

Venant après le processus de collecte et de préparation des données, l’analyse des données est une étape nécessaire pour trouver un sens à un ensemble de données (le dataset). Regarder des listes de données brutes ne permet guère de construire des modèles de comportement des clients, il faut donc trouver un moyen intelligent (le « data mining » ou « exploration des données ») de passer les informations au crible. En utilisant des approches statistiques ainsi que des algorithmes, il devient possible d’exploiter les données.
Contactez-nous pour nos études B2B
Cependant, aborder l’exploitation des données ne se limite pas à comprendre les algorithmes. Il est également nécessaire d’en comprendre les étapes, de discuter des outils (parfois gratuits) et des solutions d’extraction de données qui sont disponibles. Nous pouvons ensuite appliquer des techniques qui permettent de prendre des décisions fondées sur les données et d’élaborer des stratégies marketing éclairées.

Qu’est-ce qu’une donnée ?
Les données sont toutes les informations que nous pouvons recueillir sur un phénomène. Dans la sphère business, les données sont principalement centrées autour du consommateur. On peut citer par exemple, l’âge, le sexe, la race et le score de crédit dans le domaine bancaire.
Qu’est-ce qu’un jeu de données ?
Un jeu de données (ou dataset en anglais) est un ensemble de données. Les data scientists reçoivent généralement des données disparates, plus ou moins structurées, sous forme désorganisées et ininterprétables. Le processus de data mining va notamment permettre de ne retenir que les données utiles à l’analyse..
Qu’est-ce que le data mining ?
Dans le monde des affaires, le data mining est le processus par lequel les données collectées sur les clients sont explorées et les « insights » contenus dans ces données révélés.
Le data mining requiert l’utilisation d’outils et de techniques spécifiques pour supporter les stratégies commerciales ou marketing.

Quelle est la définition simple du data mining ?
Utiliser des données qui ont été analysées par des outils et des techniques d’ordre statistiques pour apporter une réponse à un problème commercial (ou tout autre problème auquel les données peuvent apporter une solution).

Exemple simple de data mining
Une image (et un exemple) valent mieux qu’un long discours. Alors ? voyons ce que le data mining signifie en pratique.
Dans cet exemple, nous avons exploré les données historiques sur les athlètes ayant participé aux jeux olympiques. Plus particulièrement, nous avons recherché des corrélations entre les variables présentes dans le jeu de données.
La taille et le poids des athlètes olympiques étaient deux variables adaptées pour cet exercice simple. Les données ont été préparées à l’aide d’Anatella, notre outil de préparation de données préféré (qui appartient à la catégorie des ETL). Il vous permet d’importer et de préparer les données pour une analyse ultérieure. Une série de fonctionnalités intégrées vous aident en outre à « explorer » rapidement les données et à rechercher d’éventuelles corrélations. Dans notre cas, nous avons réalisé une visualisation très simple en utilisant les plugins R intégrés pour « voir » les corrélations éventuelles. En différenciant les données par sexe, vous pouvez clairement voir une corrélation linéaire entre la taille et le poids (ce qui n’est pas une surprise en soi).
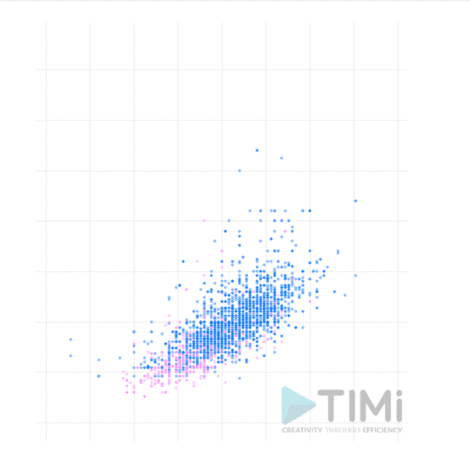
Cet exemple est excessivement simple et évident. Mais il a quand même le mérite de vous montrer en qui consiste le data mining :
- préparer les données
- rechercher des corrélations (la plupart du temps cachées) entre les variables en utilisant différentes approches
- présenter vos résultats de manière visuelle
Pour vous détendre, voici une vidéo où un enfant de 10 ans aborde ce même exemple.
Comment le machine learning est-il utilisé dans l’exploration de données ?
L’apprentissage automatique (ou machine learning) permet de détecter des tendances émergentes et des modèles inhabituels dans le bruit de grands ensembles de données. L’exploration des « Big Data » peut permettre de mettre en évidence que les clients qui veulent le produit x sont également susceptibles d’acheter le produit y. Les algorithmes qui automatisent ces opérations de data mining sont également utilisés dans le monde médical. Ainsi l’analyse des données médicales pourra montrer que les symptômes x, y, z sont généralement les signes d’une maladie particulière.
Il existe de nombreuses techniques d’exploration de données. Elles requièrent généralement de grands jeux de données et en tout état de cause, plus les données seront nombreuses (et de qualité), plus la probabilité de faire des découvertes intéressantes sera grande. Ces données pourront ensuite servir à répondre à des questions « business ».
Attention aux corrélations qui n’en sont pas !
Chercher des corrélations dans les données c’est bien. Trouver des corrélations qui ont du sens c’est mieux. Toutes les corrélations n’impliquent en effet pas une relation de causalité. De plus il faut faire attention aux « fausses corrélations« .
À quoi sert le data mining ?
Le data mining permet aux entreprises de prendre des décisions éclairées sur la base de relations, de modèles et de dépendances. L’exploration de données fonctionne en identifiant un ou plusieurs modèles qui peuvent répondre à une question business. Ces modèles peuvent servir d’exemple pour l’analyse.
Les algorithmes et l’apprentissage automatique conduisent à l’élaboration de modèles que seront utilisés après la collecte de données. Ces modèles sont essentiels pour prédire le comportement des consommateurs.
Ces modèles peuvent ensuite être mis en œuvre pour créer des projections plus précises. Ils augmentent la confiance dans les décisions prises et peuvent également réduire les coûts en supprimant les produits que les gens n’achèteront pas.
Exploration de données et relations
En identifiant les relations dans un ensemble de données, les résultats de l’exploration de données peuvent nous montrer les comportements antérieurs des clients qui peuvent être utilisés pour prédire les comportements futurs. Ces tendances sont souvent impossibles à déceler par l’homme, c’est pourquoi nous devons nous fier à l’apprentissage automatique et aux algorithmes.
Ces modèles sous-tendent ensuite la manière dont les entreprises extraient de la valeur des Big Data.
En décomposant davantage les modèles, nous pouvons créer des clusters.
Qu’est-ce que le clustering dans le Data Mining ?
Les données en elles-mêmes sont assez inutiles pour les grandes entreprises. Lorsque nous rassemblons des points de données, nous créons des clusters. Ces clusters peuvent être utilisés pour créer des modèles pour des groupes spécifiques de personnes.
Par exemple, nous pouvons créer un cluster d’hommes blancs ou de femmes ayant plus de 2 enfants. Ces clusters rendent ensuite les modèles plus clairs pour les scientifiques des données et les équipes de marketing.
L’exploration de données et les prévisions de ventes
L’une des façons d’utiliser les relations mises au jour par le data mining, est la prévision des ventes (le forecasting en anglais).
La prévision des ventes consiste à utiliser des techniques d’exploration de données pour répondre à un problème commercial, à savoir ce qui va se vendre et quand.
 Par exemple, Walmart fait un excellent usage de ses données. Ainsi, les résultats de Walmart ont révélé que les consommateurs étaient plus susceptibles d’acheter un produit appelé « Pop-Tarts » à la fraise en cas d’alerte ouragan dans la région. Walmart a alors pris la décision commerciale de placer des Pop-Tarts à la fraise près des caisses.
Par exemple, Walmart fait un excellent usage de ses données. Ainsi, les résultats de Walmart ont révélé que les consommateurs étaient plus susceptibles d’acheter un produit appelé « Pop-Tarts » à la fraise en cas d’alerte ouragan dans la région. Walmart a alors pris la décision commerciale de placer des Pop-Tarts à la fraise près des caisses.
En encourageant les achats impulsifs aux caisses, l’exploration de données a permis de répondre aux questions commerciales de Walmart (qu’est-ce que les gens achètent à l’approche d’un ouragan ?).
Mais cet exemple de data mining reste très général puisqu’on essaie de prédire ce que tout le monde va faire. il est également possible d’utiliser les informations recueillies via le data mining pour cibler des groupes spécifiques de personnes.
Data mining et segmentation
L’un des aspects les plus intéressants du data mining reste la création de segments de clientèle.
Une entreprise peut par exemple analyser les données recueillies et prendre des décisions commerciales en fonction de facteurs tels que l’âge ou le sexe.
Imaginons que des données soient récoltées sur les achats d’iPhone. Lorsque nous regroupons nos données, nous constatons que les personnes de moins de 30 ans sont plus susceptibles d’acheter un iPhone. Un data scientist pourrait informer l’équipe marketing d’Apple qu’elle doit axer ses publicités sur le marché des moins de 30 ans.
Ici, nous créons des modèles de prédiction : nous savons ce que nous voulons vendre et nous essayons de déterminer vers qui nous devons faire de la publicité.
Ce n’est qu’un exemple, mais vous pouvez être encore plus précis. Nous pourrions segmenter davantage notre marché en examinant le sexe, la race et le score de crédit. Nous pourrions alors découvrir que les femmes blanches de moins de 30 ans ayant un excellent score de crédit constituent le marché cible pour les iPhones. Les possibilités de segmentation sont infinies et ne dépendent que des données dont vous disposez.

Comment utiliser les techniques d’exploration de données ?
La collecte de données est la première partie de tout processus d’exploration de données. En prenant des données qui montrent le comportement des clients, nous pouvons commencer à créer des modèles. Ces données peuvent être extraites d’e-mails, d’analyses de panier de consommation, de données textuelles et de toute autre source pertinente. Mais avant de pouvoir le faire, la phase de préparation des données est nécessaire.
Qu’est-ce que la phase de préparation des données ?
Lorsqu’on leur présente un ensemble d’informations brutes, les scientifiques qui travaillent avec des données doivent d’abord en éliminer les erreurs et les valeurs aberrantes (les outliers), et préparer les données pour qu’elles soient compatibles avec les systèmes de base de données. Cette étape est importante car elle permet de s’assurer de la qualité des données.
Cette étape est essentielle : la suppression des données aberrantes et l’enrichissement des données souhaitées (que ce soit par l’ajout de données supplémentaires ou la création de liens) permettent de mieux comprendre les modèles sous-jacents. Cette étape est parfois appelée data wrangling.
Qu’est-ce qu’un modèle d’exploration de données ?
Les modèles sont créés pour alimenter les logiciels de data mining et entretenir le processus de machine learning. L’identification des valeurs connues du comportement des clients facilite le travail d’exploration des données. Parfois, ce processus peut être appelé « association rule learning ».
Par exemple, nous apprenons à notre logiciel de data mining que les étudiants de sexe masculin sont plus susceptibles d’acheter des ordinateurs que tout autre segment de marché. Le logiciel peut ainsi cibler et affiner ses résultats en se concentrant sur ce segment
Comment puis-je utiliser un logiciel de data mining ?
Les techniques de data mining deviennent de plus en plus sophistiquées, mais de nombreux programmes sont disponibles gratuitement. Vous pouvez commencer par analyser votre base de clients sans payer un centime.
Une compréhension des concepts et des méthodes d’exploration de données est essentielle pour certains de ces outils. Le développement d’un processus d’utilisation des données extraites est nécessaire pour tirer profit des bases de données.

5 outils gratuits de data mining
Xplenty
De nombreuses personnes qui souhaitent se lancer dans le data mining ne sont pas forcément à l’aise avec le codage. Xplenty est un logiciel de type « No Code » qui aide les entreprises à construire facilement des pipelines de données. Grâce à une interface simple de type glisser-déposer, vous pouvez intégrer Xplenty dans votre entreprise sans avoir de connaissances en data science. En rassemblant toutes vos sources de données, vous pouvez facilement intégrer les données et commencer à construire des modèles prédictifs. La plateforme est également évolutive et gérée, de sorte que les utilisateurs peuvent se concentrer sur les données au lieu de s’enliser dans l’analyse des bases de données.
Rapid Miner
Basé sur un moteur Java, Rapid Miner Studio Free est un outil open-source qui peut être utilisé pour l’exploration de texte, l’apprentissage automatique et l’analyse prédictive. Il possède un large éventail de fonctionnalité utiles pour les entreprises, la formation et l’apprentissage automatique, ce qui en fait un outil utile et polyvalent. L’étape de préparation des données peut être réalisée directement dans le logiciel, de même que le développement de modèles grâce à une technologie d’apprentissage automatique intelligemment conçue. En substance, il s’agit d’une plateforme qui couvre tous les besoins des entreprises.
Knime
Utilisé principalement dans la recherche pharmaceutique, Knime a également de nombreuses applications dans un contexte business plus global. En créant des pipelines modulaires spécifiques à vos besoins, vous pouvez utiliser Knime pour la réconciliation et la transformation de vos données. La modélisation et la visualisation sont également facilitées par des outils intégrés. Ces outils sont constamment mis à jour pour inclure de nouvelles technologies et de nouveaux algorithmes.
Apache Mahout
Conçu spécifiquement pour créer des algorithmes d’apprentissage automatique, Apache Mahout peut être le meilleur choix pour les data scientists qui souhaitent fusionner et transformer eux-mêmes des ensembles de données. Le code de l’application peut également être intégré à d’autres applications, ce qui signifie que vous pouvez exécuter Apache Mahout aux côtés d’autres programmes. Chargé d’algorithmes préfabriqués et d’un environnement d’expérimentation mathématique, cet outil est parfait pour cartographier et réduire les modèles.
WEKA
Conçu par l’Université de Waikato, WEKA est spécifiquement destiné à l’analyse de données et à la modélisation prédictive. Les algorithmes et les outils de visualisation arrivent en complément de l’apprentissage automatique et toutes les fonctionnalités sont faciles à utiliser. Ce logiciel nécessite une certaine connaissance de JAVA pour fonctionner correctement, mais il peut prendre en charge toutes les principales tâches d’exploration de données telles que le traitement, la visualisation et l’exploration de données elle-même.

Comment le data mining peut-il améliorer mon activité ?
En analysant les « clusters » de données et en segmentant le marché, les entreprises peuvent prendre des décisions qui sont basées sur le comportement passé des clients. Les Big Data peuvent donc être transformés en quelque chose d’utile pour les entreprises.
Les données peuvent également être utilisées pour influencer les décisions des clients. À partir de tendances d’achat connues, les entreprises peuvent inciter les clients à acheter des produits spécifiques. Le développement de produits peut également être influencé en identifiant ce qui serait acheté s’il était disponible (vous voyez directement le lien avec l’étude de marché).
L’utilisation d’outils gratuits permet de démocratiser le data mining. Ces outils peuvent être utilisés dans n’importe quel environnement « business » pour créer, fusionner, transformer et visualiser des données d’une manière qui soit utile aux chefs d’entreprise.




![Illustration de notre publication "Détecteurs d’IA générative gratuits : lesquels choisir ? [Test complet 2025]"](/blog/app/uploads/sherlock-holmes-120x90.webp)