
Dit is het probleem waar ik de laatste tijd mee zit. Een klant vroeg me om gegevens uit honderden Excel-bestanden te verwerken. Ik wilde eerlijk gezegd geen uren besteden aan het handmatig extraheren van deze gegevens. Daarom heb ik het proces geautomatiseerd met Anatella en volgens gegevens gevisualiseerd onder Tableau. Hieronder vindt u een kleine tutorial over data preparation en een goede manier om gegevens efficiënter te verwerken met een goede ETL.
Als u maar 30 seconden heeft
- via Anatella kon ik een proces automatiseren voor het extraheren van gegevens uit Excel-bestanden
- dat liet me toe om een voorheen vervelend en foutgevoelig proces via manuele verwerking, snel en duurzaam te maken
- de gebruikte methode is gebaseerd op een lus met een verwerking die start op Excel-bestanden die zich in een gedefinieerde map bevinden
- er wordt als output een geconsolideerd bestand gemaakt, dat ik kan gebruiken in Tableau
Beschrijving van het probleem
Het probleem waarmee ik te kampen heb is vrij algemeen. In het kader van een project dat het Parlement toevertrouwde, werd mij gevraagd statistieken op te stellen over de tewerkstelling van personen met een handicap in het openbaar bestuur.
Eenmaal per jaar moet elke gemeente een Excel-sjabloon invullen met een hele reeks indicatoren: aantal VTE’s, geslacht, referentiesalarissen, aantal banen dat aan gehandicapten is toevertrouwd, enz. Het goede nieuws is dat de betrokken administraties het model respecteren en de informatie op de juiste plaats invullen. Het probleem is dat de sjablonen niet altijd volledig zijn, sommige ontbreken en het gaat om veel bestanden. Het is daarom noodzakelijk het verscheidene malen door te nemen alvorens over geconsolideerde gegevens te beschikken.
De eerste oplossing zou zijn om elk bestand afzonderlijk te verwerken nadat de fouten erin zijn gecorrigeerd. Maar dat is tijdrovend en niet duurzaam. Ik zou elk jaar opnieuw moeten beginnen. Bovendien zou het veelvuldig heen en weer communiceren vereisen met de overheid om de dossiers één voor één op te halen, al naargelang ze werden verzonden. Dat zou me enorm vertragen.
De juiste aanpak is het creëren van een “pipeline” voor het extraheren en structureren van gegevens. Dit verloopt automatisch en stelt mij moeiteloos in staat om enerzijds mijn dataset en anderzijds mijn visualisaties onder Tableau bij te werken. Op die manier heb ik het probleem met Anatella aangepakt.
Oplossing
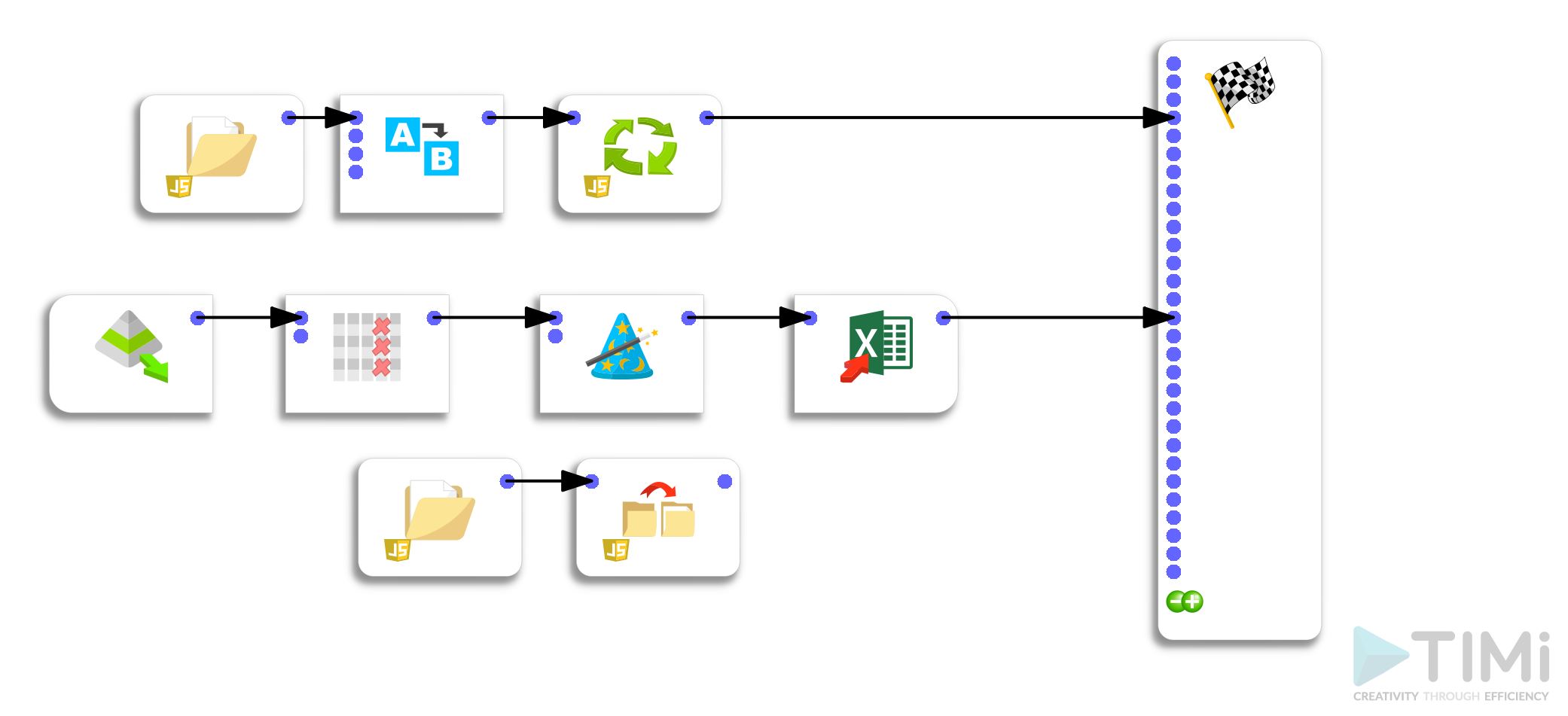
De ontwikkelde oplossing bestaat uit twee hoofdstappen:
– een pipeline om gegevens uit elk bestand te halen en te herstructureren
– een pipeline om alle bestanden in een bepaalde map in een keer te verwerken
Stap 1: extractie van gegevens uit Excel-bestand en herformatteren
De eerste stap bestaat dus uit het extraheren van de informatie uit bepaalde cellen in de Excel-bestanden. Om dit te doen gebruik ik een ternaire operator.
Met de (zeer handige) functie “unflatten” kan ik alle gegevens op een enkele regel structureren, waarmee de basis wordt gelegd voor het bestandsformaat dat nodig is voor Tableau.
Tenslotte schrijf ik een .gel-bestand in dezelfde map als het Excel-bestand.

Stap 2: bestandsverwerkingslus
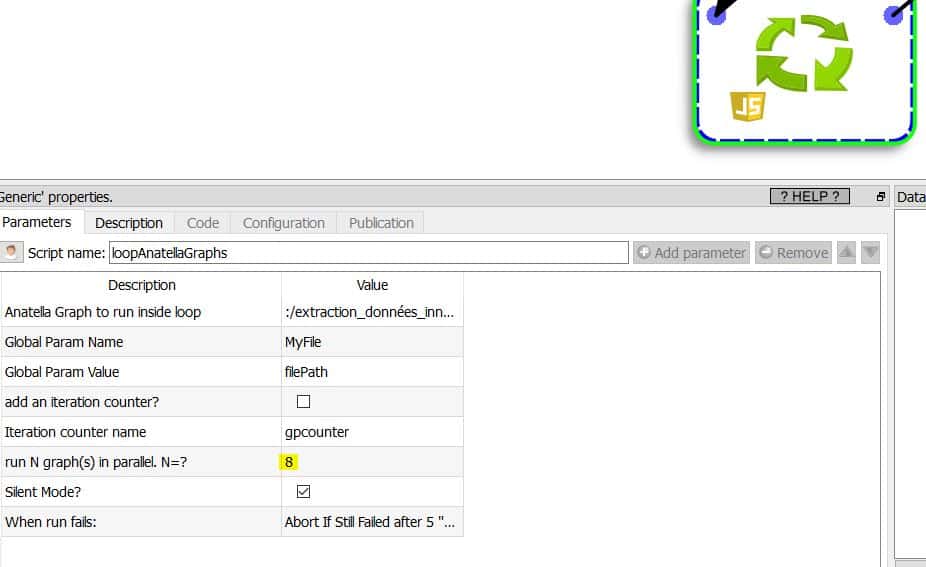
De tweede stap bestaat uit het maken van een lus die elke verwerkingsreeks van de Excel-bestanden zal oproepen en een reeks .gel-bestanden zal schrijven.
Tip: u kunt meerdere processen parallel laten lopen als je CPU meerdere cores heeft. Ik gebruik een i7 CPU met 8 cores, waardoor ik 8 processen parallel kan laten lopen. De verwerkingstijd voor het hele proces is 4,31 seconden in plaats van ongeveer 32 seconden. De winst is aanzienlijk. Bij de uitvoer heb ik alleen een Excel-bestand nodig (ik had ook een .hyper-bestand kunnen kiezen).

Conclusie
Dankzij Anatella heb ik een gegevensextractie kunnen automatiseren die me anders uren gekost zou hebben. Een ander belangrijk voordeel is dat dit geautomatiseerde proces duurzaam is en mij in staat zal stellen om, als de Excel-sjablonen in de toekomst niet veranderen, de nieuwe bestanden op te nemen en mijn weergaven automatisch bij te werken.




