

Na het verzamelen en voorbereiden van de gegevens is het noodzakelijk de gegevens te analyseren om de gegevensverzameling zinvol te maken. Door lijsten met ruwe gegevens te bekijken, kunnen geen patronen in het gedrag van klanten worden opgebouwd, zodat een slimme manier (datamining) moet worden gevonden om de informatie te selecteren. Door zowel statistische benaderingen als algoritmen te gebruiken, wordt het mogelijk de gegevens te exploiteren.
Contacteer ons voor onze B2C studies
Bij datamining gaat het echter niet alleen om het begrijpen van de algoritmen. Het is ook nodig de stappen te begrijpen en de (soms gratis) instrumenten en dataminingoplossingen die beschikbaar zijn, te bespreken. Wij kunnen dan technieken toepassen die gegevensgestuurde beslissingen en geïnformeerde marketingstrategieën toelaten.

Wat is een gegeven?
Gegevens zijn alle informatie die wij over een verschijnsel kunnen verzamelen. In de bedrijfswereld zijn gegevens vooral gericht op de consument. Voorbeelden zijn leeftijd, geslacht, ras en kredietscore in de banksector.
Wat is een dataset?
Een dataset is een verzameling van gegevens. Data scientists ontvangen gewoonlijk ongelijksoortige gegevens, min of meer gestructureerd, in ongeorganiseerde en oninterpreteerbare vorm. Het dataminingproces laat toe alleen de gegevens te bewaren die nuttig zijn voor de analyse…
Wat is datamining?
In de bedrijfswereld is datamining het proces waarbij verzamelde klantengegevens worden onderzocht en de “insights” die in deze gegevens “inzichten” naar voren komen.
Datamining vereist het gebruik van specifieke instrumenten en technieken ter ondersteuning van bedrijfs- of marketingstrategieën.

Wat is de eenvoudige definitie van datamining?
Gebruik maken van gegevens die zijn geanalyseerd met statistische hulpmiddelen en technieken om een antwoord te geven op een bedrijfsprobleem (of een ander probleem waarvoor gegevens een oplossing kunnen bieden).
Eenvoudig voorbeeld van datamining
Een foto (en een voorbeeld) is beter dan een lange toespraak. Dus? Laten we eens kijken wat datamining in de praktijk betekent.
In dit voorbeeld onderzochten we historische gegevens over atleten die aan de Olympische Spelen deelnamen. Meer bepaald zochten we naar correlaties tussen de variabelen in de dataset.
De lengte en het gewicht van Olympische atleten waren twee geschikte variabelen voor deze eenvoudige oefening. De gegevens werden voorbereid met Anatella, de gegevensvoorbereidingstool (van de categorie ETL’s) die onze voorkeur geniet. Hiermee kunt u de gegevens importeren en voorbereiden voor verdere analyse. Bovendien helpt een reeks ingebouwde functies u om de gegevens snel te “verkennen” en naar mogelijke correlaties te zoeken. In ons geval hebben we een zeer eenvoudige visualisatie gemaakt met behulp van de ingebouwde R-plugins om mogelijke correlaties te “zien”. Door de gegevens te differentiëren naar geslacht is duidelijk een lineaire correlatie te zien tussen lengte en gewicht (wat op zich geen verrassing is).
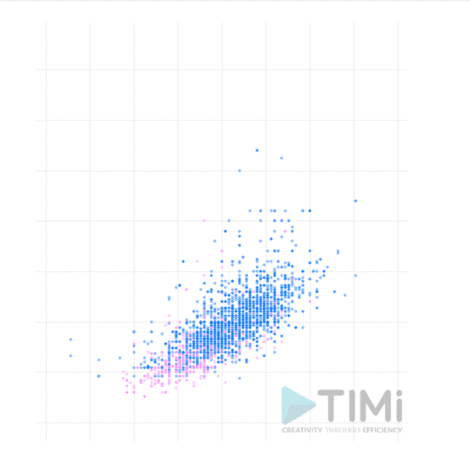
Dit voorbeeld is overdreven eenvoudig en voor de hand liggend. Maar het heeft nog altijd de verdienste dat het laat zien wat datamining inhoudt:
- gegevens voorbereiden
- zoeken naar (meestal verborgen) correlaties tussen variabelen met behulp van verschillende benaderingen
- uw resultaten op een visuele manier weergeven
Ter ontspanning, hier een video van een 10-jarige die dit voorbeeld bespreekt.
Hoe wordt machinaal leren gebruikt bij datamining?
Machinaal leren kan opkomende trends en ongewone patronen opsporen in de ruis van grote gegevensreeksen. Big Data-mining kan aan het licht brengen dat klanten die product x willen, waarschijnlijk ook product y zullen kopen. De algoritmen die deze dataminingoperaties automatiseren, worden ook in de medische wereld gebruikt. Zo kan uit de analyse van medische gegevens blijken dat symptomen x, y, z in het algemeen tekenen zijn van een bepaalde ziekte.
Er zijn veel dataminingtechnieken. In het algemeen zijn er grote datasets nodig, en hoe meer (en hoe beter) de gegevens, hoe groter de kans dat interessante ontdekkingen worden gedaan. Deze gegevens kunnen vervolgens worden gebruikt om bedrijfsvragen te beantwoorden.
Pas op voor correlaties die geen correlaties zijn!
Zoeken naar correlaties in de gegevens is goed. Het is beter om correlaties te vinden die zinvol zijn. Niet alle correlaties impliceren een oorzakelijk verband. Bovendien moet men voorzichtig zijn met “valse correlaties” (Engelse site).
Waartoe dient datamining?
Datamining stelt bedrijven in staat weloverwogen beslissingen te nemen op basis van relaties, patronen en afhankelijkheden. Bij datamining worden een of meer patronen geïdentificeerd die een antwoord kunnen geven op een bedrijfsvraag. Deze patronen kunnen als voorbeelden voor analyse worden gebruikt.
Algoritmen en machinaal leren leiden tot de ontwikkeling van modellen die zullen worden gebruikt nadat de gegevens zijn verzameld. Deze modellen zijn essentieel voor het voorspellen van consumentengedrag.
Deze modellen kunnen vervolgens worden toegepast om nauwkeurigere prognoses te maken. Zij vergroten het vertrouwen in de genomen beslissingen en kunnen ook de kosten drukken door producten te schrappen die mensen niet zullen kopen.
Datamining en relaties
Door relaties in een dataset te identificeren, kunnen de resultaten van datamining ons gedrag van klanten uit het verleden laten zien, dat kan worden gebruikt om toekomstig gedrag te voorspellen. Deze patronen zijn voor mensen vaak niet te detecteren, zodat we moeten vertrouwen op machinaal leren en algoritmen.
Deze modellen liggen vervolgens ten grondslag aan de manier waarop bedrijven waarde uit Big Data halen.
Door de modellen verder te ontleden, kunnen we clusters maken.
Wat betekent clusteren in datamining?
De gegevens zelf zijn vrij nutteloos voor grote bedrijven. Wanneer we datapoints verzamelen, creëren we clusters. Deze clusters kunnen worden gebruikt om modellen te maken voor specifieke groepen mensen.
We kunnen bijvoorbeeld een cluster maken van blanke mannen of vrouwen met meer dan 2 kinderen. Deze clusters maken de modellen vervolgens duidelijker voor data scientists en marketing teams.
Datamining en verkoopvoorspelling
Een van de manieren om gebruik te maken van de relaties die door datamining aan het licht zijn gekomen, is door middel van prognoses.
Verkoopvoorspelling is het gebruik van dataminingtechnieken om een antwoord te geven op een bedrijfsprobleem – wat zal verkopen en wanneer.

Walmart maakt bijvoorbeeld uitstekend gebruik van zijn gegevens. Zo bleek uit de resultaten van Walmart dat consumenten eerder een product met de naam ‘pop-tarts’ met aardbeiensmaak kochten wanneer er een orkaanwaarschuwing in de buurt was. Walmart heeft toen een zakelijke beslissing genomen om pop-tarts met aardbeiensmaak aan de kassa’s te plaatsen.
Door impulsaankopen bij de kassa aan te moedigen, hielp datamining de zakelijke vragen van Walmart te beantwoorden (wat kopen mensen als er een orkaan op komst is?).
Maar dit voorbeeld van datamining is nog altijd erg algemeen, omdat het probeert te voorspellen wat iedereen zal doen. Het is ook mogelijk om de via datamining verzamelde informatie te gebruiken om specifieke groepen mensen te bereiken.
Datamining en segmentering
Een van de meest interessante aspecten van datamining is het creëren van klantensegmenten.
Een bedrijf kan bijvoorbeeld de verzamelde gegevens analyseren en zakelijke beslissingen nemen op basis van factoren zoals leeftijd of geslacht.
Laten we zeggen dat er gegevens worden verzameld over iPhone-aankopen. Als we onze gegevens samenvoegen, zien we dat mensen onder de 30 eerder een iPhone kopen. Een datawetenschapper zou het marketingteam van Apple kunnen vertellen dat ze hun reclame moeten richten op de markt onder de 30.
Hier creëren wij voorspellende modellen: wij weten wat we willen verkopen en we proberen te bepalen voor welke groep we reclame maken.
Dit is maar één voorbeeld, maar u kunt nog specifieker zijn. We kunnen onze markt verder segmenteren door te kijken naar geslacht, ras en kredietscore. We zouden dan kunnen ontdekken dat blanke vrouwen onder de 30 met uitstekende kredietscores de doelmarkt voor iPhones zijn. De segmentatiemogelijkheden zijn eindeloos en hangen alleen af van de gegevens waarover u beschikt.

Hoe gebruikt u dataminingtechnieken?
Het verzamelen van gegevens is het eerste deel van elk dataminingproces. Door gegevens te gebruiken die het gedrag van klanten laten zien, kunnen we beginnen patronen te creëren. Deze gegevens kunnen worden gehaald uit e-mails, analyses van winkelwagentjes, tekstgegevens en andere relevante bronnen. Maar voordat we dit kunnen doen, is de fase van voorbereiding van de gegevens noodzakelijk.
Wat is de fase van de voorbereiding van de gegevens?
Wetenschappers die met ruwe gegevens werken, moeten eerst fouten en uitschieters verwijderen en de gegevens voorbereiden op compatibiliteit met databanksystemen. Deze stap is belangrijk om de kwaliteit van de gegevens te waarborgen.
Deze stap is essentieel: door uitschieters te verwijderen en de gewenste gegevens te verrijken (hetzij door meer gegevens toe te voegen, hetzij door verbanden te leggen) kan een beter inzicht worden verkregen in de onderliggende modellen. Deze stap wordt soms “data wrangling” genoemd.
Wat is een dataminingmodel?
Modellen worden gemaakt om datamining-software te voeden en het proces van machinaal leren te ondersteunen. Het identificeren van bekende waarden van klantengedrag vergemakkelijkt het dataminingproces. Soms wordt dit proces ook wel “association rule learning” genoemd.
Wij vertellen onze datamining-software bijvoorbeeld dat mannelijke studenten vlugger een computer kopen dan eender welk ander marktsegment. De software kan zich dan richten en haar resultaten verfijnen door zich op dat segment te richten
Hoe kan ik datamining-software gebruiken ?
Dataminingtechnieken worden almaar geavanceerder, maar veel programma’s zijn gratis beschikbaar. U kunt beginnen met het analyseren van uw klantenbestand zonder een cent te betalen.
Voor sommige van deze instrumenten is inzicht in dataminingconcepten en -methoden essentieel. De ontwikkeling van een proces voor het gebruik van de geëxtraheerde gegevens is noodzakelijk om de gegevensbanken te kunnen benutten.

5 gratis datamining tools
Xplenty
Veel mensen die zich willen toeleggen op datamining, voelen zich niet noodzakelijk comfortabel met coderen. Xplenty is een “No Code”-software waarmee bedrijven gemakkelijk datapijplijnen kunnen bouwen. Met een eenvoudige drag-and-drop interface, kunt u Xplenty in uw bedrijf invoeren zonder enige kennis van datawetenschap. Door al uw gegevensbronnen te verzamelen, kunt u gemakkelijk gegevens integreren en voorspellende modellen bouwen. Het platform is ook schaalbaar en beheersbaar, zodat gebruikers zich kunnen concentreren op de gegevens in plaats van te verzanden in database-analyse.
Rapid Miner
Rapid Miner Studio Free (Engelse site) is gebaseerd op een Java-engine en is een open-source tool die kan worden gebruikt voor text mining, machine learning en voorspellende analyse. Het heeft een breed scala aan nuttige functies voor het bedrijfsleven, training en machinaal leren, waardoor het een nuttig en veelzijdig instrument is. De voorbereiding van de gegevens kan rechtstreeks in de software gebeuren, evenals de ontwikkeling van modellen met behulp van intelligent ontworpen technologie voor machinaal leren. In wezen is het een platform dat in alle bedrijfsbehoeften voorziet.
Knime
Knime (Engelse site) wordt vooral gebruikt bij farmaceutisch onderzoek, maar heeft ook heel wat toepassingen in een meer globale bedrijfscontext. Door het creëren van modulaire pijplijnen specifiek voor uw behoeften, kunt u Knime gericht gebruiken voor de koppeling en overdracht van gegevens. Modellering en visualisering worden ook vergemakkelijkt door ingebouwde hulpmiddelen. Deze instrumenten worden voortdurend bijgewerkt om er nieuwe technologieën en algoritmen in op te nemen.
Apache Mahout
Apache Mahout (Engelse site) werd speciaal ontworpen om algoritmen voor machinaal leren te maken en is wellicht de beste keuze voor datawetenschappers die zelf datasets willen samenvoegen en transformeren. De code van de toepassing kan ook worden geïntegreerd in andere toepassingen, wat betekent dat Apache Mahout naast andere programma’s kan worden uitgevoerd. Dit instrument, met vooraf gebouwde algoritmen en een wiskundige experimenteeromgeving, is perfect voor het in kaart brengen en verkleinen van modellen.
WEKA
WEKA (Engelse site) werd ontwikkeld door de Universiteit van Waikato en is specifiek ontworpen voor gegevensanalyse en voorspellende modellering. De algoritmen en visualisatiehulpmiddelen vullen het machinaal leren aan en alle functies zijn gemakkelijk te gebruiken. De software vereist enige kennis van JAVA om goed te kunnen werken, maar kan alle belangrijke dataminingtaken aan, zoals verwerking, visualisatie en datamining zelf.

Hoe kan datamining mijn bedrijf verbeteren?
Door gegevens “clusters” te analyseren en de markt te segmenteren, kunnen bedrijven beslissingen nemen die gebaseerd zijn op vroeger klantengedrag. Big Data kunnen dus worden omgezet in iets nuttigs voor bedrijven.
Gegevens kunnen ook worden gebruikt om beslissingen van klanten te beïnvloeden. Op basis van bekende kooppatronen kunnen bedrijven klanten beïnvloeden om specifieke producten te kopen. Productontwikkeling kan ook worden beïnvloed door na te gaan wat zou worden gekocht als het beschikbaar zou zijn (zie de directe link naar marktonderzoek).
Door het gebruik van gratis instrumenten kan datamining worden gedemocratiseerd. Deze hulpmiddelen kunnen in elke bedrijfsomgeving worden gebruikt om gegevens te creëren, samen te voegen, te transformeren en te visualiseren op een manier die nuttig is voor bedrijfsleiders.





