen dat onze gekozen vertegenwoordigers werkloos zijn. Respect voor privacy lijkt hen te motiveren.
64% van de Engelse bedrijven merkte een toename van het aantal klachten na de inwerkingtreding van de GDPR.
We mogen ons er dan ook aan verwachten dat deze verhoogde gevoeligheid van alle partijen weerspiegeld zal worden in aanvragen voor de bescherming van persoonsgegevens die bedrijven ontvangen. Een onderzoek dat in maart 2019 door het ICO (de toezichthoudende autoriteit van het Verenigd Koninkrijk) werd uitgevoerd, werpt licht op het onderwerp. Sinds de inwerkingtreding van de GDPR heeft 64% van de Engelse bedrijven de indruk dat consumenten vaker klagen om hun gegevens te beschermen (bron: enquête van maart 2019, ICO-jaarverslag 2018/2019[Engelse site]).

De vraag blijft echter of deze indruk strookt met de werkelijkheid en vooral of deze indruk ook geldt voor de andere landen van de Europese Unie. Een studie die IntoTheMinds samen met de gegevensbeschermingsautoriteiten in de Europese Unie heeft uitgevoerd, heeft voor 17 landen nauwkeurige gegevens verzameld over het effect van de GDPR. De gemiddelde stijging van het aantal klachten dat de toezichthoudende autoriteiten van de 17 onderzochte landen tussen 2017 en 2018 hebben ontvangen, bedraagt +109% of 2037 klachten.
De gedetailleerde resultaten vindt u hieronder.
| Land | Stijging van het aantal klachten in verband met persoonsgegevens na de inwerkingtreding van de GDPR (in %, jaar 2018 ten opzichte van 2017, van 1 januari tot 31 december van elk jaar). | Toename van het aantal klachten in verband met persoonsgegevens na de inwerkingtreding van de GDPR (aantal klachten, jaar 2018 in vergelijking met 2017, van 1 januari tot 31 december van elk jaar). |
| IJsland | -3% | -3 |
| Kroatië | +257% | +3527 |
| Slowakije | +54% | +32 |
| Letland | +39% | +346 |
| Cyprus | +45% | +154 |
| Verenigd Koninkrijk | +98% | +20642 |
| Noorwegen | +56% | +123 |
| Denemarken | +149% | +3302 |
| Litouwen | +79% | +379 |
| Roemenië | +36% | +1279 |
| Luxemburg | +125% | +250 |
| Zweden | +480% | +1180 |
| Ierland | +45% | +1240 |
| Liechtenstein | +270% | +1465 |
| Hongarije | +22% | +177 |
| Slovenië | +43% | +242 |
| Bulgarije | +65% | +308 |
We zien dat de cijfers een heel verschillende realiteit weerspiegelen. In sommige landen is er sprake van een aanzienlijke toename. Afgezien van het Verenigd Koninkrijk, waar veel klachten werden ingediend (wat de antwoorden van de Engelse DPO’s op het door het ICO genoemde onderzoek verklaart), blijft het aantal klachten in absolute termen echter relatief klein. In vergelijking met de bevolking van de betrokken landen kunnen ze zelfs als onbeduidend worden beschouwd.
Gemiddeld klaagden in 2018 minder dan 5 op de 10.000 mensen over hun persoonlijke gegevens.
Het is daarom noodzakelijk om datgene wat ik aan het begin van deze paragraaf heb gezegd te relativeren. Ondanks alle inspanningen om de grote massa bewust te maken van het belang van hun persoonsgegevens, lijkt het erop dat de boodschap nog steeds moeilijk over te brengen is. De digitale sporen die tijdens onze digitale activiteiten zijn achtergebleven, worden grotendeels verwaarloosd, het belang ervan wordt fout ingeschat en de burgers zijn er dus niet echt in geïnteresseerd. Als de GDPR het begrip ‘privacy-by-design’ heeft gepopulariseerd, dan wil ik toch melden dat deze verordening is ontworpen met ‘fout-by-design’. De ontwerpfout is het toestemmingsbeginsel, een achilleshiel waar we later op terugkomen.
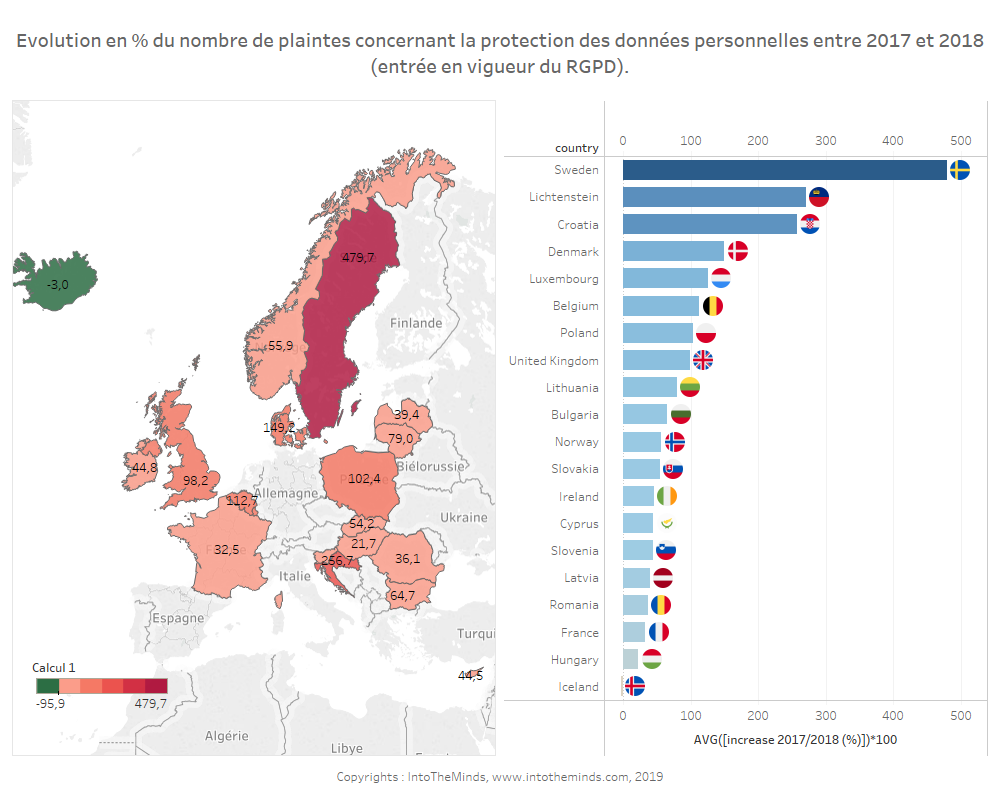
Toename van het aantal klachten in Europa na de inwerkingtreding van de GDPR (bron: onderzoek IntoTheMinds)
Gepersonaliseerde relatie, de droom van elke marketeer
De ontwikkeling van gepersonaliseerde relaties met haar klanten en de droom van elk bedrijf. Een kwalitatieve, gepersonaliseerde relatie op maat helpt inderdaad om klantenbinding op te bouwen. En zoals we allemaal weten, leidt een verhoogde retentie tot een hogere rendabiliteit. Gepersonaliseerde relaties behouden heeft een prijs. Deze prijs is draaglijk als u weinig klanten hebt (bijvoorbeeld in B2B). Maar hoe kan op grote schaal personaliseren? Grootschalige algoritmische aanpassing is mogelijk gemaakt door algoritmes en door het verzamelen van klantgegevens in ongekende hoeveelheden. De democratisering van de mogelijkheden voor gegevensopslag en -verwerking (dankzij Amazon) belooft dan ook om elke klantrelatie te personaliseren tegen lagere kosten.
In 2015 zei 39,7% van de Amerikanen dat ze geen personalisatie wilden.
Ook hier is er echter sprake van een tegenstrijdigheid. In een Amerikaanse studie (Engelse site) gepubliceerd in 2015, zei 39,7% van de respondenten dat ze geen personalisatie wilden en slechts 6,2% vroeg om ‘verregaande’ personalisatie. Is het echt de wens van de consument om een vrije wil in zijn of haar keuze te behouden? Of is het gewoon een gebrek aan kennis van de mechanismen die (weliswaar onzichtbaar) al bezig zijn in alle aspecten van hun dagelijks leven? De vraag is gesteld, maar het is waarschijnlijk dat de tweede optie de meest waarschijnlijke is. Consumenten zijn zich eenvoudigweg niet bewust van het gebruik van personalisatiealgoritmes op alle sites die ze bezoeken, in alle toepassingen die ze gebruiken.
Er is dus een probleem dat we moeten oplossen om het vertrouwen van de consument te winnen. Dit brengt ons bij het vierde en laatste deel van dit artikel.

Hoe bouw je vertrouwen op met de klant in interacties op basis van hun gegevens
Gegevensbeveiliging is een basiselement van vertrouwen. Dus ik ga daar niet over hebben, omdat dat een vereiste is. Zorg ervoor dat u voldoet aan de ISO 27001-norm en dat u normaal gesproken goed bent toegerust om u te concentreren op de volgende acties.
Actie 1: simpelweg informeren
In 2018 heb ik een onderzoek naar het privacybeleid uitgevoerd en een ander onderzoek op de 20 meest gebruikte websites en applicaties. Het duurde tussen de 30 minuten (Pinterest) en 51 minuten (Whatsapp) om het privacybeleid te lezen. Met een snelheid van 120 effectieve woorden per minuut kostte het lezen van de wetsteksten van deze 20 sites meer dan 11 uur. 56% van de internetgebruikers aanvaardt de gebruiksvoorwaarden van de sites zonder ze te lezen (bron [Engelse site]). Aangezien ‘Toestemming’ de achilleshiel van de GDPR is, kunnen bedrijven dus alles doen wat ze willen met uw gegevens, aangezien u ermee heeft ingestemd. We kunnen dus redelijkerwijze stellen dat het noodzakelijk is om de taak van de internetgebruiker te vereenvoudigen en hem te informeren. Op deze manier kunt u zich tegen uw concurrenten verzetten en het respect van uw gebruikers winnen. Tegelijkertijd zullen zij zich meer bewust worden van de bescherming van hun persoonsgegevens, wat u alleen maar ten goede zal komen.
Het duurt tussen de 30 minuten (Pinterest) en 51 minuten (Whatsapp) om het privacybeleid van de applicaties die we dagelijks gebruiken te lezen.

Hoe kan dit in de praktijk worden gedaan? Ik wil u het voorbeeld geven van de RTBF, waarvoor ik van 2015 tot 2019 heb gewerkt. In het bijzonder sta ik achter een video-opname met de Belgische presentatrice Adrien Devyver die in een paar eenvoudige sequenties uitlegt wat de RTBF doet met de gegevens van haar gebruikers. Het is een leuke en eenvoudige manier om een soms ingewikkelde boodschap over te brengen.
Actie 2: de controle teruggeven aan gebruikers
Maatwerkalgoritmen zijn in wezen ondoorzichtige mechanismen. Door de klant de mogelijkheid te geven om deze te manipuleren, wordt het vertrouwen in het functioneren van de klant hersteld. Sinds de inwerkingtreding van de GDPR zijn er een aantal initiatieven die de goede richting uitgaan. Ik noemde de inspanningen van YouTube, waar u nu de verbruiksgeschiedenis kunt verwijderen of opschorten. Er zijn nog andere initiatieven, zoals het initiatief dat werd ontwikkeld vanuit de Spotify-interface door Nava Tintarev en haar collega’s en werd gepresenteerd op de RecSys-conferentie 2018.
Actie 3: stop met het verwerken van andermans gegevens
Jarenlang heb ik gepleit voor de opbouw van ‘datasoevereiniteit’. Bedrijven moeten autonoom worden in het beheer van hun gegevens en niet langer afhankelijk zijn van derden voor het profileren van hun klanten of gebruikers. Dit principe is door een aantal van onze klanten toegepast (waaronder de RTBF vanaf 2016 met de lancering van de unieke login). Achteraf bekeken is iedereen blij met deze keuze. De gegevenscontrole is beter en risico’s op lekken worden beperkt. Het belangrijkste is dat het bedrijf een 360-graden overzicht van klantgegevens behoudt en met zekerheid kan reageren op alle verzoeken van klanten. Een logisch gevolg van deze keuzes is dat klantgegevens niet kunnen worden doorverkocht. Als uw strategie is om alleen te vertrouwen op de gegevens van de 1ste partij (1st party data) is het uitgesloten om deze door te verkopen. Dit zou in strijd zijn met de belofte die aan de gebruiker is gedaan en natuurlijk zou dat het vertrouwen dat hij in u heeft in gevaar brengen.
Actie 4: beetje bij beetje vertrouwen opbouwen
Het is niet mogelijk om alle gegevens die nodig zijn voor een goede aanpassing in één keer te verzamelen. Ten eerste verhindert de GDPR u dit te doen (aangezien er een specifiek doel moet zijn voor het verzamelen van de gegevens). Dan zou het verzamelen van gegevens zonder rechtvaardiging het vertrouwen van de klant in uw bedrijf opnieuw ondermijnen. Wat is de oplossing? We hebben dit al in een ander artikel besproken. U moet de contexten en situaties identificeren die de gebruiker aanmoedigen om u meer over hem of haar te vertellen. In de studie van Wadle et al. (2019, [Engelse site]) worden 17 categorieën gegevens en 10 verschillende contexten geanalyseerd. Terwijl sommige soorten gegevens (interesses of sociaal-demografische gegevens) in elke context gemakkelijk kunnen worden gedeeld, kunnen andere alleen in specifieke situaties worden gedeeld. Dit is bijvoorbeeld het geval voor biometrische gegevens, waar de waarschijnlijkheid van het delen alleen maar toeneemt in het kader van een betere beveiliging.
")
Conclusie
In dit artikel hebben we gezien dat grootschalige personalisatie het gebruik van aanbevelingsalgoritmes vereist. Deze laatste kunnen alleen functioneren op basis van klantgegevens. Klanten staan echter steeds meer wantrouwig tegenover het delen van persoonsgegevens, ook al komt dit wantrouwen nog niet tot uiting in klachten bij de privacy-autoriteiten. Daarom moet er een strategie worden ontwikkeld om het nodige vertrouwen voor de overdracht van persoonsgegevens op te bouwen.
4 actiepunten werden voorgesteld:
- op een speelse manier de werking van het algoritme leren kennen
- de gebruiker controlemogelijkheden geven over de personalisatie
- alleen gegevens gebruiken die u zelf heeft verzameld (gegevens van de 1ste partij)
- bepalen van specifieke, strategische contexten voor het verzamelen van aanvullende gegevens
Heeft u vragen, opmerkingen, verzoeken? Aarzel niet om contact met ons op te nemen. Wij helpen u graag verder.