
Voici le problème auquel j’ai été confronté récemment. Un client m’a demandé de traiter des données qui provenaient de centaines de fichiers Excel. Franchement je n’avais pas envie de passer des heures à extraire manuellement ces données. Alors j’ai automatisé le processus grâce à Anatella et ai visualisé les données sous Tableau par la suite. Voici un petit tuto de data preparation et une bonne manière de traiter vos données plus efficacement avec un ETL digne de ce nom.
Si vous n’avez que 30 secondes
- en utilisant Anatella j’ai pu automatiser un processus d’extraction de données à partir de fichiers Excel
- cela m’a permis de rendre rapide et pérenne un processus qui auparavant était fastidieux et susceptible de produire des erreurs dues aux traitements manuels
- la méthode utilisée se base sur une boucle lançant des traitements sur des fichiers Excel se trouvant dans un dossier défini
- un fichier consolidé est produit en sortie que je peux utiliser dans Tableau
Description du problème
Le problème auquel j’ai été confronté est relativement courant. Dans le cadre d’un projet qui m’a été confié par le Parlement, on m’a demandé de produire des statistiques sur l’emploi des personnes handicapées dans l’administration publique.
Chaque commune est tenue de remplir, une fois par an, un fichier Excel de type « template » en y documentant toute une série d’indicateurs : nombre d’ETP, sexe, salaires de référence, nombre d’emplois confiés à des personnes handicapées … La bonne nouvelle c’est que les administrations en question respectent bien le template et inscrivent les informations au bon endroit. Le problème, c’est que les templates ne sont pas toujours complets, que certains manquent et qu’il y a beaucoup de fichiers. Il faut donc s’y reprendre à plusieurs fois avant d’avoir des données consolidées.
La première solution aurait été de traiter chaque fichier individuellement après avoir corrigé les erreurs qui s’y trouvaient. C’est long et pas pérenne. J’aurais été bon pour recommencer chaque année. Surtout, cela aurait impliqué de multiples allers-retours avec l’Administration centrale pour récupérer, un à un les fichiers au fur et à mesure de leur envoi. J’aurais été fortement ralenti.
La bonne approche c’est de créer un « pipeline » d’extraction et de structuration des données. Ce script tourne automatiquement et me permet de remettre à jour, sans efforts, mon jeu de données d’une part, et mes visualisations sous Tableau d’autre part. Voici comme j’ai approché le problème avec Anatella.
Solution
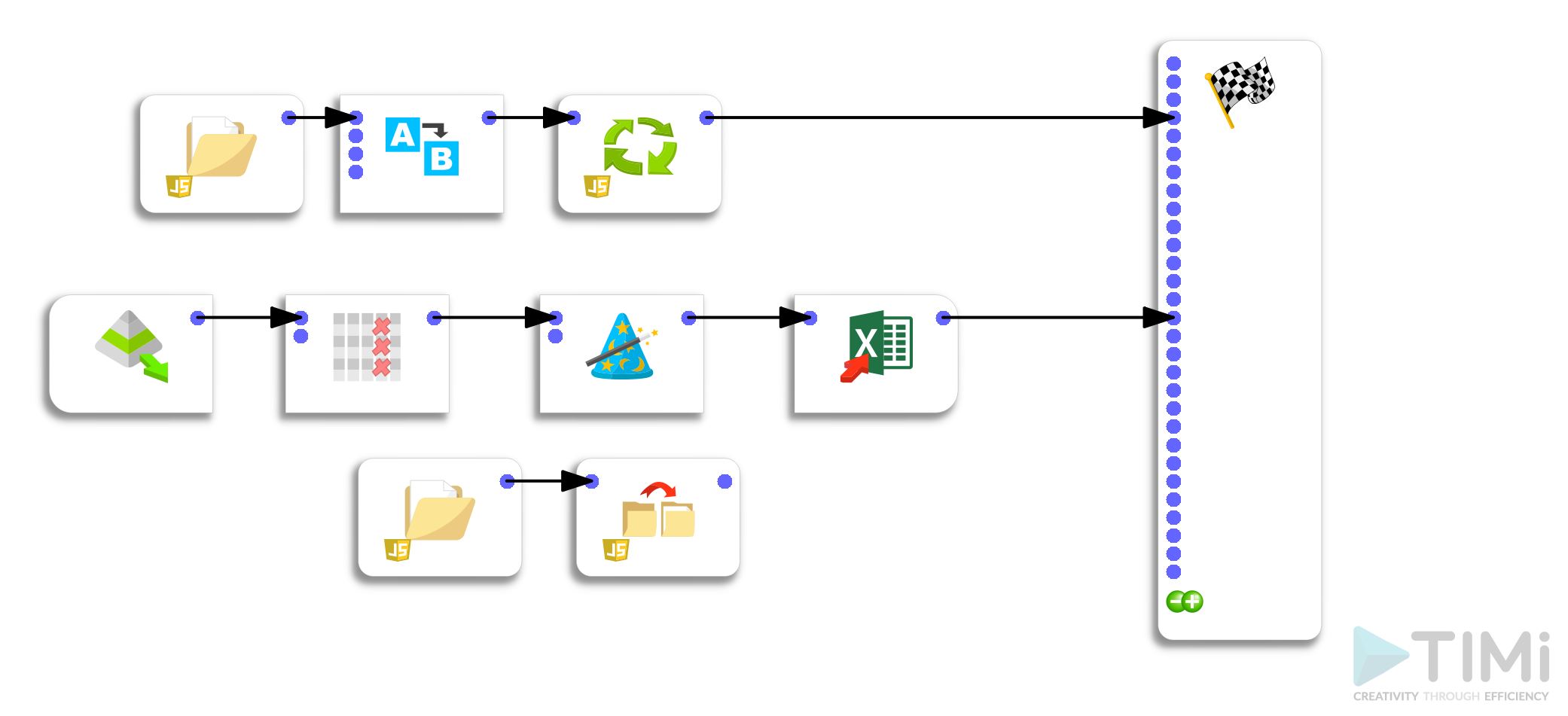
La solution mise au point se décompose en deux grandes étapes :
- un pipeline pour extraire les données de chaque fichier et les restructurer
- un pipeline pour traiter à la volée tous les fichiers se trouvant dans un dossier déterminé
Etape 1 : extraction des données du fichier et Excel et remise en forme
La 1ère étape consiste donc à extraire les informations de certaines cellules des fichiers Excel. Pour ce faire j’utilise un opérateur ternaire.
La fonctionnalité (très pratique) « unflatten » me permet ensuite de structurer toutes les données sur une seule et même ligne, jetant les bases du format de fichier nécessaire à Tableau.
Pour finir j’écris un fichier .gel dans le même dossier que celui où se trouve le fichier Excel.

Etape 2 : boucle de traitement des fichiers
La 2ème étape consiste à créer une boucle qui va appeler chaque séquence de traitement des fichiers Excel et qui va écrire une série de fichiers .gel.
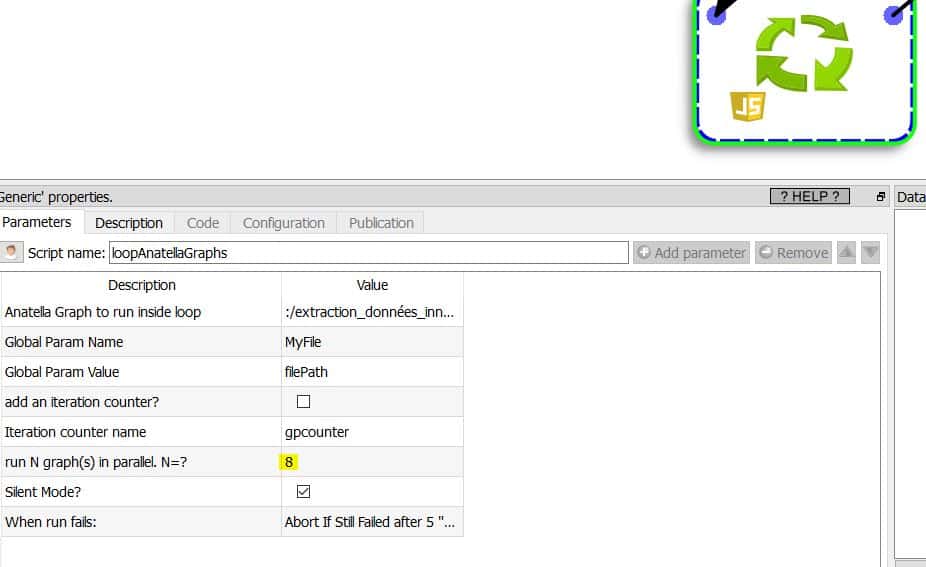
Petite astuce : vous pouvez faire tourner plusieurs process en parallèle si votre CPU dispose de plusieurs cœurs. J’utilise un CPU i7 à 8 cœurs ce qui me permet de faire tourner 8 processus en parallèle. Le temps de traitement pour l’ensemble du process tome à 4,31 secondes au lieu de 32 secondes environ. Le gain est appréciable. En sortie je me contente d’un fichier Excel (j’aurais pu aussi choisir un fichier .hyper).

Conclusion
Grâce à Anatella j’ai pu automatiser une extraction de données qui, autrement, m’aurait pris des heures. Autre avantage important, ce processus automatisé est pérenne et permettra, si les templates Excel ne changent pas dans le futur, d’ingérer les nouveaux fichiers et de mettre à jour automatiquement mes visualisations.




