

After the collection and preparation process, data analysis is necessary to find meaning in a data set. Looking at a page of data does very little for building models of customer behavior, so we need an intelligent way (data mining) to sift through information. By using statistics-based approaches and algorithms, we can start to mine data.
Understanding data mining isn’t just understanding algorithms, however. We need to understand the steps to clean the data and visualize it, as well as range of free tools and data mining software that we can take advantage of. Then we can apply techniques that inform business decisions based on databases and build informed marketing strategies.

What Is Data?
Data is any information we can gather about a certain phenomenon. In business, data is mainly centered around consumers. Examples include age, gender, race, and credit score.
What Are Data Sets?
A data set is a collection of data points. These are generally received by data scientists as more or less organized, disparate collections of data. Knowledge discovery (or data mining) is necessary to clear the unhelpful data.
What Is Data Mining?
In business, data mining is the process of collecting information about customers and using tools and techniques to inform a business goal or marketing strategies. Data mining is sometimes called knowledge discovery in data.

What’s A Simple Definition Of Data Mining?
Using data that has been analyzed by tools and techniques that largely rely on statistical approaches to inform a business problem (or any other problem where data can bring the solution).

Example of data mining
An image (and an example) are worth thousands words. Let’s see what data mining means in practice.
In this example we “mined” the historical data of the Olympic games. More particularly, we looked for correlations between the variables present in the dataset.
Height and the weight of the Olympic athletes were 2 candidate variables for that exercise. The data was prepared using Anatella, our favorite data preparation tool (that falls within the ETL category). It enables you to import and prepare the data for further analysis. A series of in-built tools helps you rapidly “mine” the data and look for possible correlations. In our case we did a very simple visualization using the built-in R plugins to display the information. Breaking down the data by gender, you can clearly see a linear correlation between height and weight (no big surprise here).
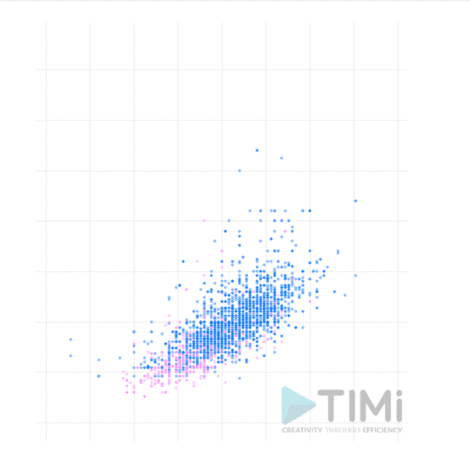
This example is overly simple and obvious. But it’s nevertheless appropriate to show you the essence of the work of a data miner:
- prepare the data
- look for (hidden) correlations between variables using different approaches
- present your results in a visual way
If you want to watch something funny, here’s a video where a 10-year old kid explains the same example.
How Is Machine Learning Used In Data Mining?
Machine learning allows computers to find emerging trends and unusual patterns in the white noise of large data sets. Breaking down big data can show that customers who want product x are also likely to buy product y. These algorithms also show medical information, such as symptoms x, y, z are usually signs of a particular disease.
There are many data mining techniques that we can use, but they all need large data sets of customer data. This data can then answer business questions.
Beware of spurrious correlations !
Looking for correlations in the data is good. Finding correlations that make sense is better. Not all correlations imply a causal relationship. Moreover, one must be careful with “spurrious correlations“.
What Is Data Mining Used For?
Mining data allows businesses to make informed decisions based on relationships, patterns, and dependencies. It works by identifying a pattern or patterns that can answer a business question. These patterns can be used as an example for analysis.
Algorithms and machine learning lead to models that we can use after data collection. These models are key for predictive action in consumer behavior.
These models can then be implemented to create more accurate projections. They increase confidence in decisions made and can also decrease costs by removing products that people are not buying.
Data Mining and Relationships
When identifying relationships in a data set, data mining results can show us previous customer behaviors that can be used to predict emerging trends. These trends are often impossible for humans to notice, so we need to rely on machine learning and algorithms.
These patterns then underpin the way businesses extract value from big data sets.
By breaking down patterns further, we can create clusters.
What Is Clustering In Data Mining?
Data on its own is fairly useless for big businesses. When we bring data points together, we create clusters. These clusters can be used to create models for specific groups of people.
For example, we may create a cluster of white men or women with more than 2 children. These clusters then make patterns clearer to data scientists and marketing teams.
Data Mining And Sales Forecasting
One way to use the relationships that data mining algorithms show us is through sales forecasting.
Sales forecasting is the use of data mining techniques to answer a business problem about what will sell and when.

For example, Walmart makes great use of the information from its data miners. Walmart’s research found that people were more likely to buy strawberry Pop-Tarts if there were hurricane warnings in the area. Walmart then made the business decision to place strawberry Pop-Tarts by the checkouts.
By encouraging impulse buys at the checkouts, Walmart’s business questions (what do people buy when hurricanes are coming?) were answered by data mining (people buy more strawberry Pop-Tarts).
But this is very general data mining. Trying to predict what everyone will do. We can also use information gathered from mining data to target specific clusters of people.
Data Mining And Market Segmentation
One of the most powerful aspects of data mining is creating customer segments. Market segmentation can be seen as clustering in action.
A company can look at the data that is being collected and start to make business decisions based on factors like age or gender.
For example, we collect data concerning iPhone purchases. When we cluster our data together, we find that people under 30 are more likely to buy an iPhone. A data scientist could inform Apple’s marketing team to focus their advertisements on the under 30 market.
Here, we are creating prediction models – we know what we want to sell and try to find out who want need to advertise to.
That’s just one example, but you can get very specific. We could segment our market further by looking at gender, race, and credit score. Then we may find that white, under 30 women with excellent credit scores are the target market for iPhones.
Segmentation possibilities are endless and depend only on the data you have.

How Do We Use Data Mining Techniques?
Data collection is the first part of any data mining process. Taking data that shows customer behavior, we can begin to create models. This data can be pulled from e-mails, market basket analysis, text data, and any other relevant sources. But before that can be done, the data preparation phase is necessary.
What Is The Data Preparation Phase?
When presented with a raw set of information, scientists that work with data need to remove errors and outliers, as well as configuring all data to fit with the database systems. This stage is important for removing data quality problems. Sometimes it’s called data wrangling.
This is key in the data mining process – removing outliers and enriching the data that is wanted (whether by adding more data or creating links) leads to a better understanding of the underlying patterns.
What Is A Data Mining Model?
Models are created to feed data mining software and start the machine learning process. Identifying known values of customer behavior helps data mining projects to develop better algorithms. Sometimes, this process can be called association rule learning.
For example, we teach our data mining software that male students are more likely to buy computers than any other market segment. Now, our data mining software can target and develop to start showing more specific or otherwise improved data.
How Can I Use Data Mining Software?
Data mining technology is becoming more and more sophisticated, but many programs are available for free. You can start your journey by analyzing your customer base without paying a penny.
An understanding of data mining concepts and data mining methods is key for some of these tools. Developing a process for using mined data is necessary to get worth out of databases.

5 Free Data Mining Tools
Xplenty
Many people who want to use data mining may not be comfortable with coding. Xplenty is a no-code software that helps businesses build data pipelines easily. With a simple drag-and-drop interface, you can integrate Xplenty into your business without having a data science background. By bringing all your data sources together, you can easily integrate data and start to build predictive models. The platform is also scalable and managed, so users can focus on the data instead of getting bogged down in database analysis.
Rapid Miner
Based on a Java engine, Rapid Miner Studio Free is an open-source tool that can be used for text mining, machine learning, and predictive analysis. It has a wide range of applications for businesses, training, and machine learning, making it a useful and versatile tool. The data preparation stage can be integrated into the software as well as developing models through intelligently designed machine learning technology. In essence, it is an end-to-end platform that covers all business needs.
Knime
Used mainly in pharmaceutical research, Knime also has many applications in a business setting. By creating specific modular pipelines for your needs, you can focus Knime’s technology on merging and transforming your data. Modeling and visualizing data is also easy thanks to intelligent, built-in tools. These tools are constantly being updated to include new technology and algorithms to help support your business.
Apache Mahout
Designed specifically to create machine learning algorithms, Apache Mahout may be the best choice for data scientists who want to merge and transform data sets themselves. The application’s code can also be integrated with other applications, meaning that you can run Apache Mahout alongside other programs. Loaded with pre-made algorithms and a math experimentation environment, this tool is perfect for mapping and reducing templates.
WEKA
Designed by the University of Waikato, WEKA is specifically for data analysis and predictive modeling. Algorithms and visualizations tools support machine learning and all features are easy to use. This piece of software requires some knowledge of JAVA to work properly, but it can support all major data mining tasks such as processing, visualization, and data mining itself.

How Can Data Mining Improve My Business?
By analyzing data clusters and segmenting the market, businesses can make informed decisions about past customer behavior. The white noise of big data can be broken down and turned into something useful for businesses.
Data can also be used to create new trends and influence customer decision-making. Taking known buying trends, businesses can influence customers to buy products in specific groups. Product development can also be influenced by identifying what would be bought if it was available. You directly see the link with market research techniques.
By the use of free tools, data mining is not an esoteric art that is only for mathematicians and data scientists. Cutting-edge technology can be used in any business environment to create, merge, transform, and visualize data in a way that is useful for business leaders to create business solutions.




